¡Esta es una revisión vieja del documento!
Tabla de Contenidos
Creación de imágenes
Notas pertenecientes al curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
Hasta ahora has aprendido qué es Docker y cómo gestionar tus imágenes y contenedores usando la CLI. Es importante que te sientas cómodo con los comandos de Docker que hemos visto ya que los usaremos constantemente a lo largo de los módulos restantes.
En este módulo vamos a ver cómo crear nuestras propias imágenes de Docker, algunos aspectos importantes a tener en cuenta al hacerlo y cómo trabajar con un repositorio de imágenes. En concreto hablaremos de:
- Las características de una imagen de Docker
- El fichero
Dockerfiley sus comandos más importantes - Trabajar con volúmenes
- Qué son las etiquetas (tags) de las imágenes y cómo funcionan
- Los comandos
pullypushpara trabajar con repositorios
Creación de imágenes: el fichero Dockerfile
Para crear imágenes Docker se necesita básicamente un solo fichero: el Dockerfile.
Grosso modo podemos decir que el archivo Dockerfile contiene el conjunto de instrucciones que Docker sigue para crear una imagen. Es un fichero de texto donde cada línea del Dockerfile es una instrucción que Docker ejecuta para crear la imagen. Su nombre suele ser simplemente Dockerfile, sin extensión.
¿Qué contiene una imagen?
Una imagen de Docker contiene básicamente cuatro elementos:
- Un conjunto de archivos. Realmente, un “sistema de archivos” (filesystem) completo: tendremos archivos y directorios con sus correspondientes permisos de lectura y escritura.
- Un conjunto de puertos expuestos. La imagen declara que los contenedores abren unos determinados puertos al exterior. Recuerda que son “sus” puertos, no los puertos del host.
- Una configuración en forma de variables de entorno que van a estar en todos los contenedores creados a partir de dicha imagen.
- Un comando inicial que es el que ejecutará por defecto todos los contenedores creados a partir de esa imagen.
Todos los comandos de Dockerfile van orientados a especificar esos cuatro conceptos.
Imágenes base
Lo primero a tener presente cuando creamos una imagen es que muchas veces (la gran mayoría de veces) no queremos partir de cero. Imagina que tienes un programa desarrollado en Node.js y quieres empaquetarlo en una imagen Docker. Para que tu imagen sea funcional no te basta con tener tu código y los correspondientes paquetes npm instalados. También necesitas:
- El runtime de Node.js
- Cualquier dependencia del runtime de Node.js
- Cualquier dependencia de cualquier dependencia del runtime de Node.js…
- … Y así sucesivamente
No tiene sentido que tengas que configurar todo eso en cada imagen que crees; además, de que eso sería muy complejo. Es por ello que existe la idea de “imagen base”: tu imagen hereda de una imagen base, lo que significa que, partiendo de lo que hay en esta, la modificas para añadirle nuevos elementos.
Así, si tienes un programa escrito en Node.js y lo quieres empaquetar en Docker, lo suyo es partir de una imagen que tenga el runtime de Node.js: así ya sabes que Node.js está en la imagen, junto a todas sus dependencias.
El comando del Dockerfile que nos permite definir una imagen base es el comando FROM. Así, nuestro Dockerfile podría empezar de la siguiente manera:
FROM node
La sintaxis de FROM es muy sencilla: FROM nombre_imagen_base. En este caso la imagen base es la llamada node. Pero… ¿de dónde sacamos estas imágenes base?
Bueno, lo habitual es usar el “repositorio oficial de imágenes, DockerHub”. Este repositorio contiene muchas imágenes, verificadas por la propia Docker, que nos sirven de base para gran cantidad de casos. Puedes buscar una imagen y determinar si se trata de una versión oficial, verificada o de la comunidad, con las franjas que tienen a la derecha:
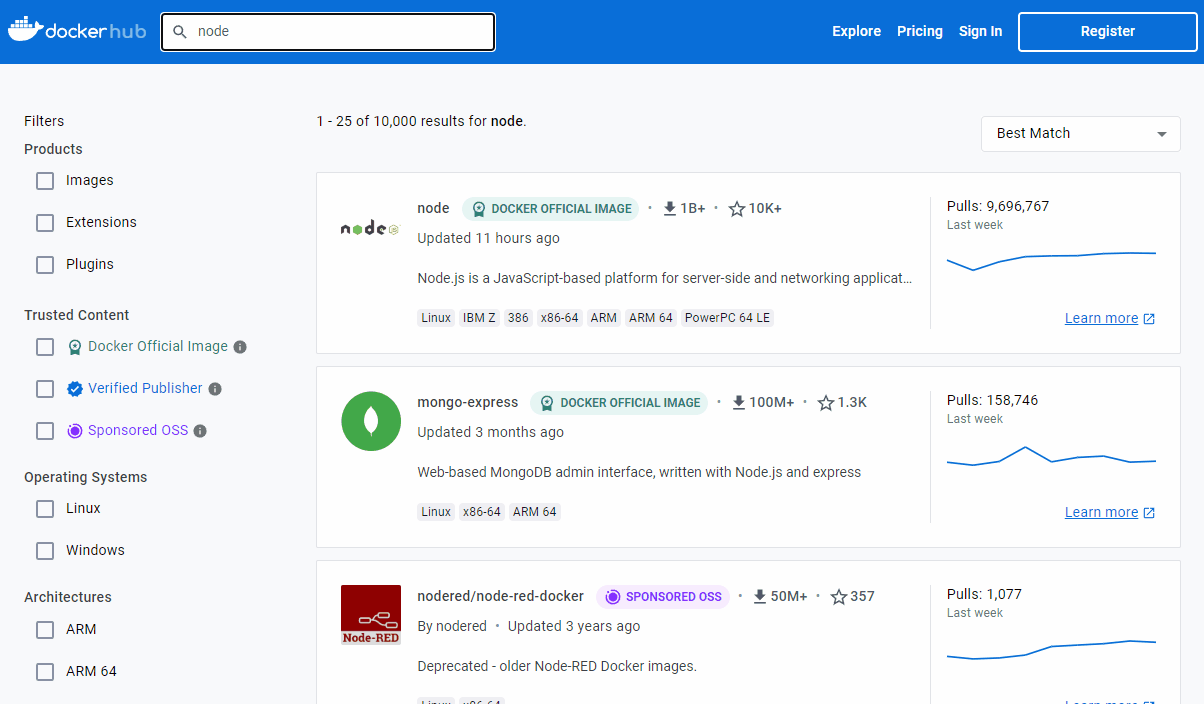
Como se puede apreciar en la imagen, las 3 imágenes que se ven son oficiales, lo cual quiere decir que han sido publicadas por Docker y se responsabilizan de ellas.
Desde el hub también puedes filtrar las imágenes por categoría. Puedes marcar las opciones del lateral para que tan solo te aparezcan imágenes oficiales o de publicadores verificados (en los que confía Docker), para mayor seguridad.
Por lo general preferirás imágenes que, o bien son oficiales o de terceras partes verificadas por Docker, así que las puedes considerar oficiales. Por otro lado, si encuentras una imagen “de la comunidad”, o sea, no verificada por Docker, no significa que no puedas usarla, pero no están verificadas por Docker y debes tener cuidado y ver cuán confiable es, porque podría ser cualquier cosa
Construyendo una imagen
La salida por pantalla de estos comandos depende de si tu instalación de Docker utiliza “BuildKit” (el sistema moderno de construcción de imágenes) o, por el contrario, utiliza el antiguo. Las versiones recientes de Docker tienen BuildKit habilitado por defecto, pero es posible deshabilitarlo, editando el fichero ~/.docker/daemon.json (%USERPROFILE%\.docker\daemon.json en Windows) y estableciendo la opción buildKit a false dentro de la sección features. Luego debes reiniciar Docker. Aunque lo normal es que estés usando BuildKit, quiero explicar ambos casos porque el comportamiento antiguo revela un concepto importante del funcionamiento de Docker, y creo que será positivo para el aprendizaje.
Una vez tienes un archivo Dockerfile puedes construir una imagen usando el comando build. Haz una prueba. Guarda el Dockerfile que tenemos (hasta el momento una sola línea). Ahora, desde línea de comandos, navega hacia donde tienes dicho Dockerfile y teclea:
docker build . -t myfirstimage
Con ese comando le indicamos a Docker que cree una imagen llamada myfirstimage a partir del contenido del Dockerfile y usando el directorio actual como “contexto de build” (hablaremos de dicho contexto más adelante).
