Tabla de Contenidos
Pods y servicios
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
En el módulo anterior viste qué era Kubernetes, cómo instalar uno local usando Minikube y empezar a operar con él, terminando con la creación de un pod para ejecutar un contenedor.
Al final viste que un pod es la unidad mínima de despliegue en Kubernetes. Pero no profundizamos mucho en ellos. En este módulo veremos algunas cosas más sobre los pods.
¡Vamos allá!
Errores al crear pods
El comando run crea un pod y le indica a dicho pod que debe ejecutar un contenedor de la imagen indicada. Pero crear el pod y que este empiece a ejecutar un contenedor son tareas separadas y el comando run se espera sólo a la primera. Eso significa que cuando el comando finaliza, el contenedor todavía no se está ejecutando.
Una vez el pod ha sido creado, Kubernetes debe hacer varias cosas:
- Elegir en qué nodo se ejecutará dicho pod. Esa es la fase de planificación y es el planificador (o scheduler en su voz inglesa) el responsable de tomar dicha decisión. Más adelante verás qué tiene en cuenta el planificador y cómo afectar a sus decisiones.
- Una vez el nodo es elegido, es el kubelet de dicho nodo quien toma el control y empieza a crear el contenedor. Para ello debe:
- Obtener la imagen OCI si esta no existe ya (es decir el equivalente a
docker pull) - Enlazar posibles recursos externos que el contenedor declare (por ejemplo, almacenamiento externo)
- Poner en marcha el contenedor
Cualquiera de esos pasos puede fallar y en todos ellos el pod estará creado y el comando kubectl run habrá funcionado correctamente, pero tu contenedor no se estará ejecutando.
Ojo con eso, especialmente si usas kubectl run desde un fichero de script y usas el exit code para establecer si el comando ha funcionado o no. Puede haber casos que el exit code sea correcto, ¡pero eso no significa que el contenedor esté en marcha!
A continuación te comento los dos errores más típicos que te vas a encontrar. No son los únicos e irás viendo más a medida que el curso avance.
Error al obtener la imagen
Si por cualquier motivo, el kubelet no puede obtener la imagen (porque realmente no existe, o está en un registro privado y no tiene las credenciales correctas, o por cualquier otro motivo) el pod emitirá un estado de ErrImagePull y luego entrará en ImagePullBackOff. Esos dos estados se irán alternando:
ErrImagePullsignifica que kubelet ha intentado obtener la imagen y no ha podido (por la razón que sea)ImagePullBackoffsignifica que kubelet se está esperando a intentar obtener la imagen de nuevo
Es importante que veas que el kubelet nunca parará de intentar obtener la imagen, pero entre intento e intento alterna un periodo de tiempo en el que se queda a la espera. Mientras esté en este periodo el estado será ImagePullBackOff. Por eso se van alternando: a cada ErrImagePull le sigue un ImagePullBackOff, y la duración de este último es cada vez mayor.
Observa la imagen siguiente: puedes ver como se intenta crear un pod con una imagen llamada noexiste (que no existe en realidad). El comando kubectl run funciona correctamente, y Kubernetes indica que el pod ha sido creado. Pero, como hemos comentado, ¡eso no significa que el contenedor esté corriendo! Si luego ejecutamos un kubectl get pods podremos ver el error:
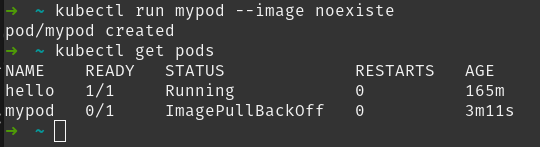
Puedes observar como el pod mypod está en ImagePullBackOff indicando que no ha podido obtener la imagen del contenedor.
