Tabla de Contenidos
Desplegar aplicaciones SIN estado en Kubernetes
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
En este módulo vas a ver cómo desplegar aplicaciones “sin estado”. En este contexto por aplicaciones entendemos no un sistema entero (como podría ser una aplicación de facturación) sino lo que vendría a ser un pod; por ejemplo, una API o un servicio.
Por lo de “sin estado” nos referimos a que esta aplicación no mantiene ningún dato (en memoria o disco) sobre los clientes. Una aplicación “sin estado” asume que este estado está en algún otro lugar, lo puede mandar el cliente o bien puede estar en otra aplicación, como podría ser una base de datos.
En este módulo vas a ver dos objetos nuevos de Kubernetes pensados específicamente para desplegar aplicaciones sin estado: ReplicaSet y Deployment.
Al finalizar el módulo serás capaz de desplegar aplicaciones sin estado y entender cada uno de esos objetos de Kubernetes y cómo se relacionan entre ellos.
¡Vamos allá!
El ReplicaSet
El ReplicaSet es un objeto cuya misión fundamental es asegurar que en todo momento hay N pods idénticos. Se trata de lo que entendemos por un “controlador” en Kubernetes.
Llamamos “controlador” a aquellos objetos que se encargan de controlar y gestionar a otros objetos. En este caso el ReplicaSet controla a pods porque es capaz de crear (y si es necesario destruir) pods para garantizar que en todo momento hay N de ellos.
No existe comando imperativo para crear un ReplicaSet, eso significa que hay que usar, sí o sí, su definición YAML. ¡Así que vamos a verla!
apiVersion: apps/v1 kind: ReplicaSet metadata: name: hello spec: replicas: 1 selector: matchLabels: app: hello template: metadata: labels: app: hello spec: containers: - name: hello image: dockercampusmvp/go-hello-world
Bien, ya has visto algunas definiciones de YAML y si te fijas verás que se parece bastante a la definición de un pod. ¡De hecho todo lo que está dentro de spec.template es la definición de un pod! Luego te cuento un poco más.
Puedes ver que pertenece a la API apps/v1. En esta API hay varios objetos destinados al despliegue de “aplicaciones” (siempre entendiendo aplicaciones con el significado que le dimos en la lección anterior).
La sección metadata es la habitual, donde especificamos el nombre y luego viene la especificación (spec), donde hay tres partes importantes:
replicas: el número de pods que vamos a querer.selector: el selector de esos podstemplate: la plantilla de esos pods
Tanto selector como template son importantes y requieren más explicación. Empecemos por esa última.
La plantilla de pod (Pod Template)
El valor de spec.template se conoce como “plantilla de pod” (o pod template en inglés). Además de ReplicaSet hay más objetos que tienen una plantilla de pod, que ya irás viendo. Dado que ReplicaSet crea pods, tiene que haber algún mecanismo que le indique cómo deben ser los pods que crea. Ese mecanismo es precisamente, la plantilla de pod.
Una plantilla de pod es literalmente, toda la especificación del pod. Es decir, todo lo que iba dentro de spec en un fichero YAML de un pod puede ir dentro de spec.template.spec del YAML del _StatefulSet.
Y con los metadatos del pod, lo mismo: todo lo que puede ir en metadata en un fichero YAML de un pod puede ir en spec.template.metadata del fichero YAML de un StatefulSet, con una única excepción: el nombre. No podemos usar spec.template.metadata.name.
La razón de no poder establecer el nombre es que este debe ser único, y un StatefulSet puede crear varios pods (tantos como indique el valor de spec.replicas). Todos ellos serán idénticos (ya que plantilla de pod sólo hay una), pero cada una debe tener un nombre distinto. Es por eso que ReplicaSet genera un nombre aleatorio para cada uno de sus pods.
El selector
StatefulSet debe saber cuántos pods existen porque, al final, su misión es garantizar que siempre haya tantos como hayamos indicado. Pero,StatefulSet no mantiene una relación directa con los pods que crea (Kubernetes por lo general intenta evitar este tipo de relaciones). Eso significa que, literalmente un StatefulSet no sabe qué pods ha creado. Y si no sabe qué pods ha creado, difícilmente podrá saber si uno de ellos “ha muerto” y debe ser reemplazado.
Ahí es donde entra el selector: el valor que pongamos en spec.selector es un selector y StatefulSet asumirá que son suyos aquellos pods que sean seleccionados por ese selector. Lo habitual es que el selector sea de tipo matchLabels, lo cual significa que el selector seleccionará a todos los pods que tengan las etiquetas indicadas (tanto internos como externos, es decir, pods creados a posteriori).