Verás una serie de cadenas de hash y mensajes tales como “Transferring” y “Exporting”… Como parte de construcción de la imagen, Docker se descarga la imagen base y, a su vez, las imágenes base de esta. Al final, tendrás una salida parecida a la siguiente (algunos mensajes pueden cambiar, no le des importancia):
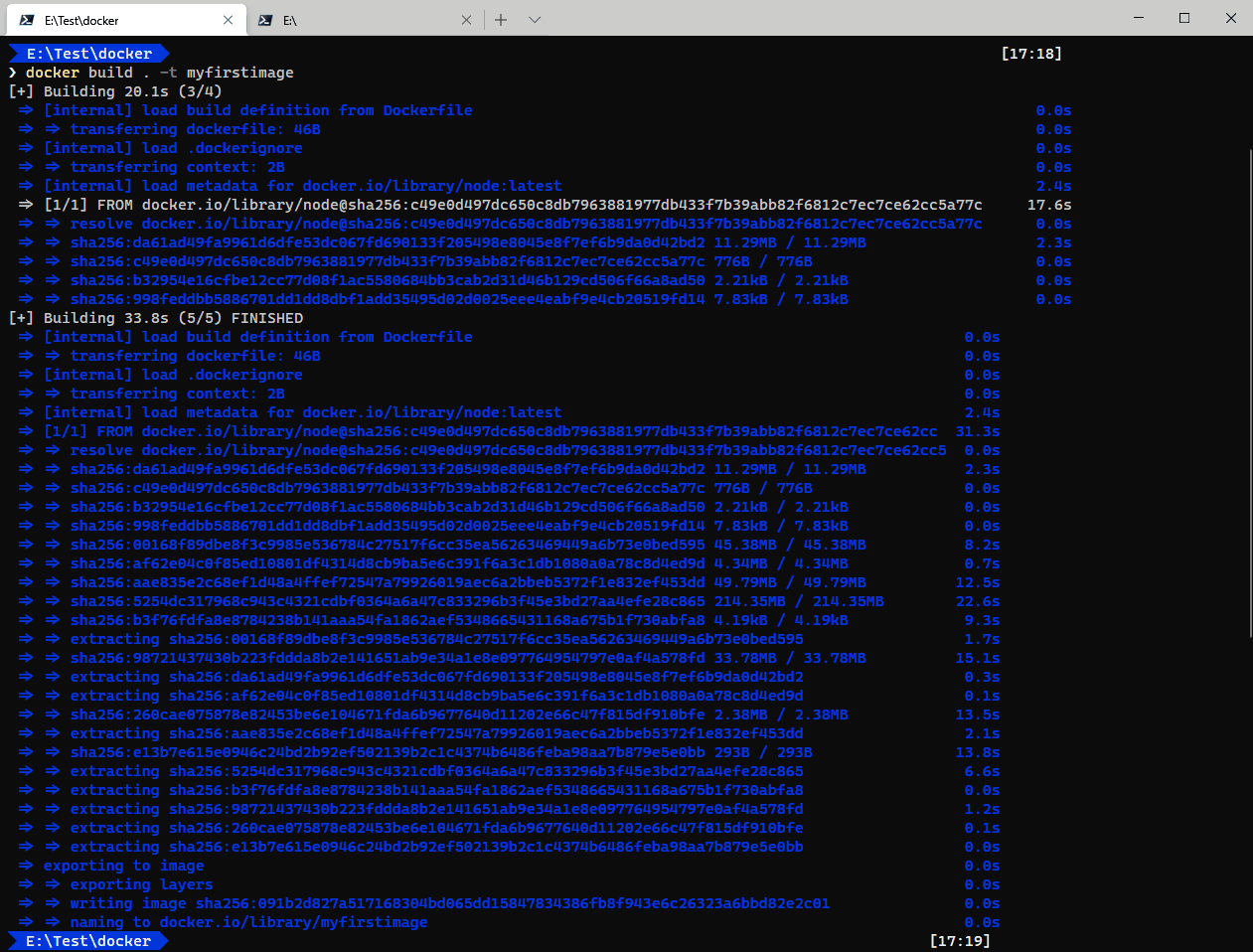
La captura de pantalla anterior muestra la salida de docker build cuando se usa una versión de Docker que tenga habilitado BuildKit (recuerda que cualquier versión reciente lo tiene ya activado). Si usas una versión más antigua de Docker, o bien tienes BuildKit deshabilitado, la salida será parecida a la siguiente:
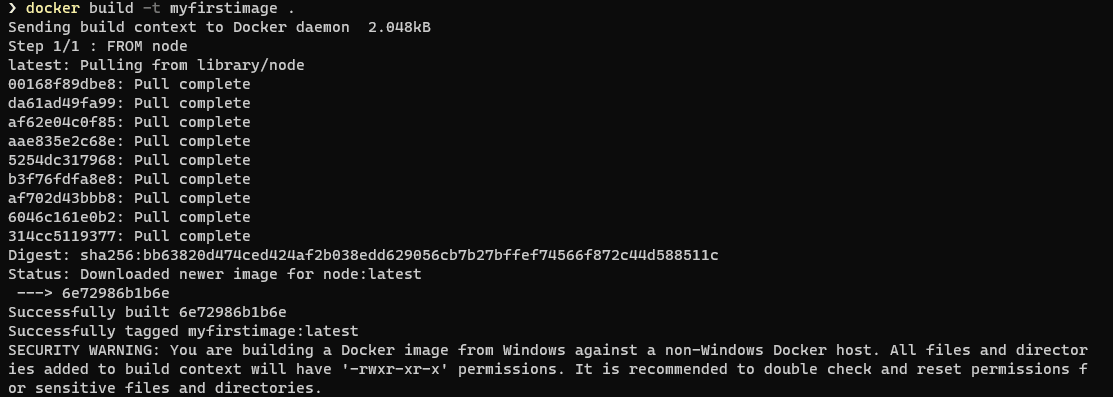
El aviso de seguridad (SECURITY WARNING) que aparece al final se da solo si construyes imágenes Linux usando un ordenador Windows y lo puedes obviar.
Bien, una vez construida la imagen, si ahora obtienes un listado de las imágenes que tienes en tu sistema (recuerda: docker images) obtendrás una salida distinta en función de si usas BuildKit o no.
Si usas BuildKit (que es lo habitual) la salida será parecida a:
REPOSITORY TAG IMAGE ID CREATED SIZE myfirstimage latest 7e6991800b08 16 hours ago 936MB
Por supuesto, puedes tener más imágenes además de las mostradas en estos listados. Pero te muestro las resultantes del build anterior.
Pero, si no usas BuildKit (porque estás en una versión antigua de Docker o porque, por cualquier motivo, lo has deshabilitado), entonces la salida será parecida a la siguiente:
REPOSITORY TAG IMAGE ID CREATED SIZE myfirstimage latest 6e72986b1b6e 16 hours ago 936MB node latest 6e72986b1b6e 16 hours ago 936MB
En el primer caso vemos que solo hay una imagen, myfirstimage. Pero en el segundo observamos que está también la imagen base (node) y, además, con el mismo identificador
Vamos a ver qué significa esto…
Imágenes "por capas" (layered images)
En el último listado anterior, el que no está hecho con BuildKit, verás que el id de ambas imágenes es el mismo, tanto para la imagen node como para la imagen myfirstimage. Recuerda que el id es el identificador que usamos para, entre otras cosas, borrar una imagen. El motivo es que, para Docker, la imagen de node y la imagen myfirstimage son la misma imagen.
Dado que BuildKit, por simplicidad, nos oculta ciertos aspectos que considero importante entender, esta parte de la lección va a mostrar la salida que se genera con BuildKit desactivado. Una vez tengamos claros los conceptos que deseo introducir, mostraremos qué cambios introduce BuildKit al respecto.
¿Cómo es esto posible si nosotros hemos creado una imagen nueva a partir de un Dockerfile?
Bien, nuestro Dockerfile tan solo tenía una instrucción FROM que indicaba que su imagen base era node. Dado que no hacemos nada más con la imagen, en la práctica, nuestra imagen es la misma que node y por eso, el resultado es que tenemos dos imágenes con el mismo id… o dicho más correctamente: una misma imagen con dos nombres distintos.
Es absolutamente posible y normal tener una misma imagen con nombres distintos (más adelante veremos que, de hecho, eso es a veces imprescindible).
Añadamos ahora algo nuevo a nuestro Dockerfile y observemos qué es lo que ocurre.
Vamos a usar la instrucción ENV en el Dockerfile. Dicha instrucción sirve para definir variables de entorno. La sintaxis de ENV es muy sencilla: ENV variable=valor.
También es válido utilizar ENV variable valor, sin el igual. Esto es así por compatibilidad con versiones antiguas de Docker, y te lo cuento porque es muy probable que lo veas utilizado por ahí, pero es mejor evitarlo.
Definamos, pues, una variable de entorno en nuestro archivo Dockerfile y a ver qué ocurre. Para ello añade una nueva línea para que quede así:
FROM node ENV foo=bar
Lo que hemos hecho es declarar una variable de entorno llamada foo que tendrá el valor de bar. Eso ocurrirá para todos los contenedores que se creen a partir de dicha imagen.
