Tabla de Contenidos
Configurar contenedores
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
Hasta ahora hemos ejecutado pods pero no hemos configurado sus contenedores de ninguna manera específica. Si recuerdas la parte de Docker, vimos que la forma habitual de configurar un contenedor era usando variables de entorno o bien usando bind mounts para pasarle ficheros de configuración.
En este módulo vas a ver cómo pasar variables de entorno y también ficheros de configuración a los contenedores de los pods. Para ello vas a ver dos objetos nuevos de Kubernetes: ConfigMap y Secret.
También introduciremos el concepto de “volumen” (que en Kubernetes tiene un significado ligeramente distinto del de Docker).
¿Todo listo? ¡Pues empezamos!
Variables de entorno en Kubernetes
La forma más sencilla de pasar variables de entorno en Kubernetes es hacerlo en la propia especificación del pod, en cada contenedor, en la sección spec.containers.env. Esta sección contiene un array de objetos con dos propiedades:
name: nombre de la variable de entornovalue: valor de la variable de entorno
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - image: imagenAUsar name: ctr env: - name: FooVar value: FooValue - name: BarVar value: BarValue
En este caso, el contenedor recibe dos variables de entorno FooVar y BarVar con el valor FooValue y BarValue respectivamente.
Como viste en el módulo anterior, no se suelen usar pods directamente, sino deployments. En este caso, la definición de las variables de entorno iría en la plantilla del pod. En general, cualquier cosa que se mencione que puede ir en la definición de un pod puede ir también en la definición de su plantilla.
Esto probablemente te recordará bastante a los ficheros compose donde usábamos environment para definir las variables de entorno (aunque la sintaxis es distinta). Un punto importante a tener presente es que, a diferencia de los ficheros compose, los YAML de Kubernetes NO soportan interpolación de variables de entorno. Es decir, NO PUEDES HACER ESTO:
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - image: imagenAUsar name: ctr env: - name: FooVar value: ${FooNodeVar:-DefaultValue}
Y esperar que el valor de la variable FooVar del contenedor sea el mismo que el valor de la variable de entorno FooNodeVar del nodo que ejecuta el pod. Eso en compose es posible y es bastante útil, pero los YAML de Kubernetes son más limitados en este aspecto y no permiten ningún tipo de interpolación de variables.
Cuando despliegas en varios entornos (por ejemplo, dev, pre, prod) es posible que tengas los mismos YAMLs, pero que los valores de las variables de entorno sean distintos en cada entorno. Más adelante hablaremos de cómo gestionar esos casos.
Config Map
Un config map es un objeto de Kubernetes (por lo tanto, como todo el resto de objetos tiene una descripción en YAML) cuyo principal objetivo es mantener elementos de configuración. Se trata básicamente de un objeto que mantiene pares (clave, valor), de forma que dada una clave podemos obtener su valor.
Los config maps los podemos usar en dos contextos distintos, ambos relacionados con la configuración: podemos definir variables de entorno de los contenedores cuyo valor salga de un config map, o bien podemos usarlos como volúmenes, es decir, montar en un contenedor un fichero cuyo contenido salga de un config map.
Es uno de los pocos objetos que no tiene spec y su YAML es muy sencillo:
apiVersion: v1 kind: ConfigMap metadata: name: staging data: api_url: https://api_service environment_name: staging
Puedes ver como en lugar de spec tiene data y el contenido de data es un conjunto de pares clave valor. Una vez tengas el fichero YAML lo puedes desplegar con el comando kubectl apply como cualquier otro recurso.
Para ver los Config Maps que tenemos: kubectl get cm
Establecer variables de entorno a partir de un config map
Una de las funciones básicas de un config map es servir como origen de datos para establecer las variables de entorno de un pod. Así, en lugar de tener el valor directamente en el YAML que define el pod (o, recuerda, más comúnmente la plantilla del pod), tenemos una referencia a una clave del config map. Así la sección env de un contenedor podría ser tal y como sigue:
env: - name: API_SERVER valueFrom: configMapKeyRef: name: staging # nombre del Config Map key: api_url - name: ENVIRONMENT # nombre de la variable de entorno valueFrom: configMapKeyRef: name: staging # nombre del Config Map key: environment_name - name: LOGGING_LEVEL value: Information
Esta sección env define tres variables de entorno. Una de ellas (LOGGING_LEVEL) tiene el valor directamente definido en el YAML (es para que veas que se pueden combinar ambas técnicas) y las otras dos usan valueFrom para obtener el valor de un config map. La sintaxis es un poco enrevesada, pero los puntos clave son:
valueFrom: indica que el valor viene de un origen (en contraposición a value que establece el valor directamente).configMapKeyRef: indica que este origen es la clave de un config mapname: el nombre del config mapkey: la clave cuyo valor se usará para establecer la variable de entorno
Las variables de entorno son inmutables (consecuencia de que los pods son inmutables). Una vez creado el pod, los valores de la variable de entorno no se modifican.
La sección envFrom
Si tienes muchas variables de entorno, tener que usar muchas veces valueFrom genera unos YAML largos y poco legibles. Pero tranquilo, porque Kubernetes viene al rescate con la sección spec.containers.envFrom del pod. Usando envFrom estableces las variables de entorno a partir de un origen (como el config map) pero no vas una a una, si no que las estableces todas de golpe:
envFrom: - configMapRef: name: staging
Esa sección envFrom crea tantas variables de entorno como claves tiene config map (el origen es un config map porque el elemento es de tipo configMapRef). El nombre de la variable de entorno será el mismo que la clave de config map y su valor, el valor que tenga asociado.
Observa que hay una diferencia importante entre envFrom y env usando valueFrom. Con env el nombre de la variable de entorno y el de la clave de config map no tienen por qué coincidir. Por otro lado, si usas envFrom son las claves de config map las que definen el nombre de las variables de entorno. Además, envFrom no es selectivo, no puedes decidir qué claves propagas como variables de entorno y cuáles no: toda clave que esté en config map se convierte en una variable de entorno.