Claro, eso implica que debes asegurarte de que los pods creados por StatefulSet tengan esas mismas etiquetas. Es por ello que, si observas el YAML verás que el valor de spec.selector.matchLabels (las etiquetas del selector) coincide con el valor de spec.template.metadata.labels (las etiquetas que tendrán los pods creados por StatefulSet). Para que no haya errores, Kubernetes te obliga a que eso se cumpla.
Si intentas desplegar un YAML donde esa igualdad no se cumpla recibirás un error:

El mensaje de error es un poco confuso, pero básicamente nos dice que el valor de spec.template.metadata.labels (que es app: hello) no se corresponde con el valor del selector (el mensaje no nos dice cuál es).
Si quieres probar, encontrarás el fichero bad_rs.yaml en la sección de descargas
Selectores avanzados
ReplicaSet soporta selectores avanzados usando spec.selector.matchExpressions en lugar de spec.selector.matchLabels. Usando el selector basado en matchLabels, sólo puedes especificar un conjunto de etiquetas y su valor. Pero, no puedes indicar expresiones complejas del estilo “que esta etiqueta tenga el valor X ó Y”. Para estos escenarios se requiere usar matchExpressions:
apiVersion: apps/v1 kind: ReplicaSet metadata: name: frontend-1 spec: selector: matchExpressions: - key: tier operator: In values: - frontend - services
Este YAML muestra un ejemplo de selector avanzado usando matchExpressions. Como puedes ver, matchExpressions es un array de objetos que definen las expresiones que se evaluarán para indicar si un pod pertenece al selector. Todas esas expresiones se evalúan sobre las etiquetas del pod.
Cada entrada de matchExpressions es un objeto con tres propiedades:
key: nombre de la etiquetaoperator: operador a usar para evaluar el valor de la etiquetaIn: el valor de la etiqueta está contenido en valuesNotIn: el valor de la etiqueta NO está contenido en valuesExists: la etiqueta existeNotExists: la etiqueta NO existe
values: valores que se usan para evaluar la etiqueta
El YAML anterior muestra un selector que se cumplirá si el valor de la etiqueta tier es frontend o services.
Si hay varios valores en matchExpressions deben cumplirse todos para satisfacer al selector.
Quizá ya te has dado cuenta, pero una entrada en matchLabels equivale a una entrada en matchExpressions donde key es la etiqueta, values tiene un solo valor (que es el indicado) y el operador es In. Es decir:
matchLabels: tier: frontend
Equivale a:
matchExpressions: - key: tier operator: In values: - frontend
Desplegando un ReplicaSet
Vamos a desplegar ReplicaSet. Si usas el comando kubectl apply -f <fichero_yaml> con un fichero que tenga el YAML mostrado anteriormente, Kubernetes te debería responder con:
replicaset.apps/hello created
Eso significa que ReplicaSet se ha creado. En nuestro caso el valor de spec.replicas era 1, indicando que queríamos un pod. ¿Tenemos ese pod? Puedes ver los pods con kubectl get pods:
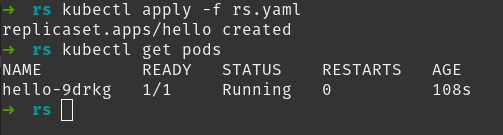
Observa el nombre del pod: hello-9drkg. Se compone del nombre de ReplicaSet seguido de un sufijo aleatorio (en tu caso seguramente será distinto). De esta manera ReplicaSet se asegura de que el nombre sea único.
Ahora, haz una prueba: borra (con kubectl delete pod) el pod. Y luego haz un kubectl get pods. ¿Qué es lo qué ocurre? ¿Tiene sentido?
Lo que ocurre es que ReplicaSet creará otro pod para sustituir al que has eliminado. Eso lo puedes ver porque el nombre del nuevo pod será distinto y su valor de AGE será muy bajo.
Recuerda; la misión de ReplicaSet es garantizar que siempre haya tantos pods como se desee. Por lo tanto, cualquier evento que implique la eliminación de un pod (incluso aunque lo borres tu manualmente), supondrá que ReplicaSet cree un sustituto para que siempre haya el número de pods esperado.
La manera de eliminar los pods creados por un ReplicaSet es eliminar el ReplicaSet entero usando el comando:
kubectl delete rs <nombre-replicaset> .
Escalando un ReplicaSet
Escalar un ReplicaSet es tan sencillo como modificar spec.replicas del fichero YAML al valor deseado y luego usar otra vez el comando kubectl apply.
La siguiente imagen muestra lo que ocurre cuando hemos lanzado el comando apply después de modificar el valor de las réplicas a 5:
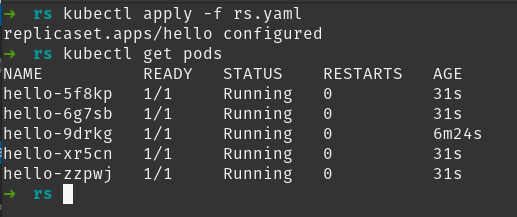
Puedes ver como ahora hay cinco pods, todos ellos idénticos (es decir, ejecutan la misma imagen).