Si necesitamos más información, hay un comando que nos da los detalles de todos los eventos relevantes que han sucedido en un objeto de Kubernetes. Es el comando kubectl describe. Este comando da mucha información (que ya irás aprendiendo a entender, no te preocupes), pero por ahora nos importa sólo la última sección llamada EVENTS. Así, si tecleamos kubectl describe pod mypod saldrá diversa información por el terminal y, al final, está la sección de EVENTS, que en mi caso es como se puede ver en la imagen:

Aquí puedes ver todos los eventos (el más antiguo en la parte superior). En este caso hay los siguientes eventos:
Successfully assigned default/mypod to minikube: el planificador indica que ha seleccionado un nodo para el podPulling image “noexiste”: el kubelet informa de que empieza a obtener la imagennoexisteFailed to pull image “noexiste”: el kubelet informa de un error al obtener la imagennoexisteError: ErrImagePull: el pod entra en estadoErrImagePullError: ImagePullBackOffError: el pod entra en estadoImagePullBackOffBack-off pulling image “noexiste”: el kubelet se está esperando hasta intentar obtener la imagen de nuevo
Puedes observar en la imagen como algunos de los eventos han sucedido varias veces (tienen etiquetas tipo x4 over 6m43s). La sección de eventos de kubectl describe es uno de los primeros lugares donde se debe recurrir cuando hay cualquier problema.
Error al iniciar el contenedor
Si el contenedor se puede iniciar correctamente, pero por cualquier razón termina, el pod intentará reiniciarlo. Si de nuevo termina, lo reiniciará otra vez y así eternamente. En este caso el pod irá alternando los estados:
Runningmientras el contenedor se está ejecutandoErroroCompletedcuando el contenedor termina (con error o correctamente)CrashLoopBackOffcuando el kubelet se está esperando a reiniciar el contenedor. Este tiempo va aumentando paulatinamente.
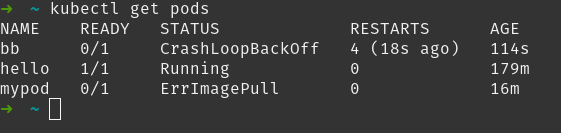
En la imagen anterior puedes ver como tenemos un pod llamado bb que está en CrashLoopBackOff. Además Kubernetes nos informa del número de veces que ha reiniciado el contenedor (4 en nuestro ejemplo) y del tiempo del último reinicio (18 segundos).
Por defecto un pod reinicia su contenedor cuando este termina, ya sea correcta o incorrectamente
Espacio de red de un pod
En la sección de Docker viste que cada contenedor tiene su propio espacio de red. Eso es, cada contenedor obtiene su propia IP, tiene su rango de puertos y localhost dentro de un contenedor, es el propio contenedor.
Bien, en Kubernetes nada de eso es así.
Espacio de red de un pod
En Kubernetes son los pods los que tienen el espacio de red, eso implica básicamente tres puntos:
- Son los pods y no los contenedores los que tienen IP
- Los puertos pertenecen a los pods, no a los contenedores. Si un contenedor abre el puerto X, abre el puerto X del pod.
- localhost no se refiere al propio contenedor si no al pod.
Recuerda que la relación entre contenedores y pods no tiene por que ser 1:1. Los pods pueden ejecutar varios contenedores. En este caso, se podrían comunicar entre ellos usando localhost.
Puedes ver la IP de un pod añadiendo el modificador -o wide a la salida de kubectl get pods:

La IP de un pod es privada y no se puede usar desde fuera del clúster.
El modificador -o wide te puede mostrar otros campos como NOMINATED NODE y READINESS GATES. Se trata de aspectos más avanzados, que por ahora vamos a obviar.
Comunicando pods
Si sabes la IP de un pod no hay nada que te impida usarla desde un contenedor que se está ejecutando en otro pod. Vamos a ver un ejemplo rápido usando dos pods: uno con un contenedor que ejecute la imagen dockercampusmvp/go-hello-world y otro con un contenedor de busybox.
La imagen busybox es una imagen de Docker que contiene muchas utilidades Linux y que se usa mucho para depurar y encontrar problemas. Si quieres más información consulta la página oficial del proyecto.
Creando el pod que ejecute dockercampusmvp/go-hello-world
Esta parte te la dejo como ejercicio, porque a estas alturas ya la has visto algunas veces. Se trata de crear un pod llamado hello que ejecute un contenedor de la imagen dockercampusmvp/go-hello-world.