Dependiendo de cómo te organices usarás más envFrom o env con valueFrom y, lo normal, es usar una mezcla de ambos, aunque depende de cada caso. Personalmente siempre intento:
- Poner las variables únicas de cada contenedor en un config map para ese contenedor y usar
envFrom. - Poner las variables compartidas por varios contenedores (y que deseo poder modificar de golpe) en un config map y usar
valueFrom. La razón de usarvalueFromy noenvFromen estos casos es que en contenedores diferentes muchas veces la variable de entorno se llama distinto.
Crear config maps de forma imperativa
Existe un comando imperativo para crear config maps:
kubectl create cm staging --from-literal api_url=https://api_service --from-literal environment_name=staging
El comando create cm acepta el modificador --from-literal <clave>=<valor> y creará un config map con la clave indicada al valor indicado. Puedes usar tantos --from-literal como claves necesites que tenga el config map.
Config Maps y ficheros de configuración
En la lección anterior hemos usado config map para establecer las variables de entorno de un contenedor. Pero ese no es su único uso. El otro uso típico es el de tener ficheros de configuración que luego serán montados en los sistemas de ficheros de los contenedores.
Crear un Config Map que contenga un fichero
Desde un punto de vista estricto, no hay diferencia entre un config map que contenga un fichero y otro que contenga, digamos, valores cadena. De hecho: ¿qué es el contenido de un fichero si no una cadena larga que suele contener saltos de línea?. Y es que así trata Kubernetes a los ficheros incrustados dentro de config maps: como valores multilínea.
apiVersion: v1 kind: ConfigMap metadata: name: config_staging data: config.json: | { "environment": "staging", "api": { "server": "https://myapi" } }
Este YAML puede sorprenderte un poco, pero es porque hemos usado la sintaxis YAML para valores multilínea. Eso no es específico de Kubernetes, es de la propia definición de YAML. Podemos poner un valor multilínea si después de la clave usamos el carácter | y luego con un nivel extra de indentación colocamos el contenido de la clave (con todos los saltos de línea que sean menester).
YAML puede volverse un poco confuso a veces, y los valores multilínea es uno de esos casos… porque hay varias formas de definirlos. La que hemos mencionado es la que a mí me parece más cómoda, pero hay otras formas. Si echas un vistazo a https://yaml-multiline.info/ puedes ver ejemplos de todas ellas y cómo afectan al valor que termina tomando la clave. Pero, que los árboles no te tapen el bosque: quédate con la idea de que YAML admite valores multilínea y Kubernetes se aprovecha de ello para “incrustar” ficheros dentro de un config map. Con el tiempo ya te irás sintiendo más cómodo con la sintaxis YAML
Cuando se usa un config map para almacenar un fichero se suele poner como clave el nombre del fichero (config.json en mi ejemplo, que es una clave válida, ya que el punto es un carácter admitido), aunque ello no es obligatorio (¡pero nos simplifica el uso del config map posteriormente!).
Por supuesto, no hay ningún impedimento para que un config map contenga más de un fichero (estrictamente hablando “valor multilínea”) o incluso una mezcla de valores multilíneas y valores, digamos, normales:
apiVersion: v1 kind: ConfigMap metadata: name: config_staging data: fichero: | { "api": "https://myapi" } env_name: staging
Crear ConfigMaps con ficheros de forma imperativa
El comando kubectl create cm admite el modificador --from-file que nos permite:
- Pasar el nombre de un fichero existente y nos crea una clave cuyo nombre es el nombre del fichero (sin su ruta) y el valor, el contenido del fichero.
- Pasar un nombre de clave y un nombre de fichero (en formato
nombre=fichero), y entonces nos crea una clave del nombre indicado y cuyo contenido es el contenido del fichero.
kubectl create cm config_files --from-file web.config --from-file config.ini=config.staging.ini
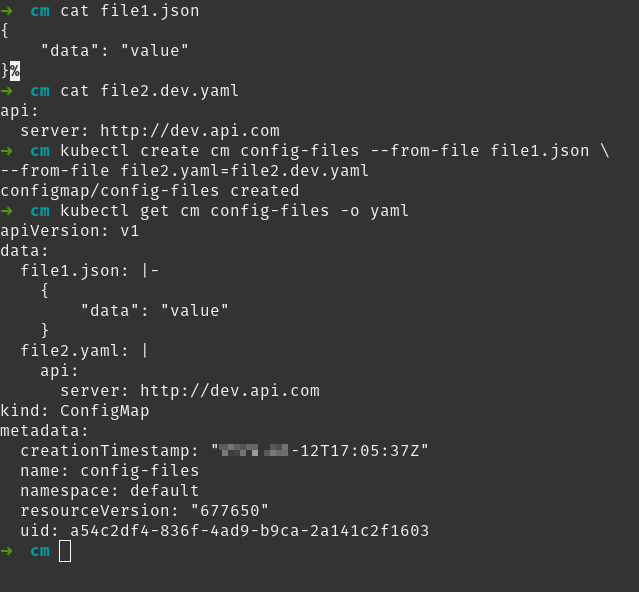
Montar un fichero de un config map en el sistema de ficheros de un contenedor
Una vez tenemos el fichero “incrustado” como un valor multilínea de una clave de un config map nos queda el segundo paso: que en el sistema de ficheros del contenedor aparezca un fichero con este contenido.
Este segundo paso se divide a la vez en otros dos pasos:
- Debemos definir el volumen en el pod
- Debemos montar el volumen en el contenedor
Así que, antes de poder continuar, es momento de introducir el concepto de volumen en Kubernetes.
Volúmenes en Kubernetes
Antes de entrar en detalle sobre los volúmenes en Kubernetes, hagamos un rápido repaso sobre los volúmenes en Docker, básicamente para que no confundas ambos conceptos, ya que tienen ciertas similitudes pero no son lo mismo.
