¡Esta es una revisión vieja del documento!
Tabla de Contenidos
Introducción a Kubernetes
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
En este módulo vas a aprender los fundamentos de Kubernetes, también conocido como k8s. Estudiaremos:
- Qué es Kubernetes
- El modelo de aplicación de Kubernetes
- Cómo ejecutar Kubernetes en local
- Ejecutar un contenedor en Kubernetes
Para seguir esta sección del curso debes poder ejecutar un clúster de Kubernetes en tu máquina. Por suerte hay multitud de proyectos que te pueden ayudar a ello. Para este curso se ha elegido Minikube.
Minikube es un proyecto, de la propia gente de Kubernetes, destinado a facilitar la ejecución de un clúster de Kubernetes en tu máquina de desarrollo. Más adelante te comento cómo instalar y ejecutarlo y se trata de una forma muy sencilla de que puedas seguir todo el curso.
Pero, Minikube no es la única opción disponible, hay muchos proyectos orientados a facilitar la creación y ejecución de clústeres de Kubernetes locales. Aunque la mayoría de ejemplos funcionarán en cualquier sistema, nosotros hemos preparado todos los ejemplos para que funcionen en Minikube. Si usas algún otro sistema es posible que en algunos casos debas adaptar algo (durante el curso intento avisar en aquellos casos en que, a lo mejor, el ejemplo requiera adaptación si no usas Minikube).
Algunas de las otras opciones disponibles son:
¿Qué es un orquestador (de contenedores)?
Un orquestador es un sistema que se encarga de ejecutar nuestros contenedores y de ofrecer a estos un conjunto de funcionalidades avanzadas tales como:
- Escalado: un orquestador puede autoescalar nuestros contenedores creándolos y destruyéndolos según determinadas reglas de carga del sistema. Es cierto que con Compose podíamos escalar también, pero el escalado de Compose es fijo.
- Multimáquina: un orquestador puede ejecutar contenedores en más de una máquina a la vez, de forma coordinada. Incluso pueden “mover” contenedores de máquina si es necesario.
- Actualización de aplicaciones: suelen ofrecer mecanismos para actualizar las imágenes y configuración de nuestros contenedores de forma coordinada, sin paradas de servicio.
- Versiones “canary”: puedes tener simultáneamente más de una versión en producción, permitiéndote así probar la “siguiente versión” (sirviéndola solo a determinados usuarios).
- Métricas: ofrecen sistemas de métricas a nivel de contenedor, grupo de contenedores, máquina y orquestador.
- Gestión de errores: si un contenedor no responde a peticiones pueden terminarlo e iniciar otro nuevo en su lugar.
Puede parecer que los orquestadores solo ofrecen ventajas en escenarios multimáquina, pero incluso en escenarios con una sola máquina pueden existir ventajas por utilizar un orquestador frente a hacerlo mediante Compose.
Qué es Kubernetes
Kubernetes fue un proyecto creado por Google a partir de su experiencia previa en el uso de contenedores. Su origen es un proyecto llamado Borg, que era un sistema propio de Google para la ejecución de gran cantidad de servicios heterogéneos para distintas aplicaciones, ejecutados de forma distribuida en grandes clústeres de máquinas. Muchas de las ideas de Borg se incorporaron a Kubernetes, en tanto que gran parte de los desarrolladores de Kubernetes lo fueron de Borg.
Kubernetes fue anunciado por Google en 2014 y la versión 1.0 salió en 2015. En aquel momento Google se alió con la Linux Foundation para formar la Cloud Native Computing Foundation (CNCF) y Kubernetes pasó a estar dirigido y desarrollado por esta última. Actualmente es de código abierto y se ha convertido en el líder del mercado de orquestadores de contenedores.
Componentes de Kubernetes
A pesar de que nos referimos a él simplemente como Kubernetes (o k8s), la realidad es que no se trata de un solo producto, sino de la combinación de varios. La siguiente lista muestra componentes open source independientes de Kubernetes, pero que son utilizados en este:
- etcd: es una base de datos clave-valor distribuida que se utiliza para mantener el estado de todo el clúster.
- supervisord: se trata de un monitorizador de procesos. En Kubernetes se usa para garantizar que tanto el daemon de Docker como el propio “kubelet”, el nodo de tipo agente principal de Kubernetes (luego lo veremos), se están ejecutando.
- fluentd: es un sistema de logging unificado, que se usa en Kubernetes para centralizar todos los logs del clúster.
Además, existen varios componentes adicionales (kubelet, kube proxy, kube-controller manager y más) que forman parte de Kubernetes, pero que son más o menos independientes entre sí.
En este post de mi blog se detallan un poco más los componentes que conforman Kubernetes.
Nodos en Kubernetes
Todo clúster de k8s tiene dos tipos de nodos:
- Nodos master: no suelen ejecutar contenedores, sino que se encargan de todas las tareas de sincronización, coordinación y toma de decisiones que afectan al conjunto del clúster.
- Nodos minion (o worker): son los que se encargan de ejecutar los distintos contenedores.
El número mínimo de máquinas necesarias para montar Kubernetes es de uno (un clúster con un solo nodo). Kubernetes soporta clústeres de hasta 5000 nodos. Entre estos dos valores (1 y 5000) la cantidad de nodos será la que necesites.
El número mínimo de máquinas necesarias para montar un Kubernetes productivo de alta disponibilidad es de 5, tres de las cuales son nodos master y las dos restantes son nodos minion.
La creación de un nodo es algo externo a Kubernetes, generalmente lo crea el proveedor de cloud; o bien es una máquina física o virtual que tenemos, configuramos y agregamos al clúster. Lo que sí admite Kubernetes es agregar (o eliminar) máquinas a un clúster estando este en marcha.
Ver cómo desplegar un Kubernetes bare metal (es decir en máquinas, ya sean físicas o virtuales) está fuera del alcance de este curso. Si estás interesado, hay dos buenos recursos que puedes consultar: La documentación oficial y “Kubernetes The Hard Way”.