Este proceso de desplegar (con apply), editar el fichero YAML y desplegar los cambios (con apply otra vez) es muy habitual.
Hay otra manera de escalar un ReplicaaSet que es usando el comando imperativo kubectl scale:
kubectl scale rs/hello --replicas=2
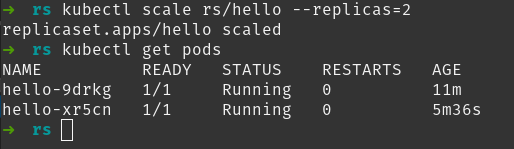
Puedes ver cómo hemos pasado de los 5 pods que teníamos a sólo 2. ReplicaSet ha eliminado los pods restantes.
Una pregunta típica en este punto es: “¿si el número de réplicas disminuye, cómo puede saber qué pods serán eliminados?”. Pues la respuesta es que no se sabe. ReplicaSet elegirá al azar los pods que debe eliminar.
Puedes escalar un ReplicaSet a 0, eso eliminará todos los pods de ese ReplicaSet. Eso es interesante cuando te interesa, temporalmente, eliminar todos los pods.
¿Cuándo usar ReplicaSet?
¿Recuerdas cuando comenté que no es habitual crear pods directamente? Eso es porque si creas un pod y le ocurre algo a ese pod que implica que “muera”, Kubernetes no hará nada al respecto. Lo mínimo que esperamos es que, si un pod desaparece (por ejemplo, porque se cae un nodo), este pod sea recreado en algún otro lugar: eso es, precisamente la tarea que hace ReplicaSet. Por ello, no es habitual crear pods directamente, a no ser que sean para temas muy específicos y de “usar y tirar”.
Pero, antes de que te lances a desplegar ReplicaSets, déjame que te diga otra cosa: tampoco se suelen desplegar ReplicaSets directamente. Eso no significa que todo lo que has visto no sirve para nada, verás cómo entender ReplicaSet es muy importante para entender Kubernetes, pero desplegarlos directamente no suele hacerse.
La razón de ello es el objeto que vamos a presentar a continuación: Deployment.
El Deployment
Deployment es un objeto de “alto nivel” pensado, específicamente, para el despliegue de aplicaciones (recuerda, pods en nuestro contexto) sin estado. Al igual que ReplicaSet, un deployment permite ejecutar N pods (réplicas) todos ellos idénticos y garantizar que hay N en todo momento.
Quizá te preguntes qué necesidad hay de este objeto, si en principio ReplicaSet cubre nuestras necesidades. La razón tiene que ver con la actualización de nuestra aplicación.
Actualización de la aplicación
Entendemos por “actualización” de la aplicación cualquier cambio que se realice en la plantilla del pod. Así, cambiar la imagen OCI es una “actualización”, pero también lo es cualquier otro cambio que sobre el pod podamos realizar.
La gracia de deployment es que nos permite hacer de forma sencilla esos cambios sin que haya caída de servicio, eso es, que siempre haya al menos un pod que pueda responder a los clientes.
Recuerda que los pods son inmutables. Por lo tanto, cualquier cambio que se haga en ellos implica la creación de un pod nuevo y la destrucción del antiguo. Deployment se encarga de coordinar esas acciones para evitar las caídas de servicio
Actualizar la plantilla del pod en un ReplicaSet hará que todos los pods que se creen nuevos usen la plantilla nueva, pero los pods existentes seguirán habiendo estado creados con la plantilla antigua. Imagina que tienes un ReplicaSet y lo tienes escalado a 4 réplicas. Luego, cambias el ReplicaSet y modificas la imagen del contenedor del pod para que en lugar de ser myimage:1.0 sea myimage:2.0.
ReplicaSet tiene la plantilla nueva, pero los 4 pods existentes siguen ejecutando myimage:1.0. Debes forzar que ReplicaSet recree los pods. Para ello tienes dos opciones:
- Escalas ReplicaSet a 0 réplicas (eso destruirá todos los pods) y luego lo reescalas a 4 réplicas otra vez. Los pods serán recreados usando la nueva plantilla y ejecutarán
myimage:2.0. Esta aproximación implica caída de servicio, ya que durante un tiempo no hay ningún pod ejecutando tu aplicación. - Eliminas (con
kubectl delete) los pods antiguos y eso forzará que ReplicaSet los recree de nuevo. Al recrearlos lo hará con la nueva plantilla. Si en lugar de eliminarlos todos de golpe lo haces por bloques (por ejemplo, eliminas dos, te esperas a que ReplicaSet los recree y se estén ejecutando y luego eliminas dos más), entonces no hay caída de servicio, ya que en todo momento hay pods ejecutando tu servicio.