En Docker un volumen es básicamente un directorio en la máquina host que es mapeado al sistema de ficheros del contenedor. Si este directorio es conocido y lo especificamos al lanzar el contenedor hablamos de un bind mount, si el directorio del host en concreto no es relevante, hablamos de un volumen (nombrado o anónimo).
Es cierto que Docker tiene la característica de “drivers de volúmenes” que permite tener los datos de un volumen en otro origen de datos que no sea un directorio del host (por ejemplo, un almacenamiento tipo NAS u otro origen), pero esa funcionalidad tiene relativas limitaciones
En Kubernetes definimos un volumen como un directorio (que puede tener o no tener datos) accesible por los contenedores de este pod.
Así pues, los volúmenes se definen a nivel de pod (en spec.volumes) y luego cada contenedor del pod puede montar los volúmenes del pod que desee en su sistema de ficheros.
Cuando definimos un volumen debemos especificar su tipo, lo que indica el origen de datos de ese volumen, es decir, dónde están los datos guardados. Tenemos dos tipos de volúmenes: los llamados “efímeros” o los llamados “volúmenes persistentes”. La diferencia entre ambos, es que los primeros tienen el mismo ciclo de vida que el pod (cuando el pod es destruido, los datos del volumen lo son también), mientras que los segundos tienen un ciclo de vida independiente.
Los volúmenes “efímeros” permiten:
- Mantener los datos de un contenedor entre reinicios. ¡Ojo con eso! porque puede llevar a cierta confusión. Si recuerdas, cuando hablamos de Docker comentamos “la capa de escritura de un contenedor”. Esa capa de escritura es propia del contenedor y vive mientras viva el contenedor. Si paras (
docker stop) y reinicias (docker start) un contenedor, la capa de escritura se preserva, ya que el contenedor es el mismo. Pero cuando kubelet reinicia un contenedor, lo hace siempre desde un estado limpio, por lo que, en Kubernetes, la capa de escritura no se preserva entre reinicios del contenedor. Si tenemos datos que queremos preservar entre reinicios de un contenedor de un mismo pod nos tocará usar un volumen. - Compartir datos entre dos contenedores de un pod. Todavía no hemos visto pods con varios contenedores (no te preocupes, ya llegarán), pero dado que los volúmenes los define el pod pero los montan los contenedores, dos contenedores con un mismo pod pueden montar el mismo volumen y comunicarse entre ellos.
Por su parte los “volúmenes persistentes” permiten:
- Compartir datos entre pods: mediante un volumen persistente es posible compartir datos entre N pods. Esos pods pueden estar existiendo todos a la vez o no, es decir pods futuros pueden acceder a datos generados por pods pasados que no tienen por qué seguir existiendo. Los volúmenes persistentes son objetos complejos y los veremos con detalle más adelante.
Definir volúmenes en el pod
A riesgo de hacerme pesado reitero que, cualquier cosa que se define en el pod se puede definir también en cualquier objeto que use una “plantilla de pod” como deployment o ReplicaSet
Los volúmenes se definen en spec.volumes que contiene un array con todos los volúmenes definidos por este pod. La forma es la siguiente:
spec: volumes: - name: myvol1 <tipo-volumen1>: xxx: yyy - name: myvol2 <tipo-volumen1>: aaa: bbb
Cada volumen es un elemento del array con dos propiedades. La primera, name indica el nombre del volumen. La usaremos luego cuando montemos el volumen en los contenedores. La segunda define el tipo de volumen y esa segunda puede tener más propiedades hijas en función del tipo de volumen asociado. Vamos a verlo con un ejemplo en concreto, de un YAML válido:
spec: volumes: - name: shared emptyDir: {}
Este trozo de YAML define un volumen llamado shared que es de tipo emptyDir. Los volúmenes emptyDir no tienen ninguna propiedad hija y por eso usamos la notación de objeto vacío ({}).
La notación de “objeto vacío” en YAML es opcional. Eso significa que el siguiente YAML es válido también:
spec: volumes: - emptyDir: name: shared
Recuerda que el orden de las claves es irrelevante en YAML. Las hemos invertido para que se vea mejor la idea. Simplemente ponemos emptyDir: y no ponemos ningún valor después. Luego name (que no forma parte de emptyDir) se coloca al mismo nivel de indentación. Eso es equivalente a haber puesto emptyDir: {}, pero es preferible la segunda opción porque queda más claro a simple vista que emptyDir es un objeto vacío.
Tipos de volúmenes
Hay muchos tipos de volúmenes, muchos de ellos relacionados con los “volúmenes persistentes”, para permitir a Kubernetes guardar datos en objetos “fuera del clúster”. Por ejemplo, el tipo de volumen gcePersistentDisk permite guardar datos en un disco persistente en Google Cloud. Si en lugar de Google Cloud usas Azure, está el volumen azureDisk, por ejemplo. En ambos casos hay limitaciones y no todos los clústeres pueden usar esos volúmenes.
Cuando hablemos de volúmenes persistentes ya entraremos en más detalles, pero simplemente mencionar que esos dos ejemplos que hemos puesto están deprecados. La razón es que desde hace algún tiempo tenemos un mecanismo nuevo para “volúmenes externos” que llamamos CSI y que viene a sustituir a todos esos volúmenes. Pero, de eso hablaremos más adelante.
Por ahora nos centramos en los volúmenes “efímeros” o con orígenes de datos internos al clúster. Los tipos más importantes son:
emptyDir: ese volumen representa un “directorio vacío” (es decir, nunca contiene datos al inicio). Se usa básicamente para compartir datos entre contenedores o preservar datos entre reinicios (generalmente datos de tipo cache o similares).configMap: ese volumen crea un directorio cuyo contenido son ficheros sacados a partir de los valores de un ConfigMap. Ya puedes intuir que es el que vamos a usar
secret: ese volumen crea un directorio cuyo contenido son ficheros sacados a partir de los valores de un secret. Lo veremos también en la lección sobre secretos.hostPath: ese volumen se rellena a partir de un directorio del nodo donde se ejecuta el pod en Kubernetes (sería lo más parecido a un bind mount de Docker). Lo veremos cuando hablemos de “volúmenes persistentes”, así que por el momento nos olvidamos de él.