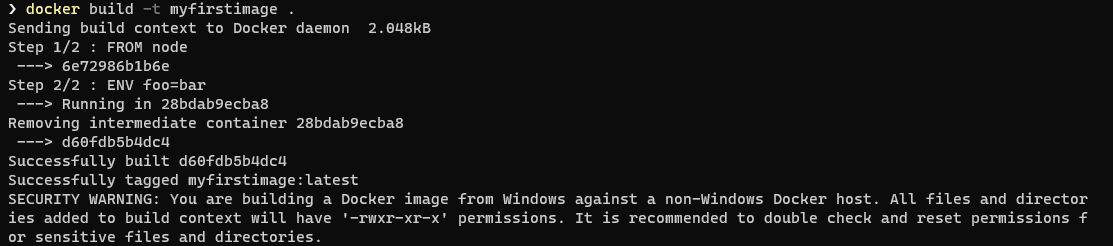
Una vez tengas el nuevo Dockerfile, crea de nuevo la imagen, con el mismo nombre, usando la instrucción docker build . -t myfirstimage. En este caso la salida que verás puede ser algo parecido a lo siguiente:
Y si ahora miras las imágenes que tienes, verás que ahora los ids son distintos:
REPOSITORY TAG IMAGE ID CREATED SIZE myfirstimage latest d60fdb5b4dc4 About a minute ago 936MB node latest 6e72986b1b6e 16 hours ago 936MB
¿Cuánto ocupa realmente en disco una imagen?
Esta pregunta no es baladí y su respuesta nos llevará a entender mejor cómo funcionan las imágenes en Docker.
Observa que en el listado anterior ambas imágenes tienen el mismo tamaño (936MB). Es algo lógico, ya que la imagen myfirstimage parte de la imagen node, así que ocupará como mínimo lo mismo.
Ahora bien, ¿eso significa que esas dos imágenes ocupan 1872MB (936×2) en disco? La realidad es que no. En disco tenemos ocupados aproximadamente… 936MB.
La razón es que Docker usa un sistema de “capas” para montar una imagen. Tenemos que entender que cada instrucción del Dockerfile añade una capa adicional sobre la imagen base, y que la imagen final es la “superposición” de todas esas capas. Docker intenta reaprovechar las capas siempre que puede.
¡Este es un concepto muy importante!
La instrucción FROM define la imagen base o la primera capa. En nuestro caso, dicha capa es la imagen node (id 6e72986b1b6e) y tiene un tamaño de 936MB. La segunda capa es la creada por la instrucción ENV y esta capa se monta encima de la primera. El tamaño de esta capa es de 0 bytes (lo único que hace es definir una variable de entorno).
Por lo tanto, en lo que respecta a Docker lo que tenemos es:
- Una imagen
6e72986b1b6e(node) con un tamaño de 936MB - Una imagen
d60fdb5b4dc4(myfirstimage) que consta de dos capas:- Capa 1: la imagen
6e72986b1b6e - Capa 2: el resultado de
ENV
Cuando Docker crea contenedores a partir de la imagen d60fdb5b4dc4 monta las nuevas capas una encima de otra, así que, no se necesita que la capa 6e72986b1b6e esté dos veces físicamente en disco. Docker es muy eficiente en cuanto al uso de tamaño de disco.
De hecho, cuando hemos dicho que la imagen d60fdb5b4dc4 constaba de dos capas, eso no es del todo cierto. Podemos ver todas las capas que tiene una imagen a partir del comando docker history.
Así, si tecleamos docker history myfirstimage la salida será parecida a la siguiente:
IMAGE CREATED CREATED BY SIZE COMMENT d60fdb5b4dc4 3 minutes ago /bin/sh -c #(nop) ENV foo=bar 0B 6e72986b1b6e 16 hours ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 16 hours ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 16 hours ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 16 hours ago /bin/sh -c set -ex && for key in 6A010… 7.76MB <missing> 16 hours ago /bin/sh -c #(nop) ENV YARN_VERSION=1.22.5 0B <missing> 16 hours ago /bin/sh -c ARCH= && dpkgArch="$(dpkg --print… 93MB <missing> 16 hours ago /bin/sh -c #(nop) ENV NODE_VERSION=15.14.0 0B <missing> 8 days ago /bin/sh -c groupadd --gid 1000 node && use… 333kB <missing> 8 days ago /bin/sh -c set -ex; apt-get update; apt-ge… 561MB <missing> 8 days ago /bin/sh -c apt-get update && apt-get install… 141MB <missing> 8 days ago /bin/sh -c set -ex; if ! command -v gpg > /… 7.82MB <missing> 8 days ago /bin/sh -c set -eux; apt-get update; apt-g… 24.1MB <missing> 8 days ago /bin/sh -c #(nop) CMD ["bash"] 0B <missing> 8 days ago /bin/sh -c #(nop) ADD file:e52290391b221e1a4… 101MB
La columna IMAGE nos muestra cada una de las capas de la imagen y su tamaño asociado.
Observa que la columna que nos muestra las capas se llama realmente IMAGE. Eso es porque históricamente en Docker una imagen y una capa eran conceptos sinónimos. Pero, a partir de Docker 1.10 se introdujo un cambio fundamental y actualmente imágenes y capas no son exactamente lo mismo. Así que, a partir de Docker 1.10 dicha columna solo muestra el id de las imágenes (no de las capas) y dicho id se muestra asociado a la última capa de cada imagen que tengamos. El resto aparece como <missing>.
Así, es importante que entendamos que la fila superior, cuyo id en nuestro ejemplo es d60fdb5b4dc4, nos indica que tenemos una imagen cuya última capa es la indicada en esta fila. Pero este id no es el id de la capa. Es el de la imagen.
Exportando imágenes en disco
Es posible exportar una imagen de Docker en un fichero (en formato tar) y al abrirlo nos quedará todavía más claro el concepto de capas. Para exportar una imagen de Docker a un fichero el comando a usar es docker save:
docker save myfirstimage -o myfirstimage.tar
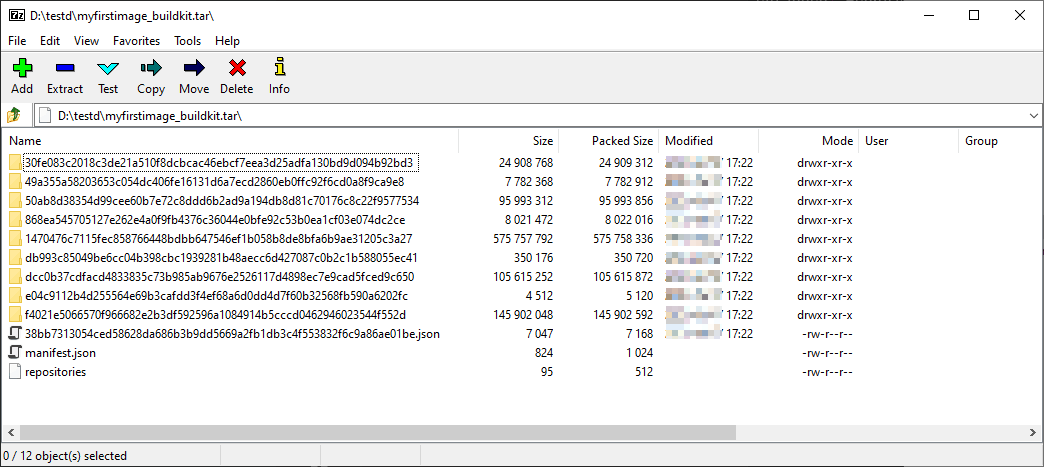
Este comando exporta la imagen myfirstimage al fichero myfirstimage.tar, ahora podemos abrir ese fichero con cualquier editor que soporte el formato tar y ver sus contenidos. En mi caso yo he usado esa pequeña maravilla llamada 7-Zip:
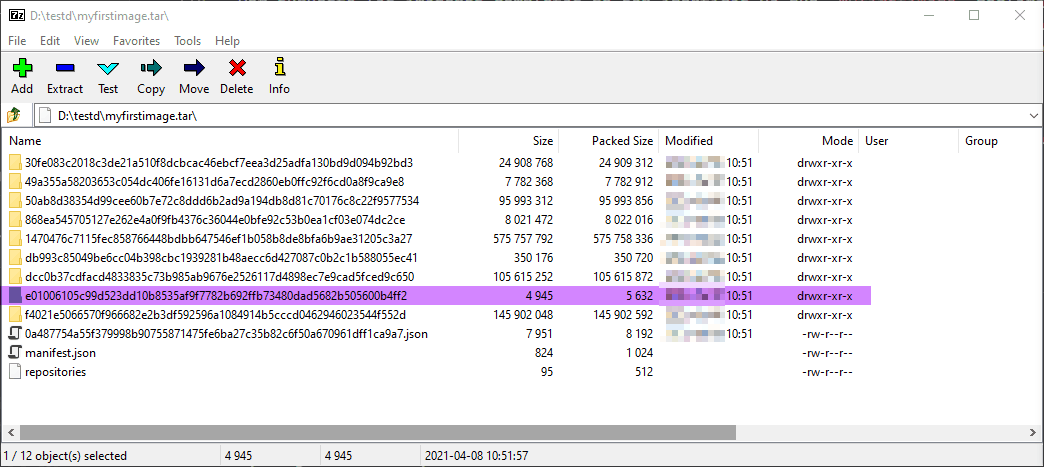
Esta imagen nos muestra el contenido del fichero tar, que es el resultado de exportar la imagen myfirstimage. Lo interesante es que tienes un montón de carpetas con varios identificadores: esas carpetas contienen las capas reales de la imagen.
