¡Esta es una revisión vieja del documento!
Tabla de Contenidos
Despliegues declarativos en Kubernetes
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
En los dos módulos anteriores hemos visto los fundamentos de Kubernetes. Hemos aprendido a usar kubectl y a crear pods para que ejecuten contenedores. Para finalizar hemos visto el concepto de servicios para agrupar pods bajo una misma IP “permanente”.
Para ello nos hemos valido de comandos como run, expose o label (para crear los pods, los servicios o modificar las etiquetas). Estos comandos se conocen como comandos imperativos, mediante los cuales le decimos exactamente a Kubernetes qué queremos que haga.
Pero la realidad es que los comandos imperativos se usan muy poco, ya que Kubernetes apuesta por un modelo declarativo en el cual nosotros “declaramos” distintos objetos y su estado final y dejamos que Kubernetes se encargue de llegar a dicho estado.
Además, los comandos imperativos están muy limitados: no es posible hacer con ellos varias tareas. Todavía no lo hemos visto, pero si quieres crear un pod que ejecute no uno, sino dos contenedores, no lo puedes hacer con kubectl run. Y ese es solo un ejemplo, hay muchos.
El uso del modelo declarativo se basa en usar ficheros que describen los objetos y el estado deseado y, por suerte o por desgracia (depende de como lo mires), esos ficheros son ficheros de configuración YAML.
Meme de YAML, con Woody y Buzz de Toy Story diciendo que hay YAML por todas partes
Al final de este módulo sabrás cómo crear despliegues declarativos en Kubernetes y estarás en disposición de aprender conceptos más avanzados, ¡necesarios para escenarios más complejos!
Uso de la configuración declarativa
Por configuración declarativa nos referimos al hecho de usar ficheros de configuración (YAML) para configurar Kubernetes en lugar de recurrir a comandos concretos de kubectl. Mediante estos ficheros vamos a poder crear cualquier objeto de Kubernetes.
Hay básicamente tres comandos de kubectl que se usan con el modelo declarativo:
create: crea el recurso indicado en el fichero YAML. Cualquier tipo de recurso se puede crear (da igual que sea un pod, un servicio o cualquier otro tipo de objeto).delete: elimina el recurso indicado en el fichero YAMl. Cualquier tipo de recurso se puede eliminar (da igual que sea un pod, un servicio o cualquier otro tipo de objeto).apply: aplica el estado definido en el fichero YAML. Puedes verapplycomo un upsert: Es decir, si el recurso definido por el fichero no existe, lo creará y si ya existe lo actualizará para que el estado del recurso coincida con el definido en el fichero YAML.
Debes tener presente que apply puede fallar si el recurso ya existe y las modificaciones necesarias para llevarlo al estado definido en el fichero YAML no son posibles. Hay ciertos campos de los objetos de Kubernetes que sólo se pueden establecer al crear un objeto e incluso hay objetos (como los pods) que son inmutables una vez creados. En estos casos apply te dará un error y deberás eliminar (delete) el recurso antes de aplicar el fichero otra vez (lo que creará el objeto, pues este ya no existe).
Desplegando ficheros en el clúster
Una vez tengamos los ficheros necesarios, lo más habitual es usar el comando kubectl apply para “desplegar” esos ficheros en el clúster. A esa operación es lo que llamamos “configuración declarativa”, para contraponerla con la “configuración imperativa” que hemos visto hasta ahora.
¡Un fichero YAML puede contener más de un documento YAML! Para separar documentos YAML dentro de un mismo fichero se usan tres guiones (---). Si tienes un fichero YAML que tenga varios documentos en él (por ejemplo, podría declarar un pod y el servicio), el comando apply desplegaría ambos recursos.
Por supuesto, ambos tipos de configuraciones son complementarias y se pueden usar simultáneamente. No se trata de que Kubernetes funcione o “en modo declarativo” o “en modo imperativo”. Se trata, simplemente, de dos maneras que tenemos de interaccionar con él para configurarlo.
Recuerda que los comandos imperativos no permiten crear todos los objetos posibles, ni tampoco configurarlos completamente. Eso significa que los comandos imperativos son ideales para hacer pruebas rápidas en el clúster. Pero, para desplegar aplicaciones, al final deberás recurrir al despliegue declarativo.