Como dije antes, hay muchos tipos de volúmenes y los tienes todos en la documentación oficial, pero para empezar con los tres primeros de la lista anterior vas a cubrir la mayoría de tus necesidades
Montar un Config Map en un contenedor
Vamos a ver ahora cómo montar el contenido de un ConfigMap en un contenedor de un pod. Para ello, imagina que tienes el siguiente ConfigMap:
apiVersion: v1 kind: ConfigMap metadata: name: config_staging data: config.json: | { "environment": "staging", "api": { "server": "https://myapi" } }
Y quieres montar ese fichero, en el directorio /app/config del contenedor de un pod. Esa sería la sintaxis YAML:
apiVersion: apps/v1 kind: Deployment metadata: name: demovol spec: selector: matchLabels: app: demovol template: metadata: labels: app: demovol spec: # Definimos el volumen volumes: - name: cfg configMap: name: config_staging # Nombre del configmap containers: - name: demo image: dockercampusmvp/go-hello-world # Montamos el volumen volumeMounts: - name: cfg # Nombre del volumen mountPath: /app/config
Este sería el YAML que deberíamos usar. Se han puesto comentarios para que quede claro, pero los puntos clave son:
spec.volumes: definimos el volumen de tipoconfigMap. En este caso le debemos pasar el nombre del ConfigMap a usar.spec.containers.volumeMounts: montamos los volúmenes en el contenedor. Es un array donde por cada elemento especificamos el nombre del volumen y el directorio (dentro del sistema de ficheros del contenedor) donde se monta.
¡Y listo! Con esto el contenedor tendría el fichero config.json en el directorio /app/config.
Montar solo algunas claves
La sintaxis que hemos usado monta todas las claves del ConfigMap al sistema de ficheros. Por cada clave de ConfigMap se crea un fichero cuyo nombre es el nombre de la clave y su contenido el contenido de la clave.
Kubernetes no distingue entre claves multilínea y simples. Si tienes un ConfigMap con una clave con un valor simple, ese método crearía igualmente un fichero (cuyo contenido sería una sola línea con el valor de la clave)
Si quieres montar sólo algunas claves, o bien el nombre de la clave no coincide con el nombre del fichero, debes modificar cómo defines el volumen en el pod:
volumes: - name: cfg configMap: name: config_staging items: - key: config.json path: web.config
El array spec.volumes.configMap.items contiene la lista de claves a montar. Para cada clave se incluye su nombre (key) y el nombre del fichero que se generará (path). En este caso, en el contenedor, habrá el fichero web.config cuyo contenido será el valor de la clave config.json.
Uso de subPath
Cuando montamos un volumen en un contenedor todo el contenido de la carpeta especificada en mountPath es generado a partir del volumen. Eso significa que si la imagen del contenedor tuviese contenido en esa carpeta, ese contenido desaparecería y sería sustituido por el contenido del volumen.
Eso es problemático en dos escenarios:
- Cuando deseamos montar un volumen en un directorio donde la imagen ya tiene datos.
- Cuando deseamos montar un volumen en un directorio donde hemos montado otro volumen
Ahí entra el uso de subPath. Realmente, subPath significa “en qué lugar montas el volumen respecto a su raíz”. La raíz es el valor que se especifica en mountPah. Como eso parece complejo voy a ponerte un par de ejemplos.
Ejemplo 1: Montar un solo fichero en carpeta existente
Imagina que tienes una imagen que tiene los binarios de tu aplicación en /app/bin. Por requerimientos del framework que usas, debe existir un fichero de configuración, llamado config.ini, ubicado en el mismo directorio que la aplicación.
Primero crearías el ConfigMap que contuviera el fichero config.ini. Vamos a suponer que ese ConfigMap se llama cfg y la clave se llama igual que el fichero (config.ini).
Defines un volumen, llamado cfgvol a partir del ConfigMap en el pod. Y lo montas en el contenedor:
volumeMounts: - name: cfgvol mountPath: /app/bin
El problema será que cuando crees el pod, ese no se podrá inicializar… porque el directorio /app/bin ahora contiene solo tu fichero de configuración. ¡Los binarios de tu aplicación han desaparecido!.
Ahí es donde entra en juego subPath:
volumeMounts: - name: cfgvol mountPath: /app/bin/config.ini subPath: config.ini
Observa como en mountPath debes especificar también el nombre de fichero. Eso tiene lógica, ya que si el volumen cfgvol tuviese varias entradas… ¿cómo elegirías cuál quieres montar en el fichero config.ini?
Ejemplo 2: Montar un volumen en un subdirectorio de otro volumen
Por norma general no se permite montar un volumen dentro de otro volumen, ya que el segundo montaje “destruiría” al primero. Pero de nuevo, ahí entra subPath.
Imagina que tienes un volumen llamado data. No nos importa por ahora de dónde viene, pero ese volumen debe ser montado en /app/data.
Luego tienes otro volumen llamado config que proviene de un ConfigMap. Necesitas montar este volumen en /app/data/config, es decir en una carpeta dentro de donde montas el primer volumen. Para conseguir ese efecto necesitas usar subPath:
volumeMounts: - name: data mountPath: /app/data - name: config mountPath: /app/data subPath: config
Con eso consigues que el primer volumen (data) se monte en el directorio /app/data y el segundo volumen (config) se monte en la carpeta config dentro de /app/data.
Secretos
Sirva este tweet de Kelsey Hightower (una de las voces más autorizadas en lo que a Kubernetes se refiere) para presentar a nuestro siguiente objeto en la fauna de Kubernetes: los secretos (secrets).