Una nota sobre el "no soporte a Docker" en Kubernetes 1.20
Hace cierto tiempo hubo una noticia que levantó bastante polvareda. Era algo similar a “Kubernetes dejará de soportar Docker a partir de la versión 1.20”. Aquí tienes la información oficial pero te pongo aquí el párrafo que importa:
Docker support in the kubelet is now deprecated and will be removed in a future release. The kubelet uses a module called “dockershim” which implements CRI support for Docker and it has seen maintenance issues in the Kubernetes community. We encourage you to evaluate moving to a container runtime that is a full-fledged implementation of CRI (v1alpha1 or v1 compliant) as they become available.
Esa noticia, que inicialmente se mencionó en un changelog rodeada de otros cambios que incorpora 1.20, enseguida fue amplificada por varios tweets y posts en blogs (algunos de ellos de colaboradores importantes de Kubernetes) que hicieron correr ríos de tinta, y se creó una alarma: ¿eso significa que los contenedores creados con Docker van a dejar de funcionar?
Mi respuesta a eso es muy sencilla: si te preocupas de que Kubernetes deje de soportar Docker como motor de contenedores entonces es que probablemente no te afecta. Porque para entender lo que implica realmente que Kubernetes deje de soportar Docker hay que comprender un poco la relación entre motores de contenedores y Kubernetes, y si la comprendes verás que los escenarios en que te puede afectar son pocos y relativamente avanzados (de forma que si los usas probablemente ya estarás manejando alternativas). Pero, resumiendo: que Kubernetes deje de soportar Docker no tiene (apenas) ninguna afectación.
En mi opinión, el pánico que generó esa noticia fue debido a una mala comunicación por parte del equipo de Kubernetes. Al final intentaron calmar las aguas con un post donde contaban las implicaciones pero, como pasa siempre en estos casos, la explicaciones suelen pasar más inadvertidas. Voy a intentar contarte en qué afecta que Kubernetes deje de soportar Docker sin entrar en demasiados tecnicismos (que algunos caen fuera del ámbito de este curso).
Cuando Kubernetes apareció, lo hizo con soporte para Docker, eso significa que hay código en Kubernetes para interactuar con el daemon de Docker para poner en marcha contenedores, pararlos, hacer pull de las imágenes, etc…
Poco tiempo después apareció un nuevo motor de contenedores, llamado rkt (lanzado por la gente de CoreOS (ahora Red Hat)) que parecía coger bastante tracción así que la gente de Kubernetes añadió soporte también a rkt en Kubernetes. Como nota a pie de página mencionar que rkt actualmente está deprecado y su uso ya no está recomendado.
Así que ahora la gente de Kubernetes tiene que soportar dos motores de contenedores, que son bastante distintos entre sí, pero con el tiempo sucedieron tres cosas más:
- Docker dejó de ser completamente monolítico para modularizarse
- La iniciativa OCI (Open Container Iniciative) empezó a tener calado
- Surgieron nuevos motores de ejecución de contenedores, aparte de Docker, para ejecutar imágenes OCI
Entonces, la gente de Kubernetes se lanzó a una refactorización con el objetivo de que Kubernetes dejara de requerir el daemon de Docker o rkt y que pudiese utilizar cualquier motor de ejecución de contenedores. Eso haría que, tener que instalar Docker o rkt en los nodos dejase de ser necesario y daría libertad al administrador de cada clúster a usar cualquier motor de contenedores. Para ello, crearon una interfaz (llamada CRI) mediante la cual Kubernetes se podía integrar con cualquier motor de ejecución de contenedores. Además simplificaba el código de Kubernetes ya que traspasaba la responsabilidad de interactuar con el motor de contenedores a cada módulo CRI. Así, el código de Kubernetes dependía solo de la interfaz CRI y cada administrador del clúster podía instalar su propio motor de contenedores siempre y cuando hubiese una implementación de CRI para dicho motor. Todo esto sucedió hace ya mucho tiempo, allá por finales del 2016.
Poco después lanzaron dockershim: una implementación de CRI para usar Docker. El dockershim era pues la idea que había en Kubernetes para seguir soportando Docker, pero haciéndolo a través de CRI y no de forma “directa” como hasta entonces, simplificando el código del core de Kubernetes.
Así fueron evolucionando las cosas, pero con el tiempo el mantenimiento del dockershim se fue volviendo cada vez más pesado. Empezó a verse que el dockershim era superfluo, ya que (como ya sabes) Docker usa containerd para ejecutar contenedores, y containerd empezó a soportar CRI. Es decir, Kubernetes podía usar containerd directamente. Por lo tanto, en este escenario… ¿qué sentido tiene que Kubernetes use Docker, quien a su vez usa containerd, si podía usar containerd directamente?
Recuerda que containerd es un proyecto de Docker y ¡que es el motor de ejecución que usa Docker realmente por debajo!
Pero, si eso por sí solo no fuese suficiente, otra iniciativa había ganado ya madurez: CRI-O. CRI-O es un motor de ejecución de contenedores OCI y compatible con CRI.
Así pues, el escenario es el siguiente:
- Docker genera (y ejecuta) imágenes OCI
- Docker usa containerd para ejecutar contenedores
- Kubernetes interacciona con el motor de contenedores a través de CRI
- El dockershim es una implementación CRI para Docker, pero es compleja de mantener
- Existe una implementación CRI para containerd
- El proyecto CRI-O es un motor de ejecución de contenedores OCI que soporta CRI
Por lo tanto, es bastante evidente que Kubernetes no necesita mantener el dockershim para nada: gracias al CRI de containerd o a CRI-O puede ejecutar cualquier contenedor OCI. Y recuerda que Docker crea y ejecuta contenedores OCI.
Es por ello que se tomó la decisión, en Kubernetes 1.20, de marcar el dockershim como obsoleto (y dejar de soportarlo totalmente en 1.23). Pero, ¿qué implicaciones reales tiene?
- ¿Podrás seguir ejecutando tus imágenes, generadas con
docker builden Kubernetes? Por supuesto, ya que Docker construye imágenes OCI que son las que ejecuta Kubernetes. - ¿Puedes seguir usando Docker en desarrollo? Por supuesto, sin ningún problema. Docker “no desaparece” ni se va a ningún lado.