La primera opción es rápida y sencilla, pero implica caída de servicio. La segunda es compleja, involucra varios pasos, pero nos permite actualizar la aplicación sin que haya caída de servicio. Pues bien, a grandes rasgos, lo que hace deployment es automatizar esta segunda opción.
Rolling Updates
Cuando modificamos la plantilla del pod de un deployment, se genera lo que llamamos un rolling update (actualización continua). Este proceso consiste en la paulatina sustitución de los pods viejos, por los pods nuevos.
Cualquier modificación que hagamos en la plantilla del pod fuerza un rolling update
Mientras rolling update está en marcha, habrá pods nuevos y pods viejos a la vez, por lo que un cliente puede ser atendido por cualquiera de ellos. Es más, la primera petición de un cliente puede ser atendida por un pod viejo y la siguiente por un pod nuevo (o viceversa). Pasado un cierto tiempo, rolling update finalizará y todos los pods serán nuevos (si la actualización ha sido exitosa).
Cuando se ejecuta un rolling update del deployment va sustituyendo los pods viejos por pods nuevos “por bloques”. Eso significa que durante un cierto tiempo puede haber más pods que las réplicas indicadas. Para controlar “cuántos pods de más” puede haber, deployment usa el campo spec.strategy.rollingUpdate.maxSurge. Este campo indica el valor de pods extras que pueden existir en todo momento.
Rollbakcs
Un deployment no sólo permite realizar rolling updates, sino que llega con un regalo bajo el brazo: es posible revertir los cambios hechos por un rolling update y volver a la versión anterior. Este proceso lo conocemos con el nombre de “rollback” y lo podemos usar en aquellos casos en que la actualización ha sido exitosa pero ha generado algún error (en forma de comportamiento anómalo de la aplicación), o bien que, por algún motivo, la actualización falla. En estos casos deployment nos permite volver hacia atrás.
Eso implica que, de alguna manera, deployment debe tener un “histórico de versiones” (de “plantillas de pod” realmente, ya que recuerda que son los cambios en la plantilla de pod lo que genera una versión nueva). Y ahí se esconde una de las relaciones más interesantes en Kubernetes: la de deployments con ReplicaSets.
Al igual que ReplicaSet, deployment es un controlador, pero a diferencia de ReplicaSet, deployment NO controla pods, en su lugar… ¡controla ReplicaSets!
Cuando creamos un deployment se crea siempre un ReplicaSet. Este ReplicaSet está controlado por deployment y es el encargado de asegurar que en todo caso haya N réplicas de los pods. La gracia está en que deployment no puede crear uno, sino varios ReplicaSets:
- Cuando se genera un rolling update, deployment crea otro ReplicaSet con la nueva plantilla de pod pero mantiene el antiguo.
- La sustitución paulatina de pods viejos por pods nuevos es en realidad un desescalado de ReplicaSet antiguo y un escalado del nuevo.
- Cuando el rolling update finaliza, el ReplicaSet antiguo está escalado a 0 y el ReplicaSet nuevo está escalado al valor correcto de réplicas. Terminamos así con el número de pods esperados, todos ellos creados a partir de la nueva plantilla.
- Cuando necesitamos ejecutar un “rollback”, deployment genera otro rolling update.
- Pero ahora desescala ReplicaSet actual y escala el viejo.
- Al finalizar rolling update, lo que tendremos será el número correcto de pods, todos ellos con la plantilla de pod anterior: el “rollback” se ha completado.
De este modo, manteniendo un conjunto de ReplicaSets, deployment gestiona tanto los rolling updates como los “rollbacks”, y ese “histórico de versiones” del que hablábamos se materializa en un “histórico de ReplicaSets”.
El campo spec.revisionHistoryLimit establece el número máximo de ReplicaSets que mantiene deployment. Por defecto vale 10 y huelga decir que esos ReplicaSets son mantenidos y gestionados por deployment y nosotros no tenemos que hacer nada con ellos.
Descripción YAML de deployment
La descripción YAML de deployment se parece mucho, muchísimo, a la de ReplicaSet. De hecho puedes “convertir” un ReplicaSet en un deployment cambiando el valor de kind, de ReplicaSet a Deployment. El resto puede ser todo idéntico.
apiVersion: apps/v1 kind: Deployment metadata: name: hello spec: replicas: 5 selector: matchLabels: app: hello template: metadata: labels: app: hello spec: containers: - name: hello image: dockercampusmvp/go-hello-world
Lo ejecutaríamos con kubectl apply -f deploy.yaml (suponiendo que el fichero se llamase deploy.yaml). Si luego queremos ver los deployments que hay: kubectl get deployment.
Un deployment soporta los mismos selectores que ReplicaSet
Partiendo de esta base, deployment añade algunos campos interesantes (que no existen en ReplicaSet) que son los que configuran cómo se lleva a cabo rolling update.