Del tweet del bueno de Kelsey interesa, por encima de todo, la segunda parte: que la gente los confunde con credenciales u otros datos sensibles. Y, en honor a la verdad, ni la propia documentación oficial ni mucha bibliografía hacen mucho por evitar esta confusión.
¿Qué es un secreto (en general)?
¿Qué entendemos por “secreto”? Pero no en Kubernetes, sino en el desarrollo del software en general. Pues credenciales (cadenas de conexión, contraseñas) y otros datos sensibles como puede ser un token, una api key, una clave SSH o cualquier elemento similar.
La regla de oro de los secretos es nunca, bajo ninguna circunstancia, deben estar en el repositorio de código fuente.
Igual me dices, y con razón, que el repositorio de código fuente con el que trabajas es privado y yo te podría responder con el caso de un desarrollador que vió una factura enorme en AWS porque guardaba secretos (en su caso claves de AWS) en su repositorio… que él creía que era privado, pero no lo era. Pero incluso esa historia no deja de ser una anécdota. El peligro de usar secretos en el repositorio es que induce a malas prácticas que son difíciles de erradicar posteriormente. Así que, mejor no empezar mal: bajo ningún concepto guardes NUNCA secretos en tu repositorio. Si te sorprendes haciéndolo, revisa tu flujo de trabajo: algo está mal.
Así pues, quedémonos con este contexto: un secreto es información sensible (tipo credenciales) y jamás debe estar en el control de código fuente. Con esto en mente, vayamos a ver qué son los secretos en Kubernetes y por qué tanta confusión al respecto.
Secretos en Kubernetes
Un secreto en Kubernetes (secret de ahora en adelante) es un objeto, que al igual que un ConfigMap, nos permite guardar pares (clave, valor). Realmente a nivel funcional no hay diferencias entre ambos objetos, ya que en ambos casos:
- Podemos mapear sus claves a variables de entorno
- Podemos montar sus claves como ficheros en el contenedor
Entonces, ¿qué rol juegan los secrets? La verdad, es complejo de responder, ya que en la propia documentación oficial pone:

La verdad es que esos tres párrafos sacados de la documentación oficial no aclaran mucho: casi todo lo que dicen es aplicable a los ConfigMaps. La última línea nos dice que los secrets y los ConfigMaps son similares, pero los primeros están pensados para datos sensibles, pero no nos dice por qué.
Vale, para entender exactamente el rol de los secrets debemos dejar clara otra cosa: Kubernetes NO ES un sistema de manejo de secretos. Existen sistemas especializados en guardar y controlar el acceso a secretos (nos solemos referir a ellos con el nombre de vaults), pero Kubernetes no es uno de esos sistemas. Eso significa que, si bien Kubernetes debe poder acceder a esos secretos, no es el “almacén” principal donde se guardan y se configuran. O dicho de otro modo: los datos de los secrets de Kubernetes se sacan de algún otro sistema, generalmente un vault. Es como si los secrets no fuesen más que copias en Kubernetes de los secretos reales que están en el vault. Como una caché, vamos… opinión que de nuevo expresa Kelsey Hightower en otro tweet (ya te hemos dicho que es una voz autorizada en la materia).
Como todos los objetos en Kubernetes, un secret tiene su propio YAML que, como puedes ver, se parece mucho al de un ConfigMap:
apiVersion: v1 data: password: VmVyeUNvbXBsZXhQYXNzdzByZA== kind: Secret metadata: name: mysecret
Este YAML define un secret con una sola clave llamada password cuyo valor es… bueno, ¿pues secreto no?
Si ya peinas canas en este mundillo, este == al final del valor de la clave probablemente te habrá hecho levantar una ceja y a lo mejor estás sonriendo socarronamente. El motivo es que el valor de la clave no está encriptado sino simplemente codificado en BASE64.
Quizá ya conoces Base64, y si es el caso puedes saltarte esta nota. En caso contrario, veamos brevemente qué es. Se trata de un sistema de codificación, que codifica bytes usando única y exclusivamente 64 caracteres: los dígitos 0-9, las letras anglosajonas A-Z (por lo tanto sin la Ñ ni la Ç), las mismas letras pero minúsculas y los caracteres + y /. El carácter = mencionado anteriormente, se usa como un sufijo terminador. No es un sistema de cifrado, por lo tanto, dada una cadena en Base64 se puede obtener el conjunto de bytes original sin ningún problema. La gran ventaja es que permite representar cualquier secuencia de bytes usando únicamente caracteres ASCII imprimibles. Aunque Base64 codifica bytes (y por lo tanto datos binarios) es posible convertir una cadena en Base64 porque una cadena no deja de ser un conjunto de bytes. De todos modos, cuando se convierte una cadena en Base64, dado que trabajamos a nivel de los bytes que conforman la cadena y no de sus caracteres, cobra importancia cuál es el formato de codificación exacto de la cadena. Una misma cadena en UTF-8, UTF-16 o UTF-32 utiliza bytes distintos y, por lo tanto, su codificación en Base64 será distinta (dado que UTF8 se define de forma que los primeros 128 caracteres son los mismos que ASCII, una cadena en ASCII tendrá los mismos bytes que en UTF-8 y, por lo tanto, generará el mismo valor en Base64).
En un shell de Linux puedes obtener fácilmente el valor Base64 de una cadena usando:
echo -n <cadena-a-condificar> | base64
Para obtener un comando equivalente en Windows, debemos usar Powershell:
[Convert]::ToBase64String([System.Text.Encoding]::UTF8.GetBytes('<cadena-a-codificar>'))
En ambos casos el resultado es el mismo.
Resumiendo: en Kubernetes los secrets no son muy “secretos” que digamos, ya que guardan los datos en BASE64. Por lo tanto… nunca, nunca, nunca jamás debes tener un fichero YAML de un secreto en el repositorio de código fuente. Sin excepciones.
Usar los secrets
Los secrets en Kubernetes los podemos usar exactamente igual que los ConfigMaps: o bien usamos las claves para definir variables de entorno de los contenedores, o mapeamos sus claves en el sistema de fichero de los contenedores.