Vamos a ver qué tenemos si exportamos la imagen base de node. Para ello ejecuta el comando:
docker save node -o node.tar
Y al igual que antes lo abrimos con 7-Zip para ver su contenido:
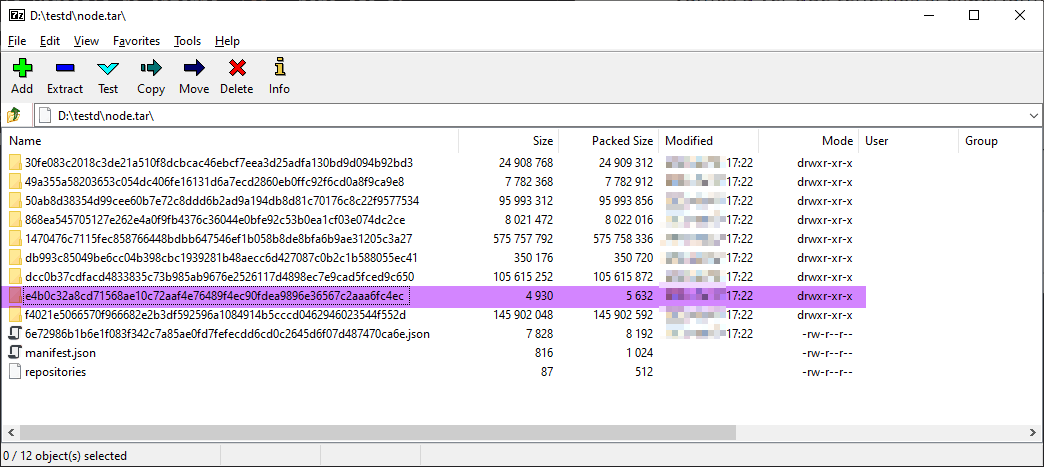
Observa ¡como casi todas las carpetas son idénticas! Esto tiene sentido porque el contenido del sistema de ficheros de ambas imágenes es el mismo (en nuestro Dockerfile solo hemos declarado una variable de entorno). Se ha resaltado en ambas capturas la única carpeta que es distinta. Esta carpeta resaltada se corresponde a la última capa de la imagen y contiene, entre otras cosas, las variables de entorno y otros metadatos, de ahí que sea diferente.
Luego existen otras diferencias en los ficheros .json de la raíz del fichero tar, que contienen metadatos adicionales de la imagen (observa como el nombre y el tamaño de dicho fichero son distintos en ambos casos).
Pero, volviendo al espacio real ocupado en disco, lo que Docker guarda son esas carpetas con las distintas capas de ficheros, por lo que si una misma capa se utiliza en varias imágenes, en realidad se encuentra físicamente una sola vez en disco.
Imágenes por capas con BuildKit y dangling images
Bien, lo que hemos visto en la lección anterior era con BuildKit deshabilitado. Si usas BuildKit los conceptos son los mismos, pero como BuildKit nos oculta cierta información, se hace más complejo de explicar. Pero, ahora que ya sabes lo que hay por debajo, vamos a ver cómo es la salida en cada caso usando BuildKit.
Recuerda que, a diferencia del caso anterior, con BuildKit la imagen base (node) no aparece en el listado de imágenes:
REPOSITORY TAG IMAGE ID CREATED SIZE myfirstimage latest 7e6991800b08 16 hours ago 936MB
Vamos a hacer el mismo cambio que en la lección anterior y añadimos la sentencia ENV al Dockerfile:
FROM node ENV foo=bar
Si ahora lanzamos el comando docker build para construir la imagen, la salida será parecida a la siguiente:
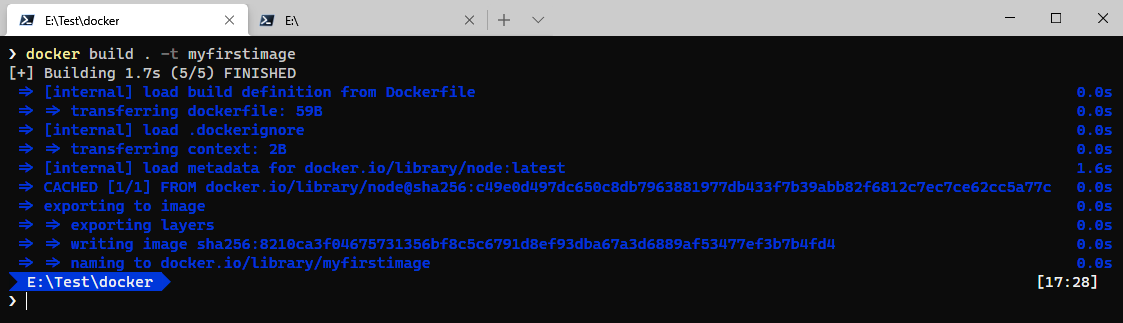
Y ¿qué imágenes tenemos ahora? Pues bien, el comando docker images nos da una salida como la siguiente:
REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> 7e6991800b08 16 hours ago 936MB myfirstimage latest 38bb7313054c 16 hours ago 936MB
La imagen base (node) sigue sin aparecer, pero ahora nos muestra otra imagen llamada <none>. ¿Qué está ocurriendo aquí?
Imágenes colgantes (//dangling images//)
Si el comando docker images te muestra una imagen <none>:<none>, generalmente eso significa que tenemos una imagen “colgante”, o como verás más a menudo, en inglés, una dangling image. Se trata de imágenes que ya no están referenciadas (utilizadas) por ninguna otra imagen, por lo que pueden (y deben) ser eliminadas, básicamente porque ocupan espacio en disco.
Estas imágenes colgantes aparecen habitualmente al construir nuevas versiones de una imagen propia. Por ejemplo, tienes un Dockerfile y construyes una versión (usando docker build). Posteriormente realizas cualquier modificación y vuelves a usar el mismo comando docker build sin cambiar el nombre o el tag. En este caso, la nueva imagen generada reemplazará a la antigua (pues tienen el mismo nombre y tag) y la antigua quedará como dangling image.
¡Ojo!: no todas las imágenes <none>:<none> son imágenes “colgantes”. Luego veremos otro caso en el que, aun estando marcadas así, no lo son. De hecho, lo son solo aquellas que te aparecen cuando usas docker images sin ningún otro parámetro. Pero, si quieres tener la seguridad, las puedes listar explícitamente con el filtro docker images -f dangling=true:
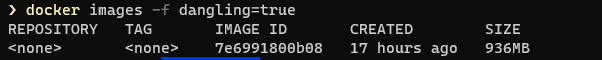
Es recomendable eliminar las imágenes colgantes cada cierto tiempo, ya que Docker no lo hará por ti.
Para eliminarlas lo más sencillo es usar bash o PowerShell (no cmd.exe) si estás en Windows, con el siguiente comando:
docker rmi $(docker images -f "dangling=true" -q)
O utilizar el comando docker image prune, que hace exactamente lo mismo.
El comando docker image prune -a borraría además todas las imágenes que tengamos que no tengan contenedores asociados. Consulta https://docs.docker.com/config/pruning/1la documentación de prune.
El motivo de que haya aparecido esa imagen colgante es que hemos modificado el Dockerfile y hemos reconstruido la imagen, pero hemos utilizado el mismo nombre y la misma etiqueta de la imagen previa. Sin embargo, la imagen previa sigue existiendo, ya que BuildKit no la elimina, solo que ahora no tiene nombre ni etiqueta: es una imagen colgante.
Este comportamiento es nuevo de BuildKit. El “antiguo” docker build borraba la imagen anterior. Personalmente me parece un buen comportamiento: permite volver a la imagen anterior en cualquier momento si así se desea. Claro que, lo ideal sería que Docker tuviese un sistema de recolección de imágenes colgantes cada cierto tiempo, pero por ahora no es así: debes ir borrándolas tú.
Eso nos deja claro una de las características fundamentales de las imágenes en Docker: son inmutables. Una vez creada una imagen no se puede modificar. Puedes crear otra que tenga el mismo nombre y etiqueta, pero será otra imagen, con otro ID.
Imágenes intermedias
Como hemos dicho antes, no todas las imágenes <none>:<none> son imágenes colgantes, algunas de ellas son imágenes intermedias. Esas no aparecen listadas con docker images y debe usarse docker images -a para verlas.
Dependiendo de la versión de Docker que uses, puedes tener más o menos de esas imágenes, pero no te preocupes por ellas: en ningún caso suponen un problema, ya que contienen capas intermedias que son usadas por otras imágenes, así que no debes eliminarlas.