Cualquier objeto Kubernetes es representable mediante una descripción en YAML. No importa si se ha usado un fichero YAML para crearlo o se ha creado con cualquier otro comando. Es posible obtener la definición YAML de cualquier objeto existente en el clúster. Por ejemplo, este sería el código YAML del servicio hello-svc que creamos en el módulo anterior:
apiVersion: v1 kind: Service metadata: creationTimestamp: "2023-01-04T09:50:37Z" labels: run: hello name: hello-svc namespace: default resourceVersion: "545208" uid: 9912de05-50fc-42ee-8f2c-2cb7f4a5aed5 spec: clusterIP: 10.98.120.68 clusterIPs: - 10.98.120.68 internalTrafficPolicy: Cluster ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - port: 80 protocol: TCP targetPort: 80 selector: run: hello sessionAffinity: None type: ClusterIP status: loadBalancer: {}
Este código YAML viene a ser lo que Kubernetes guarda en su base de datos interna (generalmente es etcd.)
Sé lo que estás pensando: mucho código para algo que se puede crear con un comando como expose, ¿verdad? ¿De veras la gente de Kubernetes pretende que usemos esos ficheros para definir nuestros recursos? ¡Si son enormes! ¡Y llenos de valores raros!
Tranquilo, el problema es que, esta es la definición YAML que le hemos pedido al clúster que nos dé. Es decir, podemos obtener la definición YAML de cualquier objeto que esté en el clúster, da igual cómo se haya creado. Realmente, Kubernetes trabaja internamente con esas definiciones: aunque creemos el servicio con expose (comando imperativo) se transforma en este pedazo de YAML.
El problema de preguntarle la definición YAML de un objeto al clúster es que este nos lo devuelve todo, y realmente hay, por así decirlo, tres tipos de propiedades en los recursos:
- Propiedades obligatorias: estas hay que establecerlas sí o sí
- Propiedades opcionales: si no se establecen, el clúster les da un valor por defecto
- Propiedades “de salida”: estas no se establecen nunca, las establece siempre el clúster
Por ejemplo, en el caso que nos ocupa, status es una propiedad “de salida”, que mantiene Kubernetes y que nos indica cuál es el estado actual de este servicio. Nosotros no vamos a establecer esa propiedad al crear o actualizar el servicio (ni podríamos hacerlo). Luego, hay multitud de propiedades opcionales, pero que el clúster nos devuelve igualmente. Algunos ejemplos en este caso serían sessionAffinity o ipFamilyPolicy, por poner unos ejemplos. En resumen, cuando le pides al clúster que te dé una definición YAML, te devuelve toda la información que el clúster tiene sobre este objeto (y hay objetos como los pods que tienen muchísima información).
Así pues, la definición que nos da el clúster no es exactamente igual al fichero YAML que vamos a utilizar nosotros.
Pero es un buen punto de partida.
Obtener la definición YAML de un objeto
Seguramente te estarás preguntando cómo obtener esa definición YAML, ¿verdad? ¡Es muy sencillo! Sólo debes usar el modificador -o yaml en el comando get de kubectl:
kubectl get svc hello-svc -o yaml
Por supuesto en lugar de get svc puedes usar get pod o el recurso que necesites: todo recurso (absolutamente todo) que está en el clúster, tiene su definición YAML.
Espacios de nombres (namespaces)
Los espacios de nombres son como “grupos lógicos” de recursos de Kubernetes que están relacionados entre sí. Dos objetos del mismo tipo (por ejemplo, dos pods) pueden llamarse igual si están en espacios de nombres distintos. Por defecto objetos en un espacio de nombres no ven a los objetos de otro espacio de nombres. Así, por ejemplo, cuando un servicio selecciona pods los selecciona sólo de su mismo espacio de nombres, o cuando un pod hace referencia a un ConfigMap, este debe estar en el mismo espacio de nombres. Los espacios de nombres se crean para agrupar objetos en base a criterios que deseemos (por ejemplo, por aplicación, entorno, equipo, etc.). Todo objeto de Kubernetes pertenece a un espacio de nombres y, por defecto, cuando nos conectamos al clúster trabajamos con el espacio de nombres default.