Para usar un secret como variable de entorno, se usa la misma sintaxis que en un ConfigMap pero:
- Si usas
valueFromen lugar deconfigMapKeyRefse usasecretKeyRef - Si usas
envFromen lugar deconfigMapRefse usasecretRef
Aquí tienes un ejemplo:
env: - name: USER_PASSWORD valueFrom: secretKeyRef: name: mySecret key: mySecretKey envFrom: - secretRef: name: myOtherSecret
Y para montar las claves de un secreto como ficheros en los contenedores, es exactamente el mismo proceso que cuando viste el ConfigMap pero el volumen en lugar de configMap es secret:
containers: - name: my-container image: my-image volumeMounts: - name: secret-data # Nombre del volumen mountPath: /etc/secret-data volumes: - name: secret-data secret: secretName: my-secret # Nombre del secret
Todo lo que vimos en la lección de ConfigMaps (por ejemplo, el montar sólo algunas claves o el uso se subPath) es aplicable a los secrets.
Cuándo usar secrets
Hemos visto lo que es un secret en Kubernetes y hemos puesto todo el énfasis que hemos podido en que los secrets no son “secretos”: están codificados en BASE64 y por lo tanto, a nivel de seguridad en este aspecto están parejos a los ConfigMaps. Así que, es lógico que tengas la duda de cuándo usarlos.
La intención de los secretos en Kubernetes es ofrecer un mecanismo de seguridad adicional en tiempo de ejecución.
- Un secreto solo es enviado a un nodo si algún pod de este nodo lo requiere
- Los secretos son transmitidos entre nodos usando TLS
- En los nodos los secretos se almacenan en tmpfs
- Se pueden guardar encriptados en etcd, de forma que si alguien obtiene acceso a etcd los secretos no se ven (directamente) comprometidos.
- Tienen sus propios permisos de RBAC. No hemos visto RBAC todavía, pero eso significa que puedes evitar que determinados desarrolladores, o pods puedan ver el contenido de los secrets usando el API de Kubernetes.
¿Pero son un mecanismo de seguridad infalible? Ni mucho menos. Para empezar quien tenga acceso a un pod tendrá acceso a los secretos que maneje este pod.
Déjame aclarar el último punto para evitar confusiones. Si bien usando RBAC puedes evitar que un desarrollador o un pod pueda ver un secret, nada impide que este mismo desarrollador pueda crear un pod con un contenedor que tenga un shell, montar el secreto en este contenedor, abrir una sesión interactiva contra él y ver el contenido del secret. Los secrets no pretenden protegerte de los desarrolladores. Por otro lado, la protección RBAC de los secrets puede impedir que un pod los lea usando el API de Kubernetes (obtendría un error de permisos), pero si alguien monta un secreto en este pod (ya sea como variables de entorno o en el sistema de ficheros) entonces nada impide que el contenedor del pod vea los valores (puesto que ya no usa el API de Kubernetes si no que sencillamente está accediendo a sus variables de entorno o ficheros locales).
Resumiendo, las buenas prácticas en el uso de datos sensibles en Kubernetes es:
- Los datos sensibles están gestionados por algún elemento fuera del clúster. Idealmente este elemento es un vault, pero puede ser cualquier otro sistema.
- Cuando se despliega la aplicación en Kubernetes se generan dinámicamente objetos de tipo secret con esos datos. Nunca usamos ficheros YAML de secrets de forma directa.
- Luego, en Kubernetes montamos esos secrets como variables de entorno o ficheros en los contenedores.
Por ejemplo, un buen lugar para crear los secrets es la pipeline de despliegue (CD). Esa pipeline puede crear esos secrets a partir de datos guardados en cualquier sistema externo, de forma dinámica en cada despliegue. La pipeline de CD puede crear los secrets como prefiera, una opción es usar Helm (que veremos más adelante) para crear esos secrets a partir de ficheros “plantilla” en el repositorio de código fuente que no contienen datos sensibles. Uses Helm o cualquier otro mecanismo para crearlos en la pipeline, el resultado es el mismo: después de finalizar la pipeline, en el clúster tienes desplegada tu aplicación y los secrets creados dinámicamente.
¡Pero eso no es la única opción! Existe una alternativa incluso mejor que consiste en tener un sistema, que se ejecuta en el propio clúster, que sea capaz de crear esos secrets directamente a partir del Vault (o repositorio externo de secretos). Lo puedes imaginar como un “plugin” que es capaz de generar secrets automáticamente en función de una cierta configuración y un repositorio externo.
Y, rizando el rizo, si no vas a usar los secrets para crear variables de entorno, sino que vas a usarlos para mapearlos como ficheros, existe una tercera alternativa que es la posibilidad de crear un volumen cuyo origen de datos sea… el propio vault. Es decir, en lugar de tener los datos sensibles en un secret y crear un volumen a partir del secret, nos podemos saltar el secret y crear el volumen directamente desde el vault. Esta aproximación es la más segura, aunque al igual que la segunda opción requiere configuración en el clúster (se tiene que instalar y configurar la pieza que es capaz de crear volúmenes a partir del vault).
Resumiendo: la gestión de datos sensibles va mucho más allá de Kubernetes y debe ser definida dentro de una operativa de DevOps.
Ver los secrets en el clúster
Puedes ver los secrets que hay en el clúster con el comando kubectl get secrets y puedes obtener la definición YAML de cualquiera de ellos de igual manera a como puedes obtener la definición YAML de cualquier objeto del clúster: con el modificador -o yaml. Una vez tienes el YAML, dado que está en BASE64, puedes obtener el valor real sin muchos problemas:
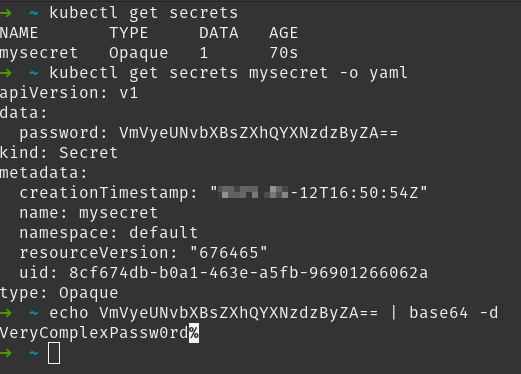
En la captura se ve cómo se puede usar el comando de Linux (base64 -d) para decodificar el valor en BASE64 y obtener el valor original.