Capas en BuildKit
A todo eso, estábamos en que habíamos construido la imagen myfirstimage con el Dockerfile que tenía la sentencia ENV, lo que nos ha generado la imagen con el id 38bb7313054c. Vamos a exportar, con docker save dicha imagen a un fichero tar para analizarla:
docker save myfirstimage -o myfirstimage_buildkit.tar
Si comparas esa captura del contenido del fichero myfirstimage_buildkit.tar con el del fichero myfirstimage.tar que generamos con la versión anterior, verás que las carpetas son idénticas. Esto tiene sentido: BuildKit sigue usando las capas y esas capas siguen siendo las mismas. Lo único que no hace BuildKit es guardar la imagen base (node), cosa que sí hacía el antiguo docker build. Pero, en lo que respecta al contenido en disco, pocos cambios hay: Docker guarda las capas del mismo modo.
Ese cambio se refleja en la salida del comando docker history que es ligeramente distinto:
IMAGE CREATED CREATED BY SIZE COMMENT 38bb7313054c 17 hours ago ENV foo=bar 0B buildkit.dockerfile.v0 <missing> 17 hours ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 17 hours ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 17 hours ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 17 hours ago /bin/sh -c set -ex && for key in 6A010… 7.76MB <missing> 17 hours ago /bin/sh -c #(nop) ENV YARN_VERSION=1.22.5 0B <missing> 17 hours ago /bin/sh -c ARCH= && dpkgArch="$(dpkg --print… 93MB <missing> 17 hours ago /bin/sh -c #(nop) ENV NODE_VERSION=15.14.0 0B <missing> 8 days ago /bin/sh -c groupadd --gid 1000 node && use… 333kB <missing> 8 days ago /bin/sh -c set -ex; apt-get update; apt-ge… 561MB <missing> 8 days ago /bin/sh -c apt-get update && apt-get install… 141MB <missing> 8 days ago /bin/sh -c set -ex; if ! command -v gpg > /… 7.82MB <missing> 8 days ago /bin/sh -c set -eux; apt-get update; apt-g… 24.1MB <missing> 8 days ago /bin/sh -c #(nop) CMD ["bash"] 0B <missing> 8 days ago /bin/sh -c #(nop) ADD file:e52290391b221e1a4… 101MB
La segunda capa (primera <missing> del listado), en el caso anterior tenía un ID en IMAGE, ya que efectivamente esa es la capa superior de la imagen de node y antes teníamos esa imagen en el disco. Pero ahora no la tenemos, ya que BuildKit no la guarda, de ahí que ahora nos aparezca como <missing>.
Capas e imágenes
Como se ha comentado, a partir de Docker 1.10, imágenes y capas ya no son sinónimos. Las capas se identifican mediante un id que es realmente un hash del contenido de la capa calculado mediante el algoritmo SHA256. Usar el hash como identificador garantiza que una capa siempre tendrá el mismo id mientras su contenido no cambie. Al cambiar su contenido, el hash también se modificará.
Así, ahora en Docker una imagen es básicamente un objeto de configuración que, entre otros datos, contiene todos los ids de todas las capas que conforman dicha imagen. Y el id de una imagen no es nada más que el hash (de nuevo SHA256) de dicho objeto. Por lo tanto:
- Cada capa tiene un id.
- El id de una capa es un hash que depende del contenido de dicha capa.
- Una imagen se compone de varias capas.
- Para Docker una imagen es un objeto de configuración que contiene, entre otras cosas, todos los ids de las capas que conforman esta imagen.
- El id de la imagen es un hash calculado a partir de los datos de dicho objeto de configuración.
Por lo tanto, el id de una imagen depende (entre otras cosas) de los ids de sus capas.
Cómo obtener los ids de las capas
Es posible obtener los ids de todas las capas de una imagen. Para ello debemos usar el comando inspect. Dicho comando devuelve información sobre un objeto de Docker (puede ser una imagen, un contenedor u otro tipo de objeto). La salida es un JSON que puede ser relativamente grande. Por suerte podemos quedarnos solo con la parte que nos interesa especificándola con el parámetro --format:
PS> docker inspect --format @"
{{range .RootFS.Layers}}
{{.}}{{end}}
"@ myfirstimage
El parámetro --format en el fragmento anterior ocupa varias líneas por claridad. Si estás en Windows, usa PowerShell y cambia de línea usando Shift + Enter.
Este comando nos mostrará todos los ids de las distintas capas que conforman la imagen:
sha256:18f9b4e2e1bcd5abe381a557c44cba379884c88f6049564f58fd8c10ab5733df sha256:d70ce8b0dad684a9e2294b64afa06b8848db950c109cde60cb543bf16d5093c9 sha256:ecd70829ec3d4a56a3eca79cec39d5ab3e4d404bf057ea74cf82682bb965e119 sha256:7381522c58b0db7134590fdcbc3b648865325f638427f69a474adc22e6b918af sha256:bfa30f97c0f427f1cda8f3192cc25c7a4729ec28269ae8f5241c7366738e3ca5 sha256:1d13cfbbfeb2fae5b521d38447ba69ba61c36b9b07f37ded51be7856e127c9a7 sha256:dd258e4bb89d7385af12f3b0ec0fed35992ed467c5b2f5684a95a9cab4b1d06d sha256:9c9366531e84e3ac9db451bda6c240ea82e52c3bb71eb0d59e49d18a6089703f
Ahora bien, si comparas el número de capas que nos aparecen usando docker inspect con el número que nos aparece usando docker history, verás que es distinto. En nuestro caso, history nos muestra 15 capas, mientras que inspect tan solo nos muestra 8 capas. ¿Por qué esa diferencia?
La razón viene por cómo se calcula el id de una capa: es un hash del contenido (ficheros) de dicha capa. Por lo tanto, si tenemos una capa que no modifica el sistema de ficheros, su id será el mismo que el de la capa anterior.
Usando inspect vemos solo los distintos ids, mientras que usando history tenemos todas las capas. Por lo tanto, de las 15 capas reales que conforman la imagen myfirstimage tenemos 8 capas que modifican el sistema de archivos del contenedor y 7 capas que realizan tareas de configuración (por ejemplo, añadir variables de entorno).
De hecho, si vuelves a mirar la salida de history, verás que hay 7 capas cuyo campo SIZE vale 0B: esas son las 7 capas que no modifican el sistema de ficheros y, por lo tanto, el id de cada una de esas capas es igual al id de la capa anterior. Por otro lado, las capas que tienen un tamaño mayor a 0 (y si las cuentas verás que son ocho) son las que modifican el sistema de ficheros de la imagen y, por lo tanto, tienen un id propio.
Obtener el id completo de la imagen
Hemos comentado que el id de una imagen es un hash (SHA256) calculado a partir del contenido del objeto de configuración que describe la imagen. Pero, hasta ahora todos los ids de imágenes que hemos visto son mucho más cortos. Eso es, simplemente, porque Docker no nos muestra el id completo. Así, cuando hacemos docker images o cualquier otro comando que nos muestre ids de imágenes vemos los ids abreviados.
Para obtenerlo, disponemos de dos opciones sencillas. La primera es usar docker images --no-trunc. El modificador --no-trunc le indica a Docker que queremos ver los ids completos:
REPOSITORY TAG IMAGE ID CREATED SIZE myfirstimage latest sha256:f7c89b3c7fa9884ac3e77715899ba7d9089ebbd76990a76a3538228b782b0096 4 hours ago 673MB node latest sha256:9ea1c3e33a0b643018428df8b675d623dd6b67315bc60c69c7fe43efea9a177d 15 hours ago 673MB
Otra es usar el comando inspect y extraer el id de la imagen:
docker inspect --format "{{.Id}}" myfirstimage
La salida de este comando es el id completo de la imagen.
Añadir contenido a una imagen
Vamos a continuar con nuestra imagen y vamos a añadirle contenido propio.
Hasta ahora hemos partido de una imagen base (usando FROM) y hemos añadido una configuración (usando ENV). Veamos ahora cómo podemos añadir contenido a la imagen. En aras de la sencillez vamos a usar un ejemplo en Node.js. Luego comentaremos otros escenarios.
Creando una imagen de Node.js
Descarga desde el lateral de esta lección (o desde las descargas del curso) el fichero nodejs-sample.zip y descomprímelo en un directorio vacío. Este fichero contiene una sencilla aplicación en Node.js que levanta un servidor que escucha por un puerto (configurable) y que devuelve el contenido de una URL (dirección web) cualquiera que se le mande por parámetro.
Para ejecutar esta aplicación en local (olvídate de Docker de momento) necesitas lo siguiente:
- Tener Node.js instalado
- Tener nuestro código (obviamente)
- Ejecutar el comando npm install para instalar todas las dependencias (paquetes npm) que requiere la aplicación
- Establecer la variable de entorno
PORTque indica por qué puerto debe escuchar la aplicación (opcional) - Ejecutar
node server.jspara iniciar la aplicación
Si tienes Node.js y quieres probar el ejemplo en local, una vez hayas hecho npm install, ponlo en marcha mediante node server.js. Por defecto se usa el puerto 3000, aunque puedes establecer la variable de entorno PORT para elegir el puerto por el cual escuche la aplicación. Puedes llamar a /ping para obtener un pong como respuesta, o bien llamar a /get?url=xxx para mostrar el contenido de la url xxx por pantalla.