Si tienes algún problema te dejo aquí el comando a usar:
kubectl run hello --image dockercampusmvp/go-hello-world
Una vez esté el pod creado y el contenedor en marcha, usa el comando kubectl get pods -o wide para obtener la IP. La salida será algo parecida a:
NAME READY STATUS RESTARTS AGE IP NODE hello 1/1 Running 0 8s 172.17.0.8 minikube
Si el estado del pod no es Running y READY no es 1/1 es que hay algún problema. En este caso, elimina el pod, revisa el comando para crearlo y créalo de nuevo
Ejecutando el pod de busybox
Vamos ahora a ejecutar un pod con un contenedor de busybox. Primero te pongo el comando, ya que verás varios modificadores adicionales y así aprovecho y te los comento:
kubectl run bb --image busybox --rm --restart=Never -it -- /bin/sh
Vayamos por partes, pues ¡parece un comando complejo pero no lo es en absoluto!
- La primera parte (
run bb --image busybox) ya la conoces: crea un pod llamadobbque ejecuta la imagenbusybox --rmes para eliminar el pod una vez este termine de ejecutarse--restart=Neveres para que el pod no intente reiniciar el contenedor nunca-ites para enlazar nuestro terminal al del contenedor (igual que en el caso dedocker runodocker exec)-- /bin/shes para ejecutar este comando como entrypoint del contenedor. En este caso el shell de Linux
Para conectarnos a un pod: kubectl exec -it <NOMBRE_POD> -- /bin/sh, por ejemplo
Una vez ejecutado este comando, tu terminal se enlaza al del contenedor y verás un prompt de Linux:

Ahora tu terminal, es el terminal de busybox, que se está ejecutando como un pod dentro del clúster. Si tecleas wget -qO- http://<ip-del-pod-hello> en este terminal, el pod hello te debería responder:
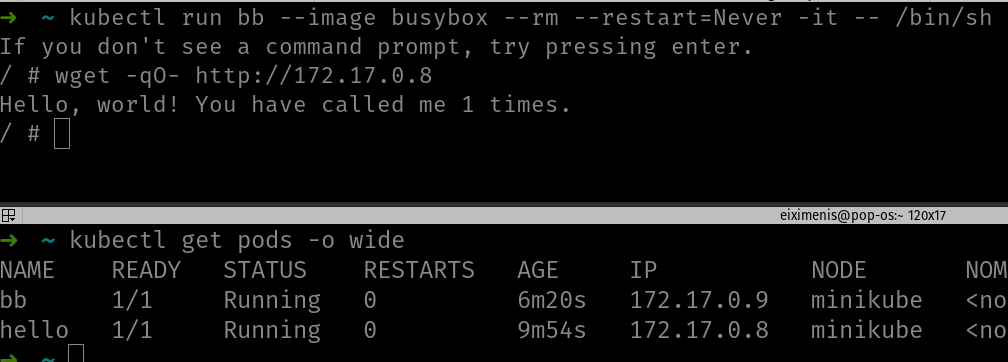
En la imagen puedes ver dos terminales. En el superior se enlaza a busybox y se ejecuta el comando wget y puedes ver cómo responde el otro contenedor. En el terminal de abajo, simplemente hay el resultado de get pods donde puedes ver ambos pods ejecutándose.
Si ahora tecleas exit en el terminal enlazado, el contenedor de busybox termina (ya que el proceso principal, el shell de Linux termina) y como pusimos restart=Never el pod no reiniciará el contenedor. Como además pusimos --rm, el pod se borrará automáticamente.