Estrategia de actualización
El campo spec.strategy le indica a deployment cómo debe proceder para actualizar la aplicación, debido a un cambio en la plantilla del pod. Existen dos estrategias que puedes elegir, usando el campo spec.strategy.type:
recreate: deployment eliminará todos los pods viejos antes de crear los nuevos. Eso implica caída de servicio. Este valor se usa en aquellos casos en que la coexistencia de pods antiguos y nuevos no es posible, o bien, no nos importa que haya una caída temporal de servicio.rollingUpdate(valor por defecto): deployment efectuará un rolling update tal y como se ha explicado anteriormente.
Si usas rolling update, entonces en spec.strategy.rollingUpdate puedes especificar un par de valores más:
spec: strategy: type: rollingUpdate rollingUpdate: maxSurge: 1 # El valor por defecto es 25% maxUnavailable: 20% # El valor por defecto es 25%
maxSurge: como se ha indicado antes se trata del número máximo de pods extras que se admiten durante rolling update. Se puede expresar en un número fijo o un porcentaje (sobre las réplicas).maxUnavailable: puede ser un porcentaje sobre las réplicas (como el ejemplo) o un valor absoluto. En ambos casos indica el número máximo de pods que se admite que estén no disponibles durante rolling update.
Por ejemplo, si actualizamos un deployment escalado a 10 réplicas:
- Y
maxSurgevale 30%, eso significa que admitimos hasta 13 (10 + 30% de 10) pods, por lo que el ReplicaSet nuevo se puede escalar inmediatamente a 3 antes de desescalar el viejo. - Y
maxUnavailablevale 30%, eso significa que toleramos que haya 3 (30% de 10) pods menos, por lo que el ReplicaSet antiguo puede desescalarse a 7 de forma inmediata, antes de escalar el nuevo.
Si estableces maxSurge a 0 no puedes establecer maxUnavailable a 0, ya que eso dejaría deployment sin opciones: no podría desescalar el ReplicaSet viejo primero (rompería maxUnavailable), pero tampoco podría escalar el ReplicaSet nuevo primero (rompería maxSurge).
Escalando un Deployment
Para escalar un deployment puedes seguir los mismos pasos que en ReplicaSet:
- Actualizar el valor de
spec.replicasen el fichero YAML y aplicarlo de nuevo conkubectl apply - Usar el comando imperativo