- ¿Los nodos de Kubernetes deberán tener Docker instalado? No, en su lugar se podrá instalar containerd o bien CRI-O (o cualquier otro motor compatible con OCI y que tenga soporte CRI).
El último punto es el único que puede afectarte y se refiere a los escenarios avanzados que comentaba al principio. Básicamente, si ejecutas contenedores que requieren que Docker esté instalado en los nodos, porque hacen algo concreto con el daemon de Docker, entonces esto te afecta. Un caso típico es ejecutar un contenedor en Kubernetes que requiera a su vez construir otro contenedor. Lo más sencillo para hacer esto era enlazar este contenedor con el daemon de Docker del nodo de Kubernetes y ejecutar un docker build. Como puedes ver, ese es un escenario avanzado que va más allá de “ejecutar mis contenedores en Kubernetes”. Por eso comentaba al principio que si “te preguntas si eso te afecta, lo más probable es que no”, porque solo te afecta en esos casos avanzados, y en este momento probablemente ya tengas claro cómo Kubernetes ejecuta los contenedores y además ya conozcas alternativas a usar como pueden ser buildah o kaniko.
Así pues: tranquilidad. Puedes seguir usando Docker para crear y probar tus imágenes, y Kubernetes las podrá usar sin problemas 
Probar Kubernetes en local con Minikube
Existen varias maneras, relativamente sencillas, de usar Kubernetes en local, en tu máquina de desarrollo. Como hemos mencionado antes, hemos elegido MiniKube para este curso. Así, que vamos a ver cómo funciona y cómo instalarlo.
Para ejecutar Kubernetes en tu máquina local, Minikube puede hacerlo de dos maneras: la recomendada y más sencilla es ejecutar Kubernetes como un contenedor. Para ello el único requisito es que tengas Docker instalado en tu máquina. Pero, si no quieres o no puedes usar este mecanismo, Minikube soporta también el crear una máquina virtual que ejecutará Kubernetes.
Elijas la opción que elijas, Minikube va a intentar que el proceso sea lo más transparente para ti: toda la gestión se realiza a través del cliente de Minikube, que es una aplicación de línea de comandos.
En la página de MiniKube explican cómo instalarlo para tu sistema operativo (Linux, Windows o MacOS). Una vez lo tengas instalado debes ejecutar el comando minikube start. Lee la documentación del comando porque hay algunas configuraciones que quizás debas establecer, en función de tu SO y del sistema de virtualización que quieras que utilice MiniKube.
El primer paso es descargar el ejecutable de Minikube para tu SO, ya que toda la instalación y gestión se realiza desde ese ejecutable.
Instalando Minikube ejecutando el driver de Docker
Esta es la manera más sencilla de instalar Minikube. En este modo, Minikube ejecuta Kubernetes como un contenedor de Docker. Así se evita el uso de un sistema de virtualización adicional (como pueda ser Hyper-V o VirtualBox). Si tu sistema es compatible, Minikube intentará usar este modo de forma automática al usar el comando minikube start:
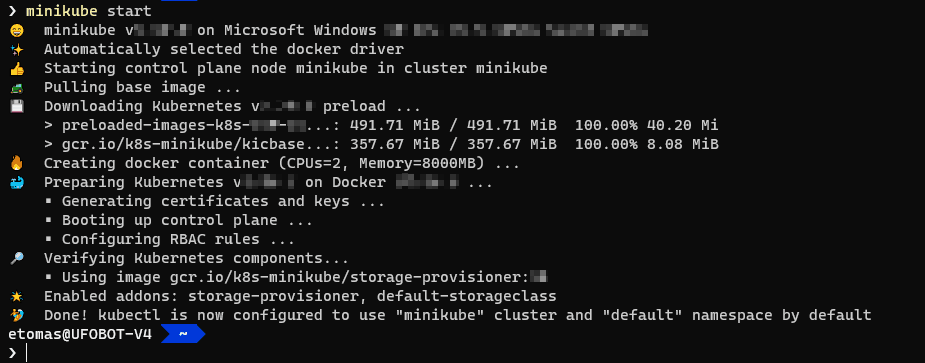
Consejo: a poco que puedas, insisto, utiliza este mecanismo. Es el más sencillo y el más liviano.
Una vez ejecutado el comando, ya tendrás tu Kubernetes de desarrollo listo y kubectl correctamente configurado. Puedes verificar que, efectivamente, Minikube ejecuta Kubernetes como un contenedor a través del comando docker ps:

En la imagen se puede ver como Docker nos muestra el contenedor de la imagen gcr.io/k8s-minikube ejecutándose. Este contenedor es Minikube.
No uses docker stop para parar el contenedor de Minikube, para ello debes usar minikube stop.
Usando Docker no necesitas para nada usar una consola administrativa en Windows, la cual sí es necesaria si usas Hyper-V
Instalando Minikube en Windows usando Hyper-V
A continuación se explica cómo instalar Minikube en Windows, usando Hyper-V. Si por cualquier motivo no es posible usar Docker, o bien prefieres usar una máquina virtual, usar Hyper-V es la opción más natural si estás en Windows.
Por temas de agilidad, voy a asumir cierta experiencia con Hyper-V. Aunque instalar Minikube no presenta dificultad, al final, si debes modificar alguna configuración de la MV creada, deberás hacerlo usando el administrador de Hyper-V.
Por ejemplo, en Windows yo uso el siguiente comando desde una consola administrativa:
minikube start --vm-driver hyperv --hyperv-virtual-switch "Default Switch"
Si no usas una consola administrativa recibirás un error de permisos:

Con vm-driver indicas a MiniKube que emplee Hyper-V para la MV. Y el modificador --hyperv-virtual-switch indica qué adaptador de red virtual debe usarse. En mi caso uso el “Default Switch” que viene preconfigurado con Hyper-V (a partir de Windows 1709).
Puedes agregar también el modificador --kubernetes-version <version-k8s> para instalar una versión concreta como, por ejemplo, --kubernetes-version v.1.12.4.