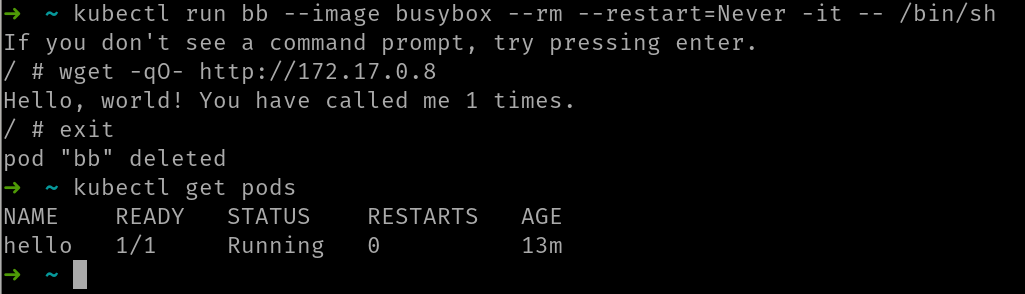
Como puedes ver en la imagen, al teclear exit aparece el mensaje pod “bb” deleted.
Restart policy
En el ejercicio anterior, cuando ejecutamos busybox añadimos el modificador restart=Never y comenté que era para que el pod no reiniciara el contenedor en ningún caso.
Por defecto, un pod va a reiniciar siempre el contenedor (aunque este termine correctamente), porque asume que el contenedor siempre debe estar en marcha. Así, si despliegas un servicio como un pod y tu contenedor termina por una excepción, el propio pod lo reiniciará. Este es el comportamiento por defecto.
Cuando hablamos de restart policy o política de reinicios, nos referimos precisamente a eso: a cuando queremos que el pod reinicie el contenedor. Y hay tres posibilidades:
- Nunca
- Siempre
- Sólo si el contenedor termina en caso de error
El modificador --restart de kubectl run te permite modificar esta política y puede tener tres valores, para cada uno de las posibilidades anteriores:
NeverAlways(valor por defecto)OnFailure
Más adelante hablaremos del ciclo de vida de los pods y profundizaremos un poco más en este asunto.
Servicios
Los pods en Kubernetes son considerados objetos completamente transitorios: pueden “morir” en cualquier momento. Cuando esto ocurre, según el caso, es posible que Kubernetes cree otro pod nuevo que reemplaza al anterior. El tema está en que cada pod tiene asignada una “IP virtual”, pero no hay garantía alguna de que si un pod muere, el pod que lo reemplace tenga la misma “IP virtual”.
Por ello, necesitamos un mecanismo que nos proporcione un acceso fiable a los pods. Fiable en el sentido de que nos ofrezca un único punto de entrada (una única “IP virtual”) y que esta no cambie si los pods subyacentes “mueren” y son reemplazados por otros nuevos. Este mecanismo son los servicios.
Quédate con la idea de que un pod puede terminar en cualquier momento, pero no lo asocies con que “si falla un contenedor, falla el pod”. ¡Recuerda que los pods pueden reiniciar sus contenedores! En un módulo posterior hablaremos con más detalle del ciclo de vida de los pods.
Qué es un servicio
Un servicio es un objeto de Kubernetes que engloba un conjunto de pods y las políticas para acceder a ellos. Los pods que engloba no son pods concretos (ya que estos pueden desaparecer en cualquier momento), sino cualquier pod (presente y futuro) que cumpla una determinada condición.