kubectl scale deploy/<nombre-deployment> --replicas=<numero-replicas>
El escalado también puede ser hacia “abajo”, es decir, indicar un número menor de réplicas: kubectl scale --replicas=1 deployment/my-first-deployment. Kubernetes eliminará los pods que sean necesarios.
Trabajando con Rolling Updates
Cada vez que actualices el YAML de deployment, modifiques cualquier valor de la plantilla del pod (spec.template) , se forzará un rolling update.
El comando kubectl rollout te permite ver el estado de rolling update, así como volver hacia atrás (ejecutar un “rollback”).
Ver el estado de rolling update
Si tienes un rolling update en marcha (es decir, deployment está sustituyendo pods viejos por los nuevos), puedes ver el estado usando kubectl rollout status. Este comando se queda a la espera de que rolling update finalice y va mostrando los pasos. Por ejemplo, en este caso, hemos escalado un deployment llamado hello de 5 a 25 réplicas y justo después del apply hemos ejecutado rollout status:
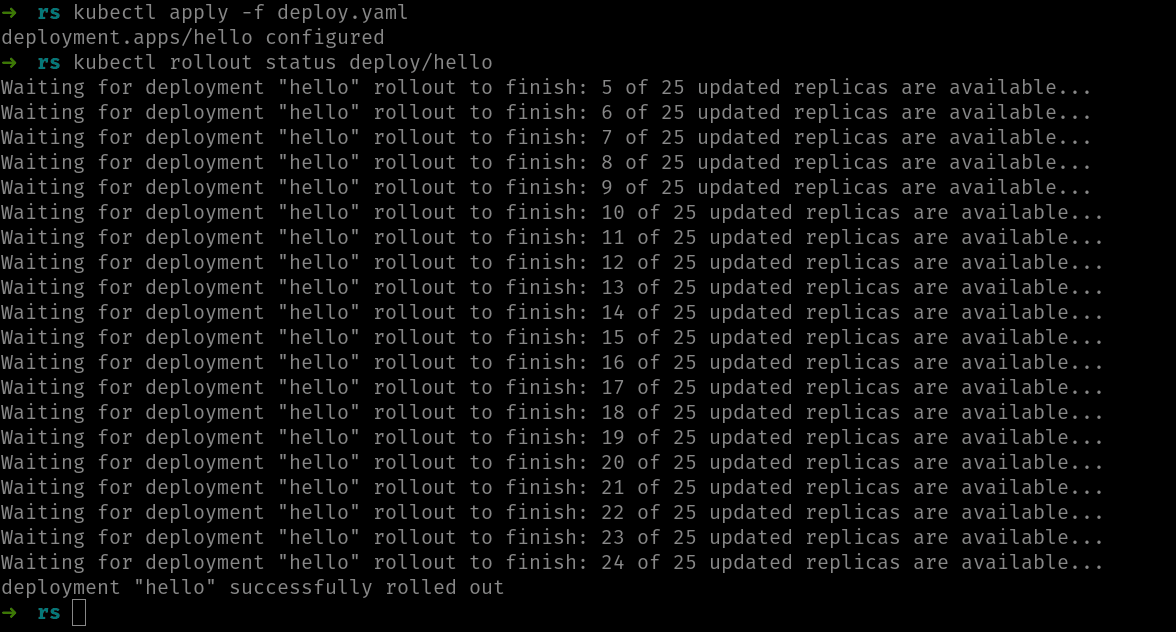
Si rolling update ha finalizado, el comando rollout status mostraría un mensaje similar a:
deployment "hello" successfully rolled out
Deployment se espera a que los nuevos pods estén ejecutando los contenedores antes de darlos por buenos (y continuar con el siguiente bloque). Si hay algún error que impida que los pods ejecuten sus contenedores, rolling update no estará finalizado y el comando rollout status se quedará esperando eternamente:

En esta imagen se ve el comando rollout status a la espera, donde indica que 13 de las 25 réplicas han sido actualizadas. En este caso hemos forzado un error poniendo una imagen inexistente, lo que impide a los pods ejecutarse. Si miramos los pods, veremos como hay un bloque de ellos que están en ImagePullBackOff/ErrImagePull:
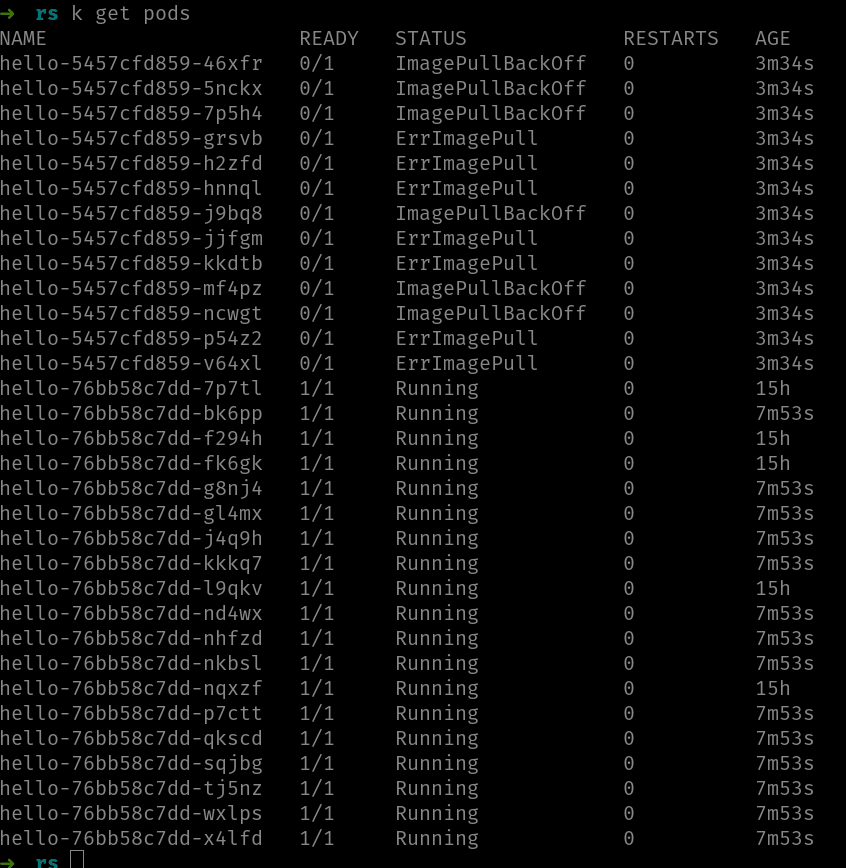
Algunos pods están ejecutándose y otros dan un error. Observa, además, como el primer de los dos sufijos del nombre (el que identifica el ReplicaSet) es distinto. En la imagen, los pods con el sufijo 76bb58c7dd son los viejos y los del sufijo 5457cfd859 son los nuevos. Dado que los nuevos no están pudiendo ejecutar su contenedor, deployment está a la espera, antes de seguir eliminando pods viejos.