IMPORTANTE: Dificultades arrancando Minikube:
Es probable que te encuentres con problemas usando Minikube con Hyper-V. En su mayoría suelen ser problemas de red (no es posible conectar con el clúster) y pueden ser muy frustrantes.
En mi experiencia, a partir de Windows 1709 (o sea, a partir de la Fall Creators Update de Windows 10, que apareció en octubre del 2017) las cosas mejoran bastante usando el “Default Switch” que se ve en el comando anterior.
Si usas una versión de Windows 10 anterior a la 1709 (que ya tiene su tiempo y quizá no deberías), en el modificador --hyperv-virtual-switch debes indicarle el nombre de un adaptador externo de Hyper-V a utilizar. Si no usas este modificador, la MV terminará haciendo uso del primer adaptador que encuentre y eso te puede generar problemas. Así que te recomiendo que crees uno específico y lo uses (si estás en 1709 o posterior usa “Default Switch” tal y como se muestra en el ejemplo).
Si usas un adaptador que no es correcto, MiniKube te dará error diciendo que no puede conectarse a la MV vía SSH, o se quedará mucho rato con el mensaje “Starting VM…”.
Si el adaptador no te funciona, termina MiniKube (Ctrl + Ctrl), y desde el administrador de Hyper-V selecciona la MV y cámbiale a mano el adaptador de red virtual. Luego ejecuta simplemente minikube start sin ningún otro parámetro.
Otra opción es borrar Minikube con minikube stop y luego minikube delete y empezar de nuevo.
Si esto también te da problemas, entonces lo mejor es eliminar el directorio .minikube de tu perfil de usuario de Windows, borrar la MV de Hyper-V y volver a empezar de nuevo.
Si todo ha funcionado correctamente, la salida del comando debe ser parecida a la siguiente:
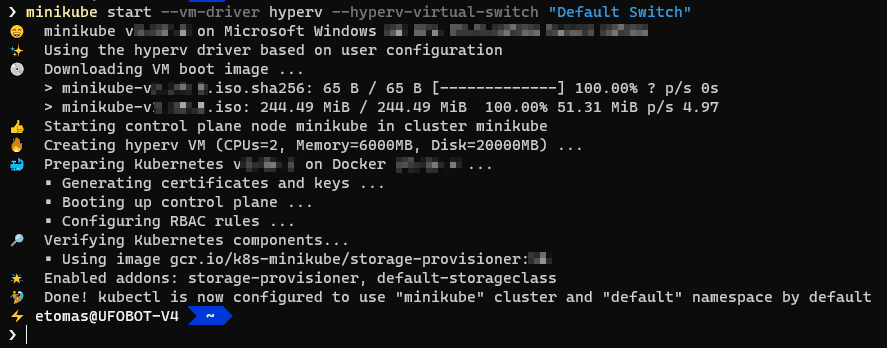
Si abres el administrador de Hyper-V deberías ver la MV minikube:

¡Perfecto! Tenemos un clúster de Kubernetes en local.
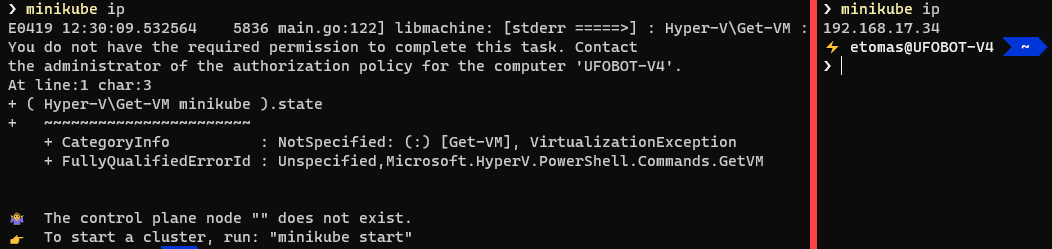
Para usar MiniKube con Hyper-V debes hacerlo siempre desde una consola con permisos administrativos, ya que de otro modo te dará problemas. En esta imagen la consola de la derecha es administrativa y el comando minikube ip funciona sin problemas. La primera consola (la de la izquierda) no lo es y se puede ver como el mismo comando da error.
Instalar Minikube en Linux
El escenario en Linux es muy parecido al de Windows, lo más habitual es usar el driver de Docker que ejecuta Minikube como un contenedor Docker:
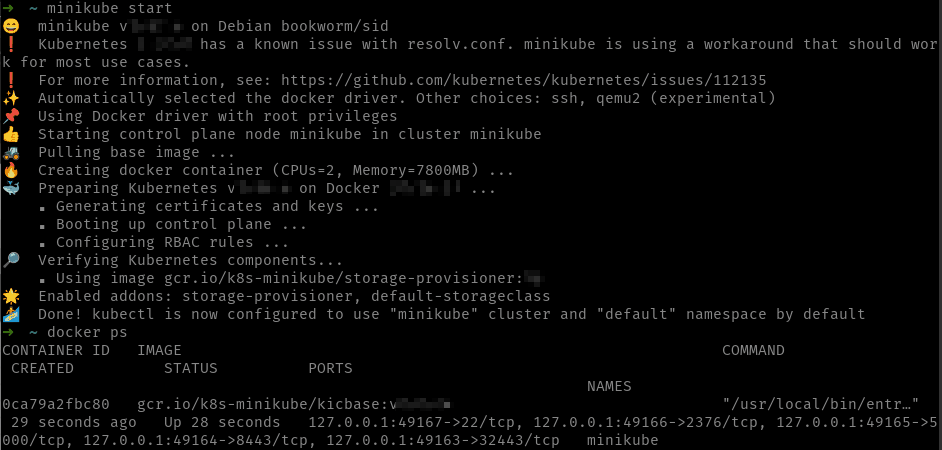
Como puedes ver en la imagen MiniKube, por defecto, utiliza el driver de Docker (observa el contenedor llamado minikube que aparece en el comando docker ps).
Otra opción bastante habitual es ejecutar Minikube usando VirtualBox a través del modificador --driver=virtualbox del comando minikube start. En su momento, usar VirtualBox era la opción preferida y por defecto de Minikube en Linux, pero en la actualidad usar Docker o KVM2 son las opciones preferidas.