El modificador -n <espacio-de-nombres> ejecuta cualquier comando contra el espacio de nombres indicado.
Puedes crear un espacio de nombres de forma imperativa o de forma declarativa. La forma imperativa consiste en usar el comando kubectl create ns <nombre-namespace>. La forma declarativa es usando un fichero YAML tal y como sigue:
apiVersion: v1 kind: Namespace metadata: name: campusmvp
Una vez tengas el espacio de nombres creados puedes crear objetos en él:
- Usando el modificador
-n <nombre-namespace>en cualquier comando dekubectl - Si el fichero yaml tiene la entrada
metadata.namespacese usará este espacio de nombres para el fichero yaml (a no ser que uses-ny especifiques otro).
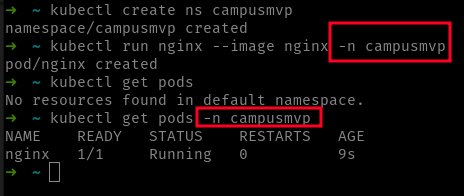
El uso de espacios de nombres te permite crear “grupos lógicos de objetos” en base a cualquier criterio que decidas (aplicación, grupo de trabajo, entorno, etc,…). Hay un par de cosas que debes tener presentes:
- Pueden existir dos objetos del mismo tipo con el mismo nombre en distintos namespaces. Por ejemplo, puede haber un pod llamado
nginxen el espacio de nombresdefaulty otro pod llamado igualmentenginxen otro espacio de nombres. Esos pods no tienen por qué ser idénticos. - En general el espacio de nombres actúa como de “barrera”. Por ejemplo, un servicio sólo seleccionará pods de su mismo espacio de nombres. En general, eso ocurre para casi todo: un objeto de Kubernetes en un namespace sólo interactúa con los objetos de su mismo espacio de nombres.
Puedes eliminar un espacio de nombres usando kubectl delete ns <espacio-de-nombres>. ¡Eso elimina cualquier recurso contenido en él!
Creando un pod de forma declarativa
Vamos a empezar por crear un pod pero de forma declarativa. Así empezarás a ver la estructura de los ficheros YAML.
Vamos a empezar por el final, es decir el YAML completo:
apiVersion: v1 kind: Pod metadata: labels: run: hello-declarative name: hello-declarative spec: containers: - image: dockercampusmvp/go-hello-world name: hello
Este fichero YAML es el fichero equivalente al comando kubectl run del módulo anterior. Las únicas diferencias son que hemos cambiado el nombre del pod (así puedes tener ambos a la vez) y el valor de la etiqueta run.
Ahora puedes usar apply para aplicar el fichero:
kubectl apply -f <nombre-fichero-yaml>
Si el pod hello-declarative no existe, puedes usar también kubectl create -f <nombre-fichero-yaml> para crearlo
Eso creará el pod hello-declarative ejecutando un contenedor de la imagen dockercampusmvp/go-hello-world.
El comando apply -f despliega un fichero YAML en el clúster. Si tienes un directorio con varios ficheros, puedes desplegarlos todos a la vez usando kubectl apply -f <nombre-carpeta> (por ejemplo, kubectl apply -f . si tienes los YAML en el directorio actual).
Secciones del archivo YAML
Por lo general los ficheros YAML casi siempre (hay algunas excepciones) tienen cuatro partes:
apiVersionkindmetadataspec
Por lo general las tres primeras tienen el mismo esquema en cualquier recurso, siendo la cuarta (spec) la que varía entre recursos.
apiVersion
Lo primero que tenemos es esto:
apiVersion: v1
Eso indica la versión de la API de Kubernetes que vamos a usar para definir el objeto. La API de Kubernetes está versionada y van apareciendo distintas versiones con el tiempo. En este caso usamos la v1. Un mismo tipo de objetos puede estar asociado a más de una versión de la API. Por supuesto el clúster debe ofrecer dicha versión.