Si usas el comando kubectl get rs verás ambos ReplicaSets:
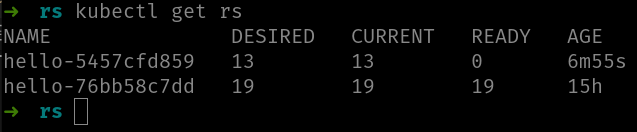
Observa cómo deployment ha configurado el ReplicaSet nuevo (hello-5457cfd859) para que tenga 13 instancias. Y actualmente ReplicaSet tiene esas 13, pero aquí la clave es la columna READY, que indica 0. Eso significa que no hay ninguna réplica que esté ejecutando el contenedor.
Realmente la columna READY no indica el número de pods que están ejecutando su contenedor, sino otra cosa ligeramente distinta: el número de pods “listos”. Un pod “listo” NO es lo mismo que un pod que esté ejecutando su contenedor, pero a esa diferencia llegaremos más adelante en el curso. Por el momento, puedes suponer que es lo mismo
En este punto es cuando intervenimos nosotros: o bien arreglamos el error y usamos otra vez kubectl apply para aplicar otro rolling update, o bien, ejecutamos un “rollback”.
Ojo, si modificas el YAML puede ser que el nuevo rolling update falle también. Por ejemplo, en este ejemplo hemos vuelto a modificar el YAML con otra imagen inexistente y hemos terminado con este escenario:
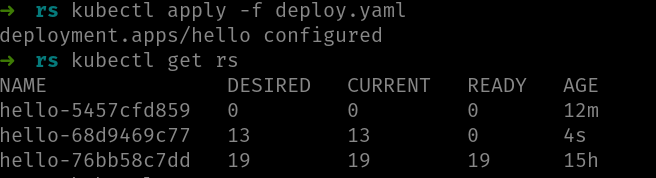
Observa bien la imagen porque es interesante:
- Inicialmente había 25 pods ejecutándose con ReplicaSet
hello-76bb58c7dd - El primer rolling update fallido crea el ReplicaSet
hello-5457cfd859- Este ReplicaSet (el nuevo) estaba escalado a 13 réplicas pero ninguna estaba ejecutando contenedor
- Hemos creado un segundo rolling update, también fallido que ha creado el ReplicaSet
hello-68d9469c77
Observa cómo deployment:
- Ha mantenido los 19 pods ejecutándose del primer ReplicaSet (el original). Esos no los tocará hasta que haya pods nuevos ejecutándose
- Ha escalado a 0 el ReplicaSet del rolling update anterior (el primer fallido)
- Ha escalado a 13 el ReplicaSet del nuevo rolling update y está esperando a que empiecen a ejecutar sus contenedores.
Rollbacks
Aunque un “rollback” es volver a la versión anterior, la verdad es que podemos volver a cualquier versión de todas las que haya (recuerda que, por defecto, deployment mantiene hasta 10 versiones (_ReplicaSets), pero que eso se puede modificar).
El comando kubectl rollout history nos indica las versiones de deployment:
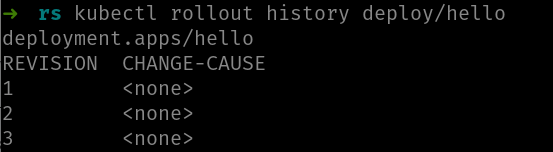
Puedes ver como hay tres revisiones. La columna CHANGE-CAUSE nos muestra que ha motivado la versión, pero ya te digo que si no haces nada, la verás siempre a <NONE> como en este caso. Más adelante te cuento qué hacer para que esta columna muestre algo útil.
Bien, en nuestro ejemplo estamos en la revisión 3 (la inicial más dos rolling updates fallidos). Por lo tanto, hacer un “rollback” a la versión justo anterior (la 2) no nos solucionará nada, ya que también es errónea. Pero como digo, nos podemos ir a cualquier versión mediante el comando kubectl rollout undo:
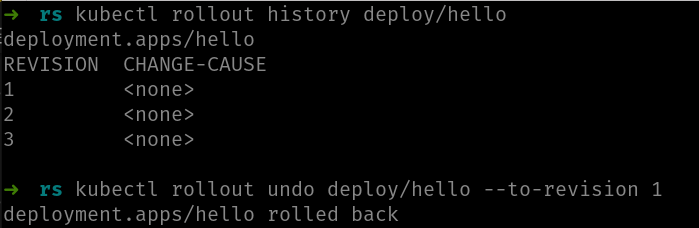
Observa el uso de --to-revision para indicarle a qué revisión queremos ir. En caso de omitirse dicho parámetro toma el valor de la versión justo anterior, a la que estamos.