Si tienes VirtualBox instalado, abre un terminal y teclea simplemente minikube start –driver=virtualbox y eso te instalará la MV en VirtualBox. La salida del comando es parecida a la siguiente:
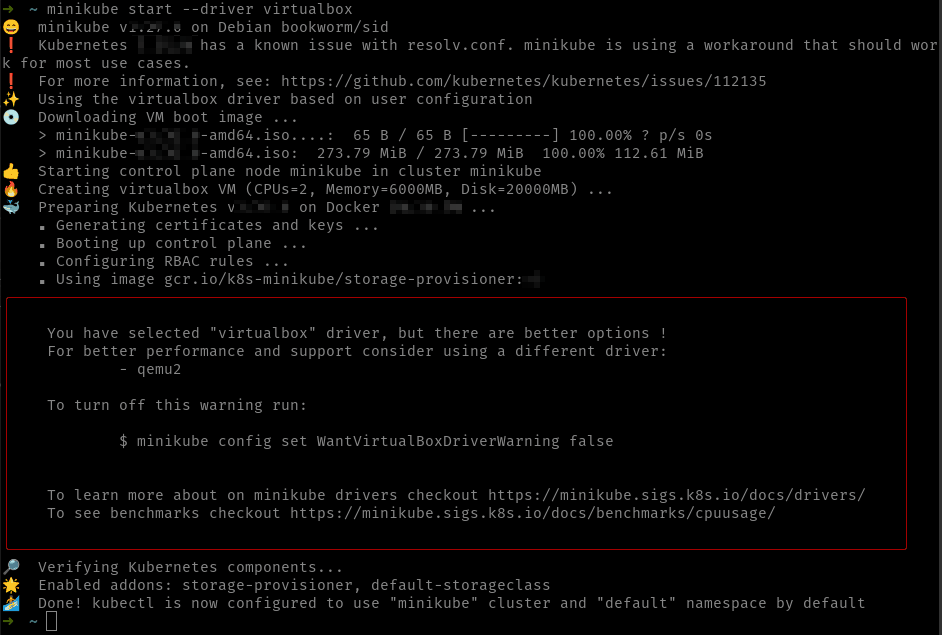
Observa como el propio Minikube nos indica que hay mejores opciones antes que utilizar VirtualBox. Y es que, aunque hace algún tiempo fue la forma recomendada, actualmente existen formas mejores de hacerlo, como usar KVM, que veremos a continuación
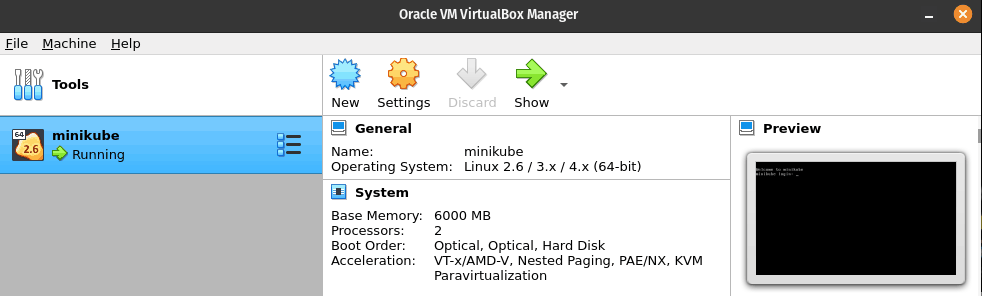
Si abres VirtualBox deberías ver la MV “minikube” creada y ejecutándose:
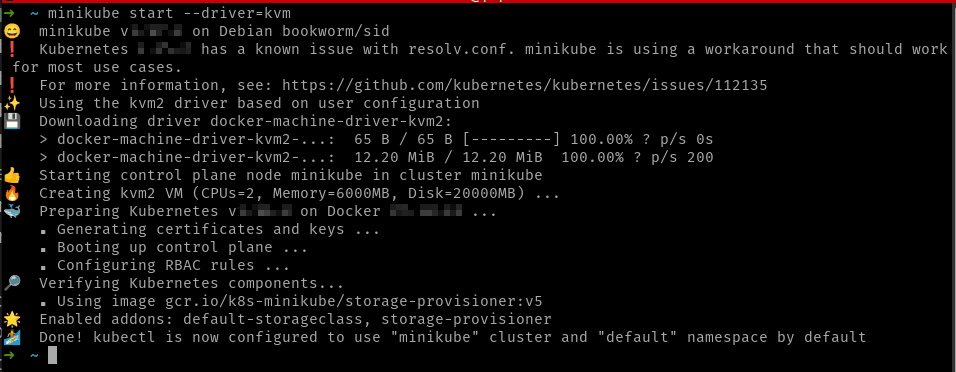
Como hemos dicho antes, otra opción interesante para ejecutar MiniKube usando VMs es utilizar KVM. KVM son las iniciales de “Kernel Virtual Machine” y se trata de un hypervisor que está incluido en el Kernel de Linux. Está muy relacionado con otro proyecto de emulación muy conocido en el mundo Linux: QEMU. QEMU es una “suite” completa de creación y ejecución de máquinas virtuales y puede usar KVM para mejorar su rendimiento.
Para lo que a nosotros nos atañe, Minikube soporta usar KVM para la creación de la MV que se ejecutarán en el clúster de Kubernetes. Para ello asegúrate de que tienes KVM y libvirt instalado en tu sistema. El cómo hacerlo depende de tu distro de Linux. En la documentación de MiniKube hay enlaces a cómo instalar dichos componentes para las distros más famosas. Una vez tengas esos prerrequisitos instalados, el comando minikube start --driver=kvm usará KVM para ejecutar la MV.
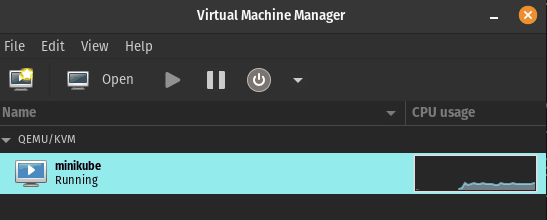
Si instalaste virt-manager (componente opcional de KVM) podrás ver la MV ejecutándose:
¡Hay más drivers que soporta Minikube! En la documentación están todos ellos.