Por supuesto, puedes probar todas esas tareas en local si quieres, pero no es necesario. Lo importante es entender qué debes hacer porque es lo que debemos replicar en el Dockerfile.
Para empezar, crea un Dockerfile que parta de la imagen de Node.js:
FROM node
El siguiente punto es establecer un directorio en el que vamos a desplegar nuestra aplicación. Para ello se usa el comando WORKDIR. Asume que este comando es el equivalente a hacer cd dentro de la imagen. Su sintaxis es muy sencilla: WORKDIR directorio-imagen. Vamos a desplegar nuestra aplicación en el directorio /app:
FROM node WORKDIR /app
Ahora, el siguiente punto es copiar todos los ficheros que conforman nuestra aplicación al sistema de ficheros de la imagen:
FROM node WORKDIR /app COPY . .
El comando COPY copia un directorio local (de la máquina que está creando la imagen) a un directorio del contenedor. La sintaxis es COPY directorio-local directorio-contenedor. El “directorio-local” es relativo a la ubicación del Dockerfile y el “directorio-contenedor” es relativo al directorio especificado en el comando WORKDIR. Por lo tanto, con el comando COPY . . estamos copiando el contenido del directorio (y subdirectorios) donde está el Dockerfile al directorio /app del contenedor.
Existe una alternativa al comando COPY que es el comando ADD. El comando ADD usa la misma sintaxis que COPY (ADD origen directorio-contenedor), pero, a diferencia de COPY, el origen puede ser no solo un directorio local sino también una URL o un fichero comprimido (y lo descomprime en la imagen). La recomendación es usar COPY antes que ADD siempre que sea posible.
Una vez tenemos nuestro código en el sistema de archivos de la imagen podemos ejecutar npm install en la imagen. Quizá te suene raro eso de “ejecutar algo en la imagen”, pero ten presente que el proceso de construcción de una imagen se realiza a través de un contenedor, por lo que se pueden ejecutar comandos dentro de este. Y para eso tenemos la instrucción RUN del Dockerfile.
La sintaxis de RUN es muy sencilla: RUN comando para que (el contenedor que construye) la imagen ejecute un comando. En nuestro caso queremos ejecutar un npm install:
FROM node WORKDIR /app COPY . . RUN npm install
El comando npm install requiere el fichero package.json, que en este caso ya tenemos en el sistema de ficheros de la imagen porque lo hemos copiado en el punto anterior. Y podemos ejecutar npm porque la imagen base de la que partimos (la de node) contiene npm.
Finalmente, solo nos queda indicar cuál es el comando que debe ejecutarse cuando se inicie el contenedor (el mismo que debe ejecutarse en local). Para indicar el comando que se ejecuta al iniciar un contenedor existe la instrucción CMD. Como te puedes imaginar su sintaxis es muy sencilla: CMD comando_a_ajecutar:
FROM node WORKDIR /app COPY . . RUN npm install CMD node server.js
La diferencia entre RUN y CMD es que el primero se ejecuta durante la fase de construcción del contenedor a partir de la imagen, es decir, se ejecuta como parte del proceso que construye el nuevo contenedor. CMD, por el contrario, se ejecuta ya dentro del nuevo contenedor y es, generalmente, la última instrucción, destinada a lanzar el proceso que nos interese dentro del nuevo contenedor que se acaba de crear.
ENTRYPOINT o CMD
Hemos visto que para especificar el proceso inicial de un contenedor utilizamos CMD. Así, para que nuestro contenedor lance node server.js cuando se inicie, podemos usar:
CMD node server.js
Existe otra sentencia alternativa en Dockerfile que también te permite especificar un comando inicial. Se trata de ENTRYPOINT. Toda imagen necesita definir, o bien un valor para CMD, o bien para ENTRYPOINT; pero ¡es posible definir ambos!
Entender las diferencias entre CMD y ENTRYPOINT es fundamental.
Shell vs Exec
Antes de hablar de las diferencias entre ENTRYPOINT y CMD es interesante conocer que ambas instrucciones pueden aparecer con dos sintaxis distintas: la sintaxis que conocemos como shell y la que conocemos como exec.
Hasta ahora siempre hemos usado CMD en su forma shell (CMD node server.js). Pero también podríamos usar CMD en su forma exec:
CMD ["node", "server.js"]
Entre ambos formatos hay una diferencia importante: usando la forma shell el comando que especificamos se ejecuta dentro de un shell (de ahí su nombre); mientras que la forma exec lanza un nuevo proceso. En el caso de Linux se ejecuta el shell /bin/sh -c, y luego el comando que hayamos indicado nosotros.
Veámoslo con un ejemplo. Crea un Dockerfile con el siguiente contenido:
FROM alpine:3.7 CMD ping localhost
Partimos de la imagen base alpine:3.7 y el comando inicial es ping localhost (es un comando que nunca finaliza en Linux, así que nuestro contenedor estará corriendo hasta que lo paremos). Ahora crea una imagen con docker build -t test-cmd .
Una vez tengas la imagen creada, usa docker run -d test-cmd para crear un contenedor (en modo desatendido). Esto te imprimirá el id del contenedor y te devolverá el control. Ahora con docker ps deberías ver tu contenedor ejecutándose.
Ahora vamos a usar el comando docker exec. El comando docker exec ejecuta un proceso nuevo en un contenedor que esté en marcha. La sintaxis es:
docker exec <id-contenedor> comando
En nuestro caso queremos ejecutar el comando ps (usado en Linux para ver los procesos ejecutándose). Así pues teclea lo siguiente:
docker exec <id-contenedor> ps
(siendo <id-contenedor> el id de tu contenedor)
La salida será algo parecido a:
PID USER TIME COMMAND
1 root 0:00 /bin/sh -c ping localhost
6 root 0:00 ping localhost
7 root 0:00 ps
Observa como el comando inicial (PID 1) es /bin/sh -c ping localhost. Esto es porque hemos usado la forma shell.
En el caso de que uses contenedores Windows, al usar la forma shell se usa cmd /S /C en lugar de /bin/sh. No confundas el cmd de cmd /S /C con la instrucción CMD del Dockerfile. Este cmd se refiere a cmd.exe el intérprete de comandos de Windows.
Vamos a modificar el Dockerfile y cambiemos la última línea, para usar la forma exec de CMD:
FROM alpine:3.7 CMD ["ping","localhost"]
Y reconstruimos la imagen (para ello, antes, detén y borra el contenedor que acabas de crear, porque sino, Docker no podrá recrear la imagen). Una vez construida la imagen, pon en marcha otro contenedor y usa docker exec de nuevo para lanzar el comando ps en el contenedor. Y la salida será parecida a:
PID USER TIME COMMAND
1 root 0:00 ping localhost
7 root 0:00 ps
Como puedes ver ahora no se ha ejecutado /bin/sh -c para lanzar el comando indicado.
¿Cuál es la forma recomendada? Pues, por lo general la recomendación es usar la forma exec, no la shell. Hay dos razones fundamentales:
/bin/sh -cno propaga señales POSIX al proceso hijo. Eso tiene implicaciones en cómo Docker detiene nuestro contenedor, ya que la señalSIGTERMque Docker envía para detenerlo, no llegará nunca a nuestro proceso.- No todas las distros Linux tienen por qué tener un shell. Por lo que
/bin/shpuede no estar disponible. Es cierto que esto todavía no es muy habitual pero, cada vez más, se crean imágenes llamadas “shell-less” que no tienen shell. Los motivos son, tanto por seguridad como por tamaño de la imagen.
Puedes usar la instrucción SHELL del Dockerfile para indicar cuál debe ser el shell a usar por defecto. El shell especificado usando SHELL se usará tanto para las instrucciones CMD y ENTRYPOINT (si se usan en su forma shell), y también para la instrucción RUN. Eso es especialmente interesante en contenedores Windows, en los que podemos querer usar Powershell como intérprete de comandos en lugar de cmd.exe. En este caso podemos hacer:
SHELL ["powershell", "-command"] RUN Write-Host "¡Puedo usar PS!"
La instrucción SHELL establece que el shell a usar será powershell -command, lo que permite usar instrucciones Powershell en el Dockerfile. Así mismo, si utilizases CMD o ENTRYPOINT en su forma shell, el comando se ejecutaría mediante Powershell.
En Linux no se suele usar tanto esta posibilidad, aunque también tiene su utilidad en aquellos casos en los que quieras emplear un shell alternativo a sh, como bash o zsh. Por supuesto, como es evidente, el shell que quieras utilizar (tanto en Windows como en Linux) debe existir previamente en la imagen.