Después de ejecutar ese comando, podemos mirar nuestros ReplicaSets y la salida es parecida a:
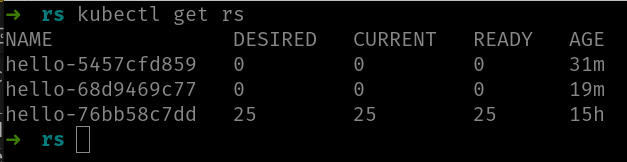
Observa como ahora es el ReplicaSet hello-76bb58c7dd el que tiene los 25 pods y todos ellos corriendo. Si miras las imágenes anteriores este es el ReplicaSet original. Hemos vuelto a la primera versión. También puedes ver que los otros ReplicaSets no son destruidos, es decir, podríamos volver a ellos si quisiéramos.
De hecho, el comando rollout undo crea una revisión nueva, por lo que ahora no estamos en la 3, si no en la 4:
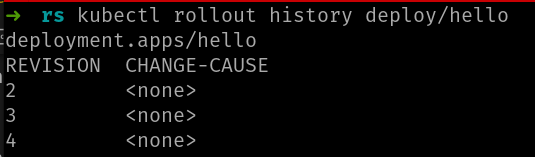
La revisión 1 ha desaparecido y en su lugar ha aparecido la 4. El hecho de que haya desaparecido es que el número de revisiones es siempre el de ReplicaSets, y el comando rollout undo no crea un ReplicaSet nuevo, sino que “promociona” uno existente al “actual” y eso se refleja en la lista de revisiones. La revision 1, se ha promocionado como la última y ahora es la 4.
La columna CHANGE-CAUSE
Como hemos mencionado antes, esa columna de la salida de kubectl rollout history nos muestra “la razón que ha provocado la actualización”, pero, por lo general, vale <NONE>, a no ser que explícitamente le des un valor al crear el rolling update.
El valor de esa columna se saca de la anotación kubernetes.io/change-cause que esté en deployment en cada momento dado.
¿Qué son las anotaciones? Las anotaciones son metadatos definidos en metadata.annotations y, al igual que las etiquetas, son parejas de clave-valor. A diferencia de las etiquetas una anotación NO se usa para nada específico (recuerda que las etiquetas son para seleccionar y categorizar objetos) y cualquier cliente puede usarlas como desee. En este caso kubectl la usa para mostrar el valor de esa columna.
Puedes añadir la anotación de forma manual de dos maneras.
La primera es usar el comando kubectl annotate:
kubectl annotate deploy/hello kubernetes.io/change-cause="volvemos atrás porque eso no va"
Y la segunda es editando el fichero YAML y añadir la anotación en metadata.annotations:
apiVersion: apps/v1 kind: Deployment metadata: name: hello annotations: kubernetes.io/change-cause: "volvemos atrás porque eso no va"
Y luego usas kubectl apply para aplicar el nuevo fichero. Eso NO genera una rolling update porque no modificas la plantilla del pod. Eso sí, asegúrate de estar usando el fichero YAML que se corresponde a la versión del deployment que tienes (si usas un fichero YAML de otra versión, la plantilla del pod será distinta y entonces sí que se generará el rolling update).
Uses el mecanismo que uses, al final este valor es el que se ve en el comando rollout history:
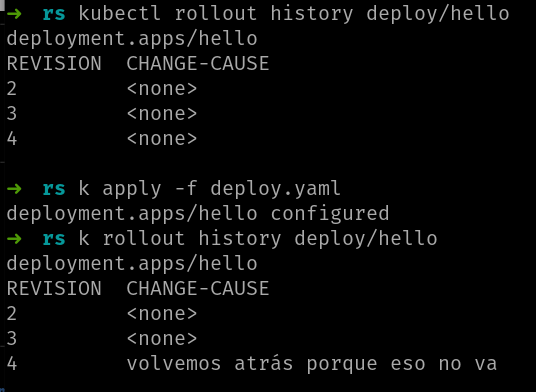
¡Listo! En esta lección has aprendido a usar el comando kubectl rollout para ver y manejar el estado de los rolling updates de un deployment.
Resumen del módulo
En este módulo hemos introducido los dos objetos de Kubernetes destinados a ejecutar aplicaciones (pods) sin estado. Por un lado ReplicaSet, que garantiza que siempre habrá N réplicas (pods idénticos) y, por otro lado, deployment, que usando varios ReplicaSets nos permite actualizar nuestra aplicación sin caída de servicio.
Si vas a desplegar una web, un servicio REST, una API… deployment debería ser tu opción. Entender cómo funciona deployment y la relación con ReplicaSet es fundamental.
ReplicationController
No quiero cerrar este módulo sin mencionar ReplicationController. Digamos que ReplicationController es la versión anterior de ReplicaSet. Si alguna vez te lo encuentras por ahí, que sepas que básicamente ReplicationController y ReplicaSet hacen lo mismo. La principal diferencia está en que el selector que usa ReplicaSet es más potente que el de ReplicationController, pero poco más.
El mecanismo recomendado hoy en día es usar deployments, que por debajo usan ReplicaSets, así que no hay ningún motivo para usar ReplicationControllers en la actualidad.