¡Ojo con este punto! A medida que van apareciendo nuevas versiones de Kubernetes, algunos objetos se pueden promocionar a una nueva versión de la API. Generalmente, los objetos se promocionan de versiones beta (tales como v1beta1) a versiones “finales” (tales como v1). Por ejemplo, existe un objeto (que veremos en breve), llamado deployment que cuando apareció estaba en la API extensions/v1beta1. Posteriormente, se cambió a apps/v1beta1, luego a apps/v1beta2 y, finalmente, a apps/v1. Ahora bien, una versión específica de Kubernetes, no es que soporte un determinado recurso (por ejemplo, este deployment del que hablamos) en una determinada versión. En lugar de eso, una versión específica de Kubernetes (por ejemplo, la 1.14) soporta un conjunto de versiones de API (tales como extensions/v1beta1 y apps/v1beta2). Por lo tanto, si tu versión de Kubernetes soporta la versión de la API indicada por el campo apiVersion, no tendrás problema alguno: cuando se soporta una apiVersion se soporta toda entera. Lo que puede ocurrir es que una versión nueva de Kubernetes deje de soportar una apiVersion muy antigua, por lo que en este caso sí que deberías actualizar los ficheros YAML. Volviendo al ejemplo de los deployments: En Kubernetes 1.15 se les considera un recurso de la versión de la API apps/v1. Pero si tu Kubernetes 1.15 sirve la versión de la API extensions/v1beta1, un fichero YAML que use un deployment y que tenga ese valor en apiVersion te funcionará sin problemas. El problema vendrá si esta versión de la API no está servida por el clúster. El comando kubectl api-versions te indica todas las versiones de la API servidas por el clúster.
Por ejemplo, recuerda que hemos comentado que el objeto Deployment pasó de estar en extensions/v1beta1 a apps/v1beta2 para finalmente estar en apps/v1. Como se ha mencionado, versiones más nuevas de Kubernetes eliminan APIs viejas, así, la API extensions/v1beta1 se eliminó en Kubernetes 1.16, tal y como se detalla en este enlace. Eso significa que un fichero YAML que declare un Deployment usando extensions/v1beta1 no funcionará en Kubernetes 1.16 o posterior.
En el módulo dedicado a la API de Kubernetes explicaremos esto con un poco más de detalle.
Todas las versiones que no sean alpha o beta se consideran finales (GA) y siempre estarán soportadas. Por ejemplo, fíjate en el ejemplo del pod, que está en v1. Esto es una versión final y nunca será eliminada.
Kind
La sección kind contiene una cadena que indica el tipo de recurso especificado en el fichero. En nuestro caso, un pod.
La combinación de kind y apiVersion le dice al clúster qué tipo de recurso y en qué versión está, el recurso especificado en el fichero.
Metadata
En la sección de metadata se definen los metadatos del objeto. Entre ellos el obligatorio es el nombre (name). En nuestro ejemplo se definen también las etiquetas (labels).
metadata: labels: run: hello name: hello
Spec
La sección spec contiene la especificación o definición del objeto. Su esquema depende, claro, del tipo y versión del objeto. En este caso, especificamos que el pod tiene un contenedor que ejecuta la imagen dockercampusmvp/go-hello-world:
spec: containers: - image: dockercampusmvp/go-hello-world name: hello
Observa que, en este caso, spec.containers es un array de valores. Eso lo puedes saber porque el primer valor empieza con un guion (-). Eso define un array (containers) con un solo valor, que es un objeto con dos propiedades (image y name). ¡Es importante que te familiarices con la lectura de YAML porque vas a ver muchos ficheros YAML en el curso!
Eliminar objetos
Si tienes un fichero YAML puedes borrar todos los objetos definidos en él con el uso de kubectl delete -f <fichero>. Eso borrará todos los recursos definidos en el fichero (sean del tipo que sean).
El comando delete -f se fija sólo en el kind y en metadata.name para borrar el objeto. Es decir:
- Si tienes un pod llamado
foo(creado conkubectl run) y tienes un fichero YAML que define un pod llamadofoo:delete -feliminará el podfoo
- Si tienes un fichero YAML que define un pod llamado
fooy has usadoapply -f:delete -feliminará el podfoo
- Si tienes un fichero YAML que define un pod llamado
fooy has usadoapply -fy luego editas el fichero YAML para quemetadata.nameseabar:delete -fNO borrará el podfoo(porque ahora el fichero YAML define un pod llamadobar).