Comandos básicos de Minikube
Ya iremos viendo los principales comandos de Minikube, pero por ahora, los que debes conocer son:
minikube versionimprime la versión de Minikubeminikube stoppara parar el clúster localminikube start(sin más parámetros) para iniciar el clúster local. Si no existe clúster local lo crea (usando el driver que especifiques con--driver, siendo Docker el driver por defecto). Si ya existe clúster creado, no debes especificar--driver.minikube ippara ver la IP del nodo de Kubernetesminikube deletepara borrar el clúster local
Ahora sólo nos falta poder conectarnos a nuestro Kubernetes, y para ello necesitamos usar kubectl, la herramienta CLI que se utiliza para administrarlo.
kubectl (pronunciado kubecontrol) es la herramienta administrativa de Kubernetes. Cualquier clúster de Kubernetes puede ser administrado usando kubectl.
Solucionar problemas de MiniKube
MiniKube funciona relativamente bien, pero a veces puede dar problemas cuando se para el clúster (minikube stop). Personalmente me he encontrado esos problemas en Windows usando Hyper-V y la causa parece ser que, por alguna razón, Hyper-V no logra parar la máquina. En esos casos, lo mejor es conectar con la MV, que nos pedirá usuario y clave:
Como login introduce simplemente root, sin clave, y estarás dentro de la MV. Entonces escribe la instrucción shutdown 0 para forzar el apagado. Al cabo de un rato, Hyper-V te dirá que la MV está apagada. Entonces, cuando sea necesario, podrás usar minikube start para levantarla de nuevo.
Kubectl
Kubernetes se gestiona completamente desde la línea de comandos. Para ello se usa kubectl. En este último enlace tienes los detalles de la instalación, pero básicamente es un ejecutable que basta que coloques en el path. No debes configurar nada más.
En este enlace tienes toda la información para instalar kubectl en tu sistema operativo
Cuando has instalado MiniKube, este ya ha agregado la configuración necesaria para que kubectl funcione (más adelante veremos dónde está y cómo podemos operar con esta configuración). Ahora mismo lo que nos interesa es que ya tienes kubectl listo para administrar tu clúster local.
Para verificar que todo funciona, desde la CLI teclea:
kubectl version
La salida debería ser la versión de kubectl (Client Version) y la versión de Kubernetes del clúster (Server Version):
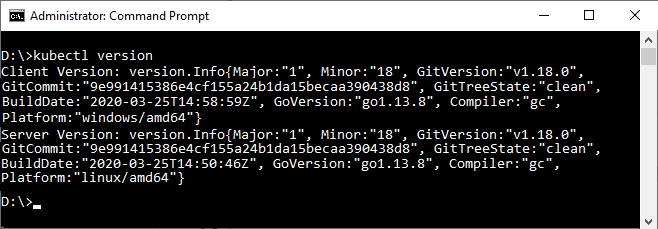
No es obligatorio que la versión del clúster de Kubernetes y la de kubectl sean la misma. En principio, diferencias entre dos versiones con un número de versión arriba o abajo están soportadas. Más allá de eso, no se garantiza que todo funcione (aunque muchas cosas puedan hacerlo). Así, si usas kubectl 1.20, está soportado su uso para las versiones de Kubernetes 1.19 (una abajo), 1.20 (la misma) y 1.21 (una arriba). Con diferencias superiores no está garantizado que todo funcione y en este caso el comando kubectl version te dará un aviso similar a este:

Vamos a ver el comando más básico de kubectl, que es kubectl get [tipo-recurso]. Devuelve un listado con todos los objetos del recurso indicado (ya verás que Kubernetes tiene muchos tipos de recursos). En este caso vamos a listar los nodos de nuestro clúster. Para ello teclea en la línea de comandos:
kubectl get nodes
Y deberías obtener una salida parecida a:
NAME STATUS ROLES AGE VERSION minikube Ready control-plane 47d vx.xx.x
Truco: muchos de los recursos se pueden poner en singular o en plural (así kubectl get node es equivalente a kubectl get nodes).
¡Eso nos indica que tenemos un clúster de k8s con un nodo! ¡Felicidades!
Recuerda: Cuando has instalado Minikube, este ha configurado kubectl por ti.
Gestionar más de un clúster con Kubectl
Es habitual que en tu día a día interacciones con más de un clúster de Kubernetes: puedes tener tu clúster local (con Minikube, MicroK8s, Docker Desktop, …) y el clúster de producción. O, por qué no, varios clústeres para distintos entornos o proyectos… En definitiva, tienes que tener un mecanismo para poder seleccionar con qué clúster quieres trabajar en cada ocasión.
kubectl usa un fichero de configuración en tu perfil de usuario (generalmente llamado config), en una carpeta llamada .kube. El cómo se obtiene este fichero depende de la manera en la que hayas creado cada clúster. Así, por ejemplo, si usas Minikube, este fichero lo crea el propio Minikube; pero lo importante es que terminarás con una configuración por cada uno de ellos.
En la jerga de Kubernetes se conoce a ese fichero con el nombre de kubeconfig, ¡pero eso no significa que el fichero se llame así en el sistema de ficheros!