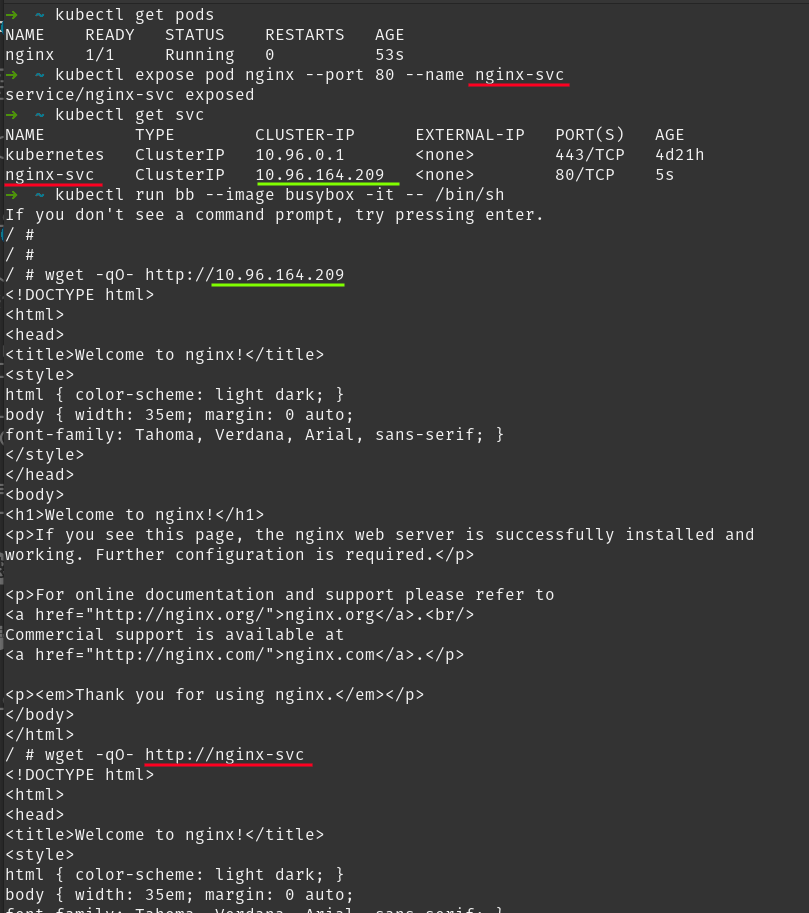
Para crear un servicio puedes usar el comando kubectl expose:
kubectl expose pod <nombre-pod> --name <nombre-servicio> --port <puerto>
Este comando crea un servicio, llamado <nombre-servicio> para exponer el pod llamado <nombre-pod> por su puerto <puerto>. Si omites el modificador --name, entonces el servicio tendrá el mismo nombre que el pod.

En la imagen puedes ver cómo se usa kubectl expose para crear un servicio llamado hello-svc. Este servicio expone el pod hello, lo que significa que todas las llamadas al servicio serán redirigidas al pod.
Esto lo puedes comprobar viendo cuál es la IP del servicio. Para ello usa el comando kubectl get services (puedes usar la abreviatura svc):

El servicio hello-svc tiene la IP 10.96.0.1. Esta IP es interna del clúster (no accesible desde fuera) y se conoce con el nombre de ClusterIP.
Selectores de un servicio
Un servicio puede agrupar bajo su paraguas a varios pods en un mismo momento. En el vídeo anterior, el escenario era de uno a uno (en todo momento sólo existía un pod bajo el servicio), pero eso no tiene por qué ser así.
Es más: los pods no tienen ni porqué ser idénticos: podrían ejecutar contenedores de imágenes distintas, aunque seguramente esto no es lo que habitualmente querrás, permite escenarios interesantes que más adelante detallaremos.
Seguramente te estás preguntando cómo elige un servicio a los pods que engloba. Si recuerdas, el nombre de un pod es único, pero como se ha dicho, un servicio puede tener a la vez varios pods por debajo. Entonces, está claro que el servicio no puede usar el nombre del pod.
Entonces… ¿qué usa?
Eso nos lleva a hablar de las etiquetas, que no son nada más que metainformación que se puede añadir a los objetos de Kubernetes (como lo son los pods). Tienen la forma “clave, valor”, así pues, se puede poner una etiqueta cuyo nombre (clave) sea, por ejemplo, svc y cuyo valor sea frontend. Los nombres de las etiquetas (en este caso svc) son completamente arbitrarios y sin especial significado para Kubernetes. Se puede indicar que cualquier pod que se cree tenga determinadas etiquetas (las que se quiera) con determinados valores (los que se quiera).
Por tanto, cuando creamos un servicio podemos indicar que agrupe todos los pods que tengan determinadas etiquetas con un determinado valor. A partir de ese momento, esos pods quedarán “bajo el paraguas” del servicio que ofrecerá una “IP virtual” única para acceder a ellos. Además, recuerda que esta “IP virtual” no cambiará, por más que los pods subyacentes sí lo hagan. El servicio es el encargado de enrutar las peticiones que llegan a su “IP virtual”, a la “IP virtual” del pod. Es decir, un servicio actúa como proxy inverso para los pods subyacentes.