La instrucción ENTRYPOINT
Hemos visto cómo funciona CMD y las diferencias entre usarla en su forma shell o en su forma exec. Es el momento de presentar ENTRYPOINT y ver en qué se diferencia de CMD.
Lo primero a tener presente es que si solo utilizas CMD o ENTRYPOINT (uno de los dos únicamente) no existen demasiadas diferencias entre ellos. El comportamiento será muy parecido.
De hecho, si modificas el Dockerfile para usar ENTRYPOINT en lugar de CMD observarás idéntico comportamiento:
- Usando
ENTRYPOINT ping localhostverás que el proceso inicial es/bin/sh -c ping localhost - Usando
ENTRYPOINT [“ping, “localhost”]verás que el proceso inicial esping localhost
Es decir, el mismo comportamiento que CMD.
La principal diferencia entre usar CMD o ENTRYPOINT estriba en la facilidad para modificar este valor que le proporcionamos a quien crea el contenedor (es decir, lo fácil que le resulta modificarlo a quien ejecuta docker run). Esto es porque la sintaxis de docker run permite redefinir tanto CMD como ENTRYPOINT:
docker run <imagen> comando docker run --entrypoint comando <imagen>
La primera sentencia redefine el valor de CMD, mientras que la segunda redefine el valor de ENTRYPOINT y requiere un parámetro adicional, que va antes del nombre de la imagen. Un poco más complicado.
En general la idea es que uses ENTRYPOINT para aquellas imágenes en las que no esperas que se vaya a modificar su proceso inicial. Mientras que CMD se suele utilizar más en aquellas imágenes en las que es relativamente normal que quien lanza el contenedor correspondiente modifique el proceso inicial.
ENTRYPOINT y CMD a la vez
Toda imagen debe definir o bien ENTRYPOINT o bien CMD, pero no son exclusivos: es posible definir ambos de forma simultánea. En ese caso, cuando ambos están definidos, el comportamiento es el siguiente:
ENTRYPOINT: es el que determina el proceso inicialCMD: el contenido deCMDse emplea como si fueran los parámetros paraENTRYPOINT… aunque solo siENTRYPOINTse usa en su forma exec. SiENTRYPOINTse usa en su forma shell entonces se hace caso omiso deCMD.
Vamos a verlo en acción. No es necesario que crees una imagen con CMD y ENTRYPOINT, vamos a pasar sus valores mediante docker run. Partiremos de la última imagen test-cmd que teníamos. Recuerda que el Dockerfile era:
FROM alpine:3.7 ENTRYPOINT ["ping", "localhost"]
La imagen pues no define CMD pero sí ENTRYPOINT. Ahora imagina que queremos usar esta imagen para lanzar cualquier otro comando en lugar de ping, como por ejemplo ifconfig. La sentencia más lógica sería:
docker run test-cmd ifconfig
Observa que estamos ejecutando el comando ifconfig existente en Linux. No lo confundas con el comando ipconfig (con p en lugar de la primera f) que existe en Windows
Pero esto no te funcionará. No te funcionará porque este docker run redefine el valor de CMD (que no teníamos), así que ahora este contenedor tiene:
ENTRYPOINTigual a “ping localhost” (le viene de la imagen)CMDigual a “ifconfig” (le viene del comandodocker run)
Por lo tanto, nuestro contenedor intentará ejecutar ping localhost ifconfig, lo que te dará un error.
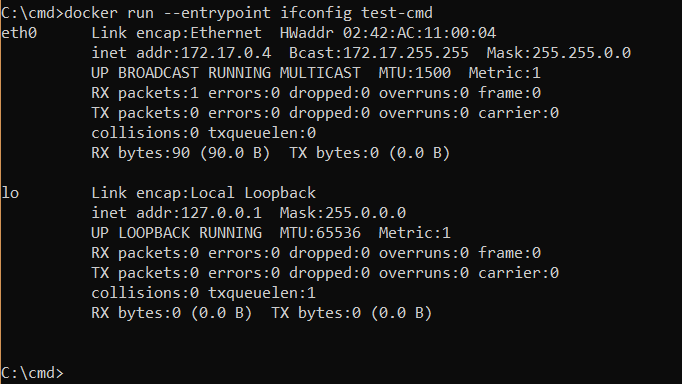
Ahora bien, si usamos el comando docker run –entrypoint ifconfig test-cmd lo que el contenedor recibe es:
ENTRYPOINTigual a “ifconfig” (del comandodocker run)CMDninguno
Por lo que este contenedor ejecutará el comando ifconfig:
Observa que ejecutar docker run --entrypoint ifconfig test-cmd es bastante menos intuitivo que usar docker run test-cmd ifconfig. Este es el comando que nos hubiera funcionado si en el Dockerfile hubiéramos usado CMD en lugar de ENTRYPOINT. De ahí la afirmación anterior donde indicaba que ENTRYPOINT se usa en aquellos casos en que “no es habitual” que se redefina el proceso de entrada de un contenedor.
Problemas al usar la forma shell
Hemos visto cómo combinar ENTRYPOINT y CMD. Pero ten presente que usar ENTRYPOINT y CMD a la vez solo te funcionará si usas la forma exec. Si usas la forma shell tendrás problemas. La razón es muy sencilla y es que el comando final generado puede ser inválido.
| ENTRYPOINT | CMD | Resultado final |
|---|---|---|
["ping, "localhost"] | -4 | ping localhost /bin/sh -4 |
ping localhost | -4 | /bin/sh -c 'ping localhost' |
ping localhost | ["-4"] | /bin/sh -c 'ping localhost' |
["ping, "localhost"] | ["-4"] | ping localhost -4 |
Observa como la única sentencia correcta es la última (ping localhost -4) que se da cuando tanto ENTRYPOINT como CMD están especificados usando la forma exec. Las filas segunda y tercera son también correctas, pero se ha hecho caso omiso del valor de CMD porque ENTRYPOINT está definido en su forma shell.
Cuando redefines ENTRYPOINT o CMD usando docker run es como si los definieses en el archivo en su forma exec.
Resumiendo:
- Utiliza preferiblemente
ENTRYPOINTantes queCMD(a no ser que pretendas que el usuario redefina fácilmente el comando) - Si
ENTRYPOINTyCMDaparecen a la vez, el segundo se toma como parámetros del primero - Usa mejor la forma exec antes que la forma shell. Especialmente usa siempre la forma exec de
ENTRYPOINT(a no ser que quieras expresamente que no se haga caso deCMD)
Exponer puertos
En el ejemplo que estamos usando hemos generado un Dockerfile para crear una imagen que nos permita levantar contenedores que ejecutan un servicio de Node.js. Dicho servicio escucha a través del puerto 3000, lo que significa que el contenedor abre su puerto 3000.
Sin embargo, si pones en marcha el contenedor y usas docker ps, verás que la columna PORTS está vacía:

Eso es debido a que no hemos indicado a Docker que los contenedores levantados a partir de dicha imagen pretenden abrir su puerto 3000. Para indicarle dicha intención a Docker, se puede usar la sentencia EXPOSE del Dockerfile. Su uso es muy simple: EXPOSE puerto, donde puerto es el número de puerto que nuestro contenedor pretende abrir (en nuestro ejemplo el 3000).
Si modificas el Dockerfile para añadir EXPOSE 3000 (p. ej. antes de la sentencia CMD), reconstruyes la imagen y lanzas de nuevo un contenedor, verás como, ahora, en la salida de docker ps la columna PORTS te indica que el contenedor expone el puerto 3000:

Es importante que tengas presente que EXPOSE es puramente informativo: indica la intención del contenedor de escuchar a través de dicho puerto. Pero, no significa forzosamente que este sea el puerto que de verdad abra el contenedor.
El uso de EXPOSE no tiene ningún impacto sobre la forma en la que Docker gestiona la red: no hace que dicho puerto esté disponible y el resto no, no abre dicho puerto por defecto (esto debe hacerlo el contenedor), ni tampoco mapea dicho puerto al host (eso debes seguir haciéndolo tú, usando el modificador -p de docker run).
Pero, es importante su uso porque documenta cuál (o cuáles si usas múltiples sentencias EXPOSE) son los puertos por los que se supone que el contenedor escucha.
Y, por supuesto, dado que EXPOSE es puramente informativo, el mapeo de puertos funciona, incluso, aunque no uses EXPOSE. Es decir, si la imagen no usa EXPOSE, pero tu contenedor abre el puerto 3000, si al usar docker run, mapeas el puerto 3000 del contenedor al puerto 8080 (o cualquier otro) del host, podrás acceder a tu contenedor usando dicho puerto.
Insisto: EXPOSE es solo con propósito informativo.
Un consejo: utiliza siempre EXPOSE en las imágenes que crees. La razón principal es para documentar y porque hay otras herramientas en el ecosistema de contenedores que pueden sacar partido a esta información.
El proceso de construcción de una imagen
En la sección anterior hemos comentado que “el proceso de construcción de una imagen se realiza a través de un contenedor”. Es importante que entiendas este concepto, así que vamos a desarrollarlo un poco.