El comando kubectl config get-contexts lista los distintos contextos de configuración que tengamos. La salida es como sigue:
CURRENT NAME CLUSTER AUTHINFO NAMESPACE * minikube minikube minikube
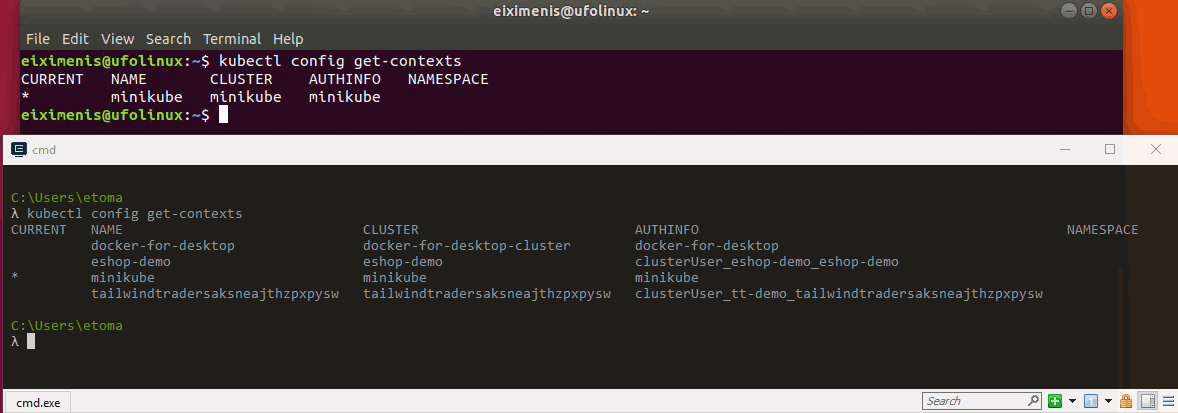
La imagen muestra la salida del comando (en un terminal Linux con un solo clúster configurado y en uno Windows en una máquina con varios clústeres configurados). Observa que hay un contexto marcado con un asterisco (*): este es el contexto actual, es decir, el que se usa en todos los comandos de kubectl.
El comando kubectl config current-context te muestra el contexto actual.
Un “contexto” es el acceso a un clúster determinado, usando un usuario específico y contra un espacio de nombres por defecto. No te preocupes si no tienes claro todavía qué significa un “espacio de nombres” o qué es un usuario para Kubernetes. En futuras lecciones lo irás viendo.
El modificador --context
El contexto actual que tengas seleccionado en kubectl se usa para todos los comandos de kubectl en cualquier terminal que abras en el ordenador. Es una configuración global. No se puede tener un terminal apuntando a un contexto y otro terminal a otro.
Dado que es relativamente habitual tener más de un contexto (clúster) de Kubernetes contra el que operar, el modificador --context, aplicado a cualquier comando de kubectl ejecuta ese comando contra el contexto indicado, con independencia del contexto actual.
Así:
kubectl get nodesmuestra los nodos del clúster del contexto actualkubectl get nodes –context minikubemuestra los nodos del clúster del contextominikube, sea cual sea el contexto actual.
Cambiar el contexto actual
Para cambiar el contexto actual y establecer uno nuevo (recuerda que eso es una configuración global), basta con el comando:
kubectl config use-context <nombre-contexto>
A partir de ese momento, todos los comandos de kubectl usarán el contexto <nombre-contexto>, a no ser que se use el modificador --context visto antes.
El modificador --kubeconfig
Por lo general el fichero kubeconfig se localiza en el directorio .kube dentro de tu perfil de usuario y se llama config. A pesar de que un mismo fichero kubeconfig puede contener (y muchas veces contiene) la información de varios contextos, a veces es posible que tengas más de un fichero kubeconfig. En este caso el parámetro --kubeconfig de kubectl te permite indicar la ubicación del kubeconfig a usar:
kubectl --kubeconfig=mi-fichero <comando-de-kubcetl>
Ojo que el modificador --kubeconfig no asume que el fichero pasado está en $HOME/.kube. Debes pasarle la ruta entera del fichero kubeconfig a usar. Si usas una ruta relativa, se asume a partir del directorio desde donde ejecutas kubectl.
No confundas el modificador --kubeconfig con el modificador --context visto anteriormente: el primero selecciona el fichero kubeconfig a usar y el segundo selecciona el contexto a usar dentro del kubeconfig que se esté usando.
La variable de entorno KUBECONFIG
Esta variable de entorno, si está establecida, le indica a kubectl la ubicación del fichero kubeconfig. Es pues, una alternativa al uso de --kubeconfig. Al ser una variable de entorno basta con que la configuremos una vez, y podemos configurarla (si así lo deseamos) por cada terminal con valores distintos, o bien de forma global.
A diferencia de --kubeconfig, dicha variable puede contener una lista de ficheros kubeconfig (separados por : en Linux/MacOs y por ; en Windows):
$ export KUBECONFIG="config-demo:config-demo-2"
PS> $Env:KUBECONFIG=("config-demo;config-demo-2")
> set KUBECONFIG=config-demo;config-demo2
Si KUBECONFIG contiene más de un fichero, se mezcla la configuración de todos ellos.
Desplegar un contenedor en Kubernetes
Vamos a ver cómo desplegar un contenedor en Kubernetes, lo cual, además, nos proporcionará la excusa para empezar a hablar del modelo de aplicación de k8s. A modo de ejemplo vamos a usar la imagen dockercampusmvp/go-hello-world.
En Kubernetes los contenedores se ejecutan en pods. No hay una relación 1 a 1 entre ambos, ya que un pod puede contener más de un contenedor, pero nunca desplegamos contenedores en Kubernetes, siempre desplegamos pods.
Vamos a ver el escenario más simple posible: crear y desplegar un pod con un solo contenedor. Para ello vamos a usar kubectl (de hecho la vamos a usar continuamente) y el comando run:
kubectl run my-first-deployment --image=dockercampusmvp/go-hello-world
Antes de empezar a usar kubectl asegúrate de tener un clúster de Kubernetes y, además, de que kubectl está configurado para usarlo. Si usas MiniKube acuérdate de usar el comando minikube start para asegurar de que el clúster local está en marcha.
La salida a este comando será un mensaje parecido a pod “my-first-deployment” created.