Crear secretos con el comando kubectl create
Antes hemos mencionado que un buen lugar para crear secrets puede ser la pipeline de despliegue y que puede usar Helm para ello. Otra opción es usar el comando imperativo kubectl create secret para crear un secreto. Este comando funciona igual que el comando kubectl create cm, o sea que acepta los modificadores --from-file y --from-literal y se encarga el propio comando de transformar los valores a BASE64.
Lo único es que, como Kubernetes usa secrets para algunas tareas específicas (como por ejemplo, guardar certificados TLS), cuando creamos el secreto debemos decirle “para qué es”. Si lo vamos a usar para crear variables de entorno o bien montarlo en el sistema de ficheros, entonces es un secreto genérico (generic) y el comando nos quedaría así:
kubectl create secret generic my_secret --from-literal password=PassW0rD
Acceder a imágenes en un registro de imágenes privado
Existe un tipo especial de secretos en el clúster destinado para aquellos secretos que guardan credenciales para que Kubernetes pueda autenticarse contra registros de imágenes privados.
En este caso debes crear un secreto de tipo docker-registry y especificar el usuario, contraseña y registro asociado:
kubectl create secret docker-registry <nombre> --docker-username <login> --docker-password <password> --docker-server <dns-registro>

En la imagen puedes ver la creación de un secreto y cómo este se guarda en el servidor (Kubernetes guarda un fichero .dockerconfigjson dentro del secreto).
Ahora queda por ver cómo indicarle a Kubernetes que use este secreto para todas las imágenes del registro quay.io. Pues bien, esa es una configuración que se aplica en el pod. En concreto debes usar spec.ImagePullSecrets. Este campo es un array de los posibles secretos a usar.
- Es un array porque cada secreto aplica a un registro, pero un pod puede tener que acceder a varios registros si define varios contenedores cuyas imágenes son de distintos registros.
- Se aplica a nivel de pod porque distintos pods pueden tener la necesidad de acceder al mismo registro con credenciales distintas.
- Para cada contenedor definido en el pod, Kubernetes sabe automáticamente qué secreto, de los que haya definido en ImagePullSecrets, debe usar, porque cada secreto está vinculado a un registro de imágenes.
apiVersion: v1 kind: Pod metadata: name: private-image spec: containers: - name: private-reg-container image: registro-privado.com/imagen-privada:tag imagePullSecrets: - name: registro-privado
En este fichero YAML se asume que:
- Existe un secreto de tipo
docker-registryllamadoregistro-privado. - Este secreto está vinculado al registro
registro-privado.com(ese es el valor del parámetro--docker-servercuando se creó el secreto).
Ver los logs de un contenedor
Ver los logs de un pod es posible gracias al comando kubectl logs. Este comando espera un pod y nos mostrará sus logs.
Bueno, debo hablar con un poco más de propiedad: lo son de los contenedores, no de los pods. El comando kubectl logs muestra los logs del contenedor que está ejecutando el pod. Lo más parecido a lo que serían “logs del pod” está en la sección EVENTS del comando kubectl describe pod. Más adelante, cuando hablemos de pods con más de un contenedor, ya te diré cómo elegir el contenedor del que quieres ver los logs.
El comando es realmente simple:
kubectl logs <nombre-pod>
Y nos mostrará por pantalla los logs. Al igual que en Docker, por logs entendemos todo aquello que el contenedor escribe en stdout/stderr. Si el contenedor deja sus logs dentro de un fichero, no vamos a verlo con este comando.
Logs en réplicas
Imagina que tienes un deployment escalado a dos (o más réplicas) y quieres ver los logs. Una opción es lanzar dos (o más) comandos kubectl logs, uno contra cada uno de los pods. Pero esto puede ser pesado y existe una opción mejor: que kubectl logs te muestre los logs de varios pods a la vez.
Para ello puedes usar el modificador -l etiqueta=valor que te seleccionará todos los pods que tengan la etiqueta indicada con el valor indicado. Dado que todas las réplicas generadas por un mismo deployment (o ReplicaSet) comparten etiquetas, esto te permite ver en un solo comando los logs de todos los pods.
El modificador -l aplica no solo a kubectl logs sino a cualquier comando que seleccione objetos (no solo pods), como por ejemplo, kubectl get
Establecer el comando inicial de un contenedor
Cuando definimos un pod existe la posibilidad de indicarle cuál debe ser el comando inicial de dicho contenedor. Al igual que en el caso de Docker, si no indicamos nada se ejecuta el comando definido en la imagen.
Usar Command
Este es el método más habitual para indicar el comando inicial a ejecutar.
Lo que en Kubernetes llamamos command en Docker se llama entrypoint. Así pues, redefinir command en Kubernetes es equivalente a redefinir entrypoint en Docker
Por ejemplo, en la imagen oficial de alpine su proceso inicial es un shell (/bin/sh), lo que puedes comprobar si la ejecutas en Docker:
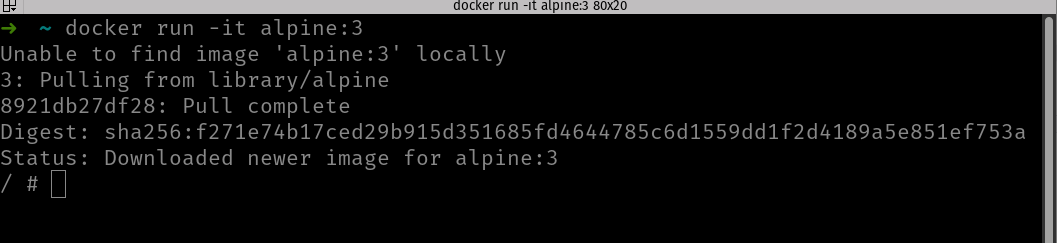
En la imagen puedes ver cómo al ejecutar con docker run la imagen de alpine se abre el shell (he ejecutado con -it porque sino, al no tener terminal asociado shell termina y el contenedor finaliza también).