El concepto de etiqueta es importante en Kubernetes. Por lo general, casi cualquier objeto de Kubernetes (un pod, un servicio, un deployment y muchos otros más) puede contener una o más etiquetas con valores arbitrarios (que defines tú). Estas etiquetas (pares clave,valor) no tienen significado para Kubernetes, pero sirven para “agrupar” y “categorizar” los objetos. Y, también, permiten “seleccionar grupos” de objetos (por ejemplo, todos los pods que tengan determinada etiqueta con determinado valor). Por ello, en muchos casos se usan para seleccionar objetos, tal y como hacen los servicios.
El comando kubectl label te permite añadir, eliminar o modificar una etiqueta de cualquier recurso y el modificador --show-labels en el comando kubectl get te permite ver las etiquetas del recurso:
kubectl get pods --show-labels
Para modificar una etiqueta:
kubectl label pod hello2 run=hello --overwrite
Por defecto, no se pueden sobrescribir etiquetas, solo crear o borrar.
Servicios y DNS
Los servicios crean una entrada DNS en el servidor interno de DNS de Kubernetes. Esa entrada DNS tiene el nombre del servicio, lo que significa que (al igual que ocurre con compose) podemos usar el nombre del servicio, en lugar de su IP.
El servidor de DNS de Kubernetes es un componente opcional, pero sería muy raro que te encontraras con un Kubernetes que no lo tuviese habilitado
¿Qué es realmente un servicio?
Ahora que ya sabes lo que es un servicio, te voy a contar lo que es de verdad. Es decir, cómo funciona internamente. Cómo lo hace Kubernetes para redirigir las peticiones de la IP del servicio a uno de los pods que tenga por debajo.
Lo primero que te puedo decir es que un servicio NO ocupa CPU ni memoria y un servicio no es un proceso que se ejecute y que, por lo tanto, pueda fallar o quedarse colgado. Los servicios son algo mucho más sencillo y se basan en una característica del kernel de Linux llamada IP tables.
Básicamente las IP tables son reglas que le indican al kernel de Linux como debe tratar las llamadas a ciertas direcciones IP. Una de las cosas que permiten es redirigir las llamadas a una IP a otra IP distinta. Y de eso se aprovecha Kubernetes para implementar los servicios: cuando se crea un servicio Kubernetes actualiza todas las IP tables de todos los nodos del clúster para que las llamadas que se hagan a la IP del servicio sean redirigidas a cualquiera de las IPs de los pods que están bajo el paraguas del servicio. Kubernetes monitoriza en todo momento el estado de los pods y actualiza las IP tables automáticamente en cada caso.
De este modo, es el kernel de Linux quien hace el resto: así los servicios no pueden colgarse ni ocupan memoria o procesador. Porque, realmente, no hacen nada: ¡sólo son configuración del kernel de Linux de los nodos!
Este post lo explica de forma mucho más detallada, aunque si tienes interés te recomiendo que lo leas más adelante: asume algunos conocimientos a los que todavía no has llegado.
Ciclo de vida de un pod
A lo largo de un ciclo de vida, un pod puede pasar por varias fases:
- Succeeded: el pod se ha ejecutado correctamente
- Running: el pod se está ejecutando
- Failed: el pod se ha ejecutado con algún error
- Pending: el pod debe empezar a ejecutarse (sus contenedores no han sido creados todavía)
- Unknown: el estado del pod no se puede obtener. Esto es debido generalmente a algún error de comunicación con el nodo que hospeda el pod
No confundas la fase en la que está el pod con el estado de sus contenedores, ni tampoco con el valor que te da kubectl en la columna STATUS en el comando get pods.
Políticas de reinicio
Como viste antes, en este mismo módulo, el valor de restartPolicy del pod te permite establecer la política de reinicio de este pod.
Cuando usas kubectl run para crear un pod el modificador --restart te permite establecer la política de reinicio
Esta política de reinicio afecta a qué fases puede llegar el pod. Por ejemplo, en casos de pods que ejecuten un solo contenedor y que este finalice correctamente:
- Si el valor de
restartPolicyesAlwaysel contenedor se reinicia y el pod sigue en la fase Running. El valor de “Restarts” del pod se incrementa. - Si el valor de
restartPolicyesOnFailureel pod finaliza en la fase Succeeded. - Si el valor de
restartPolicyesNeverel pod finaliza en la fase Succeeded.