Vamos a describir qué es lo que ocurre al ejecutar el comando kubectl run:
1. Se ha creado un pod para ejecutar el contenedor de la imagen dockercampusmvp/go-hello-world.
Lo puedes verificar tecleando kubectl get pods:
NAME READY STATUS RESTARTS AGE my-first-deployment 1/1 Running 0 5s
2. El pod ha empezado a ejecutar el contenedor de la imagen indicada.
¡Fantástico! Has creado un pod que está ejecutando el contenedor
Parando contenedores
No tenemos en Kubernetes un equivalente a docker stop que para un contenedor, pero este sigue ahí hasta que, o lo reiniciamos con docker start o lo eliminamos con docker rm. En el caso de Kubernetes, por defecto, el pod va a ejecutar el contenedor, hasta que eliminemos el pod. Cuando un pod es eliminado, Kubernetes intenta parar el contenedor de forma “correcta” (es decir, con lo que sería equivalente a usar docker stop) y sólo si el contenedor no responde en un tiempo determinado, lo mata (lo que sería equivalente a usar docker kill). Una vez el contenedor está parado, el pod es eliminado.
El comando para eliminar un pod es kubectl delete pod <nombre-del-pod>.
Creando deployments
Recuerda que un pod es la abstracción que ofrece Kubernetes sobre un contenedor. Es la unidad mínima de despliegue en Kubernetes. Nunca desplegamos contenedores, siempre desplegamos pods (u otros objetos que a su vez terminan creando pods). Un pod por lo general ejecuta un contenedor, pero puede ejecutar más de uno, lo que posibilita ciertos escenarios que veremos posteriormente.
Crear un pod funciona perfectamente y, además, si el contenedor terminase por cualquier motivo (por ejemplo, una excepción no controlada), el pod reiniciaría el contenedor (si te fijas, en la salida hay una columna llamada RESTARTS).
Ya veremos más cosas sobre los pods, por ahora basta con que te quedes con una idea muy importante: por lo general NO creamos pods directamente. En su lugar creamos otros objetos que a su vez crean los pods. Vamos a ver el más habitual de esos objetos: el deployment.
Un deployment especifica cuántos pods debe haber en todo momento, que ejecuten un determinado contenedor. Kubernetes garantiza que en todo momento hay el número de pods especificado. Esto último es muy importante porque los pods pueden “morir”. Si bien es cierto que un pod reinicia el contenedor si este termina por cualquier motivo, ¿qué ocurre si el que “muere” es el propio pod?
Las razones por las que un pod puede “morir” son variadas: falta de recursos (memoria, CPU, etc) o errores de hardware entre ellas.
Si el pod lo hemos creado directamente y “muere”, simplemente habrá desaparecido y ya está (y el contenedor habrá dejado de ejecutarse). Pero, si hemos usado un deployment, entonces se creará automáticamente otro pod para sustituir al que ha “muerto”. Así, con deployments garantizamos que siempre hay un número determinado de pods (no tiene por qué ser sólo uno) ejecutando una imagen o más de una (recuerda que un pod puede ejecutar más de un contenedor).
Realmente quien garantiza que hay siempre N pods ejecutándose no es el deployment sino otro objeto llamado replicaset. Cuando creamos un deployment, este crea un replicaset que es quien, a su vez, termina creando los pods. Pero, por ahora, no es necesario entrar en más detalles.
Podemos usar kubectl create deployment para crear un deployment con el comando:
kubectl create deployment my-first-deployment --image=dockercampusmvp/go-hello-world
Con este comando lo que sucede es lo siguiente:
- Se ha creado un deployment, que es un objeto de Kubernetes que regula qué y cuántos contenedores se deben ejecutar
- Dicho deployment indica que debe ejecutarse un contenedor de la imagen
dockercampusmvp/go-hello-world - Por lo tanto, se creará automáticamente un pod para ejecutar dicho contenedor
Si ahora tecleas kubectl get pods verás algo parecido a lo siguiente:
NAME READY STATUS RESTARTS AGE my-first-deployment-7555545f5d-94tth 1/1 Running 0 3m
Tienes un pod (en mi caso el nombre es my-first-deployment-7555545f5d-94tth, en tu caso cambiará ya que son nombres aleatorios) cuyo estado es Running, lo que indica que se está ejecutando. Además, observa la columna READY que pone 1/1 que indica cuántos contenedores se están ejecutando (1) del total (1).
¿Recuerdas el comando kubectl get? Lo podemos usar para ver la lista de deployments que tenemos con kubectl get deployments:
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE my-first-deployment 1 1 1 1 5m
Puedes usar deployment (en singular) o deploy en lugar de deployments.
Por lo tanto, recapitulando:
- Un pod ejecuta uno o más contenedores
- No solemos crear pods directamente
- En su lugar creamos deployments, que indican a k8s qué (y cuántos) contenedores ejecutar. Kubernetes creará los pods necesarios para asegurar el cumplimiento del deployment
- El comando
kubectl get podsnos permite ver los pods - El comando
kubectl get deploymentsnos permite ver los deployments
¿Por qué crear deployments y no pods?
Vamos a ver cómo usar deployments (en lugar de crear los pods directamente) nos protege de “muertes” accidentales de nuestros pods.
Usa el comando kubectl get pods para encontrar cómo se llama tu pod y luego ejecuta:
kubectl delete pod <nombre-pod>
Con eso acabas de borrar el pod. Si ahora haces kubectl get pods la salida será parecida a:
NAME READY STATUS RESTARTS AGE my-first-deployment-7555545f5d-k27gl 1/1 Running 0 1m
¡Sigues teniendo un pod, pero es otro pod diferente! Observa que el nombre ha cambiado (y, por otro lado, la columna AGE indica 1m lo que significa que este pod tiene un minuto de vida). Esta es la ventaja principal de usar deployments: si un pod es eliminado por cualquier razón, Kubernetes creará otro, ya que el deployment, que es quien manda, exige que haya en todo momento un pod ejecutándose. De este modo tienes siempre disponibilidad de las aplicaciones.
Por si te lo estás preguntando, Kubernetes no va por ahí eliminando pods, pero nosotros debemos asumir que un pod puede morir en cualquier momento. La razón es que, como irás viendo, hay ciertos eventos que implican la destrucción de pods.
¿Significa todo esto que nunca tiene sentido crear pods directamente? No. Existen escenarios en los que crear un pod directamente tiene sentido y es algo totalmente lícito. Pero no es lo habitual. Por ejemplo, puede crearse tan solo un pod cuando quieras realizar una tarea una única vez, en plan “usar y tirar”.