Ahora bien, si recuerdas, en el comando docker run podemos usar --entrypoint para establecer el entrypoint:
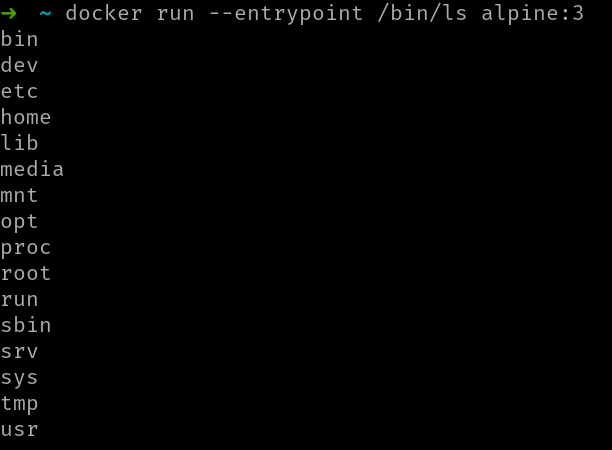
En la imagen puedes ver el resultado de ejecutar la misma imagen pero con un entrypoint distinto: en este caso /bin/ls.
Pues exactamente lo mismo ocurren en Kubernetes: al definir un contenedor dentro del pod podemos usar spec.containers.command para indicar el proceso inicial:
apiVersion: v1 kind: Pod metadata: name: command spec: containers: - name: main image: alpine command: - /bin/ls restartPolicy: Never
Si ejecutas este pod verás que queda en estado completed una vez el contenedor finaliza. Si ahora ejecutas el comando kubectl logs verás la salida del comando ls ejecutada por el contenedor.
Observa que command es un array. Eso es un poco raro, no se trata de que puedas especificar varios comandos, sino que si un comando consta de varias partes, cada una de ellas debes establecerla como un elemento del array.
Ten presente que command debe ser un ejecutable. Por lo tanto, no puedes usar como command comandos internos de shell (como generalmente son cd o pwd). Ahí el truco es lanzar un comando tipo /bin/sh -c pwd, que ejecuta un shell y le indica la sentencia a ejecutar. En este caso, la definición sería:
apiVersion: v1 kind: Pod metadata: name: command spec: containers: - name: main image: alpine command: - /bin/sh - -c - pwd restartPolicy: Never
Muchas veces en lugar de esa notación de array con los tres guiones que hemos mostrado aquí, verás la notación más compacta: command: ["/bin/ls", "-c", "pwd"]. Que sepas que ambas anotaciones son equivalentes.
Un uso clásico de esto es cuando queremos ejecutar como comando inicial algún script de shell:
apiVersion: v1 kind: Pod metadata: name: command spec: containers: - name: main image: alpine command: ["/bin/sh", "-c", "while true; do echo hello; sleep 10;done"] restartPolicy: Never
Si te parece raro que command sea un array en lugar de una cadena, hay más gente como tú. Probablemente las razones estén en el propio Linux y el motivo podría ser que execve(2) en Linux espera un array para definir el proceso a ejecutar.
Cuando usas command en Kubernetes, este será el comando que se ejecutará inicialmente. Los valores de ENTRYPOINT y CMD (ambos) de la imagen serán ignorados.
Usar args
La otra opción para lidiar con el proceso inicial de la imagen es usar spec.containers.args. La idea es que args te permite pasar argumentos al proceso inicial.
Si especificas args, pero no command, entonces se usará el proceso inicial definido en la imagen y se le pasarán los parámetros que hayas indicado en args. Si especificas command y args, entonces los valores especificados en args se pasarán como parámetro al proceso indicado en command.
Generalmente si usas command no tienes necesidad de usar args, ya que command te permite pasar también los parámetros, aunque si prefieres, puedes hacerlo:
apiVersion: v1 kind: Pod metadata: name: command spec: containers: - name: main image: alpine command: ["/bin/sh"] args: ["-c", "while true; do echo hello; sleep 10;done"] restartPolicy: Never
Este YAML es equivalente, en cuanto a funcionalidad, al que hemos visto antes. En este caso se establece como proceso inicial /bin/sh y se le pasan como parámetros el modificador -c y el script. Exactamente igual que antes.
Y, dado que el proceso inicial de alpine ya es /bin/sh también puedes hacer eso:
apiVersion: v1 kind: Pod metadata: name: command spec: containers: - name: main image: alpine args: ["-c", "while true; do echo hello; sleep 10;done"] restartPolicy: Never
Es decir, obviar command y usar sólo args, lo que pasará esos parámetros al proceso inicial definido por la imagen del contenedor.
Resumen del módulo
En este módulo hemos introducido dos objetos nuevos de Kubernetes, ambos relacionados con la configuración de los contenedores.
Por un lado ConfigMaps y por otro secrets, que sirven a propósitos similares pero tienen ligeras dependencias.
Después de este módulo ya eres capaz de:
- Configurar tus contenedores con variables de entorno
- Configurar tus contenedores con ficheros de configuración
- Decidir cómo manejar datos “sensibles” tales como contraseñas y claves SSH
Con lo visto hasta ahora ya sabes todo lo imprescindible para desplegar aplicaciones sin estado en Kubernetes, excepto por un detalle: cómo acceder a ellas desde fuera del clúster.
¡A ello le vamos a dedicar el siguiente módulo!