Todo Dockerfile debe empezar por una sentencia FROM que especifique la imagen base a usar. Lo primero que Docker hace es crear un contenedor a partir de esa imagen. Cuando en nuestro Dockerfile teníamos FROM node, lo primero que hace Docker es descargarse la imagen node (si no la tenemos en local) y crear un contenedor a partir de esta imagen.
Será este contenedor recién creado el que ejecutará la siguiente instrucción del Dockerfile.
Veamos la salida que nos genera la instrucción docker build:
E:\nodejs-sample>docker build . -t nodejs-sample Sending build context to Docker daemon 28.16kB Step 1/5 : FROM node ---> 9ea1c3e33a0b Step 2/5 : WORKDIR /app ---> 88a4a86fa250 Removing intermediate container 73428d030cf1 Step 3/5 : COPY . . ---> dfae33d74efb Step 4/5 : RUN npm install ---> Running in 6138c2f87253 npm info it worked if it ends with ok **.... varias líneas de LOG de npm que se omiten ....** added 93 packages in 2.48s npm info ok ---> cf59b841c646 Removing intermediate container 6138c2f87253 Step 5/5 : CMD node server.js ---> Running in 1e6d20825950 ---> c69b88bc66c3 Removing intermediate container 1e6d20825950 Successfully built c69b88bc66c3 Successfully tagged nodejs-sample:latest
El proceso que sigue Docker para construir una imagen es el siguiente:
- Se crea una capa a partir de la imagen base (definida en el
FROM). En nuestro caso es la9ea. - Se crea un contenedor a partir de esa capa (que equivale a la imagen base). Dicho contenedor en nuestro caso es el
734. - Sobre ese contenedor ejecuta la siguiente sentencia del
Dockerfile(en nuestro ejemplo esWORKDIR app). El resultado se guarda como una capa (88a). - Si la siguiente instrucción del
Dockerfilees un ejecutable (por ejemplo,RUNoCMD) el contenedor anterior es desechado y se crea uno nuevo. Si no es el caso, se continúa usando el contenedor anterior.
De hecho, en este caso concreto se crean los siguientes contenedores:
- Contenedor
734. Creado a partir de la capa9ea(sentenciaFROM). Ejecuta también elWORKDIR(y genera la capa88a) y elCOPY(generando la capadfa). - Contenedor
613. Se crea para ejecutar elRUN npm install, generando la capacf5. - Contenedor
1ed. Se crea para ejecutar elCMD node server.jsgenerando la capac69.
Cada vez que se crea un nuevo contenedor durante el proceso, se desecha el anterior (observa los mensajes Removing intermediate container).
Recuerda que si ejecutamos docker history nodejs-sample podremos ver cada una de esas capas creadas.
En resumen: cuando ejecutamos un Dockerfile (para crear una imagen) Docker crea un contenedor temporal para ejecutar las sentencias del Dockerfile. Cada sentencia del Dockerfile genera una capa y es ejecutada en este contenedor creado por Docker. Algunas sentencias implican la creación de otro contenedor temporal, siendo el anterior desechado.
Variables de construcción
Es posible utilizar variables en el fichero Dockerfile. Para ello debes “declarar” la variable en el fichero Dockerfile usando la instrucción ARG:
ARG tag
El código anterior declara una variable llamada tag. Las variables declaradas con ARG son variables en tiempo de construcción de la imagen, es decir, la imagen construida no contendrá ninguna variable de entorno llamada tag (debes usar ENV para ello), sino que podemos usar esta variable tag a la hora de construir y su valor será sustituido:
ARG tag
FROM node:${tag}
Este ejemplo utiliza la variable de construcción tag para permitir decidir qué imagen base usar (en concreto qué tag de la imagen base node). Si guardas el código anterior en un fichero Dockerfile e intentas construirlo con el comando docker build -t testvars . la salida será parecida a:
Sending build context to Docker daemon 2.048kB
Step 1/2 : ARG tag
Step 2/2 : FROM node:${tag}
invalid reference format
Docker se queja de que la imagen node:${tag} no es una imagen válida. El error es debido a que la variable de construcción tag no tenía valor todavía. Para proporcionarle un valor usamos el modificador --build-arg:
docker build -t testvars --build-arg tag=8.11-alpine .
Ahora la imagen se construirá correctamente, tomando como imagen base node:8.11-alpine
Debes pasar explícitamente los valores de las variables de construcción usando --build-arg. Tener una variable de entorno con el mismo nombre declarada en tu sistema no funcionará.
Valores por defecto
Las variables de construcción pueden tener un valor por defecto. Este valor se establece en cada uso de la variable, es decir, el valor por defecto no se asigna a la variable, sino en cada sitio en el que se usa. Para ello se emplea la sintaxis $:{variable:-valor}:
ARG tag
FROM node:${tag:-8.11-alpine}
Si ahora no usas --build-arg para especificar un valor para la variable tag, la sentencia FROM usará el valor 8.11-alpine en su lugar. De este modo, aunque el que haga uso del archivo de construcción se olvide de establecerla, al menos tendrá un valor predeterminado que le permita funcionar.
Capas de escritura (writable layer)
Recuerda que una imagen de Docker está formada por un conjunto de capas. Esas capas son de solo lectura. Es decir, no puede modificarse el contenido de una capa, debe crearse una capa nueva (de hecho, recuerda que el id de una capa es un hash de los contenidos de esta). Eso permite a Docker reaprovechar capas entre imágenes (y por lo tanto contenedores) y es un aspecto fundamental de la eficiencia de la herramienta en cuanto a tamaño de disco requerido se refiere.
A continuación, descárgate la imagen ubuntu y crea un contenedor a partir de esa imagen iniciando una sesión interactiva (ejecutando bash). Si quieres refrescar la memoria sobre los comandos a usar, despliega el código a continuación:
docker pull ubuntu docker run -it ubuntu /bin/bash
Ahora debes tener una sesión interactiva con un contenedor. Vamos a crear un fichero en el contenedor, tecleando los siguientes comandos en la sesión interactiva que tenemos:
mkdir test cd test echo test file > test.txt
Eso debe crear un fichero test.txt en el contenedor con el contenido test file.
Ahora termina la sesión interactiva tecleando exit. Con eso deberías salir del contenedor y estar otra vez en tu sesión de terminal o línea de comandos. Además, si usas docker ps deberías ver que no hay ningún contenedor en marcha: al terminar con exit el proceso bash (que era el proceso inicial del contenedor) ha terminado también. Si tecleas docker ps -a, sí que verás el contenedor con el estado exited:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES df90d8320dcf ubuntu "/bin/bash" About a minute ago Exited (130) About a minute ago festive_noyce
Si ahora pones en marcha otro contenedor de la misma imagen, verás que el fichero test.txt que hemos creado antes no existe. Es lógico, puesto que el fichero lo hemos creado en el contenedor, no en la imagen.
Ahora bien, si reinicias el contenedor anterior sí que verás el fichero. Para verificarlo puedes teclear docker start -i <id> donde <id> es el id del contenedor (por ejemplo, en este caso sería df). Usamos el modificador -i para tener una sesión interactiva. Dado que el contenedor ejecutaba el comando bash vas a tener un shell interactivo. Si te vas al directorio test (cd test) y listas los ficheros (ls) allí verás el fichero test.txt.
El comando docker start no crea un contenedor nuevo, sino que reinicia uno que estaba parado.
Por lo tanto, la pregunta obvia es: ¿dónde está guardado este fichero? La respuesta, quizá como ya puedes intuir es: en una capa adicional.
Cuando se crea un contenedor, Docker monta sobre la última capa una capa adicional de escritura. Esa capa es única para el contenedor y contiene todos aquellos datos del sistema de ficheros que el contenedor modifique (creación de nuevos ficheros, modificaciones, borrados). Cuando el contenedor se borra, esta capa se borra también.
Tamaño ocupado por la capa de escritura
Si usas docker ps con el modificador -s puedes ver el tamaño que ocupa esta última capa:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE df90d8320dcf ubuntu "/bin/bash" 12 minutes ago Up 8 minutes festive_noyce 63B (virtual 122MB)
Observa que en la columna SIZE se indica que el contenedor ocupa 63B para un tamaño virtual de 122MB. Eso significa que el tamaño de la capa de escritura es de 63B (63 bytes). Y, que el tamaño del resto de capas suma 122MB. Pero, Docker interpreta que es un tamaño virtual porque esas capas son de solo lectura y, por lo tanto, pueden ser usadas en ese contenedor y en muchos otros más que estén en el sistema.
Así pues, el uso de capas de escritura le permite a Docker mantener su eficiencia en el uso de disco y, a la vez, posibilita que un contenedor pueda modificar sus datos. Pero, recuerda: los datos almacenados en la capa de escritura (que son todas las modificaciones al sistema de ficheros que dicho contenedor realice) existen solo para el contenedor al cual pertenece la capa de escritura. Las capas de escritura nunca se comparten.