Por otra parte, si el contenedor finaliza con error:
- Si el valor de
restartPolicyesAlwaysel contenedor se reinicia y el pod sigue en la fase Running. El valor de “Restarts” del pod se incrementa. - Si el valor de
restartPolicyesOnFailureel contenedor se reinicia y el pod sigue en la fase Running. El valor de “Restarts” del pod se incrementa. - Si el valor de
restartPolicyes Never el pod finaliza en la fase Failed.
Por otra parte, si el pod tiene más de un contenedor, el ciclo de vida puede ser más complejo, pero lo interesante es observar lo siguiente:
- El valor de
restartPolicyindica bajo qué circunstancias se reinicia un contenedor - Siempre se reinician contenedores, nunca pods. Mientras los contenedores se reinician, la fase del pod es Running
Un pod puede estar en fase Running pero ningún contenedor ejecutándose. Por ejemplo, un pod que está continuamente reiniciando su contenedor (porque da error nada más empezar). El contenedor (casi) nunca se está ejecutando, pero el pod está en fase Running. Y el comando get pods te indicará el estado CrashLoopBackOff. Esos estados que te indica get pods no son fases del pod, son “seudoestados” que te indica kubectl.
Un pod puede terminar en la fase Failed por otras razones, como por ejemplo un fallo de disco o de máquina. En este caso, si el pod ha sido creado a través de un controlador será recreado en otra parte.
Ejemplo
Vamos a ver un ejemplo en acción. Para ello vamos a usar la imagen dockercampusmvp/explode:v1 que es un contenedor que arranca y termina, produciendo una excepción, al cabo de un determinado periodo de tiempo. Puedes usar la variable de entorno seconds para establecer el número de segundos antes de que termine abruptamente el contenedor. Si no estableces un valor, se asumen 10 segundos.
Nota: puedes descargar el código fuente (Explode_v1.zip). Se trata de un proyecto de consola realizado en .Net Core. El Dockerfile es multi-stage build, por lo que puedes compilarlo y crear la imagen Docker sin necesidad de tener el SDK .Net Core instalado.
Lo que debes hacer es crear un pod que ejecuta la imagen dockercampusmvp/explode:v1. Recuerda que para crear un pod usamos el comando kubectl run.
Si ahora vas siguiendo el valor de kubectl get pods verás que el valor de la columna STATUS va alternándose entre Running, Error y CrashLoopBackOff. Esto es porque el contenedor “revienta” a los 10 segundos, por lo que Kubernetes reinicia el contenedor (ya que el valor de restartPolicy es Always, que es el valor por defecto). El valor de CrashLoopBackoff significa que el pod está a la espera de que Kubernetes reinicie el contenedor y este reinicio tarda cada vez más (Kubernetes se espera cada vez más a reiniciar el contenedor). Una vez el tiempo de espera que corresponda haya transcurrido, el contenedor se pone en marcha y el pod vuelve al estado de Running. En cada uno de esos ciclos el valor de RESTARTS se incrementa.
El valor de la columna STATUS que se obtiene con kubectl get pods no es la fase del pod (por ejemplo CrashLoopBackoff no es un valor de fase de pod).
Si usas el comando kubectl get pod <nombre_pod> -o json verás la descripción del pod en formato JSON. El valor de la fase está en el campo phase dentro de status. Por otro lado, el array containerStatuses dentro de status te da el estado de cada contenedor.
Ahora podemos usar JSON Path para comparar el valor de fase del pod con el valor del estado del contenedor:
kubectl get pods <nombre-pod> -o jsonpath="Name: {.metadata.name} Status: {.status.phase} Container: {.status.containerStatuses[0].state..reason}"
El modificador -o jsonpath te permite obtener valores a partir del JSON y filtrarlos. La sintaxis básica es muy simple (en el enlace anterior tienes todos los detalles):
- Una
.claveentre llaves devuelve el valor de dicha clave. Así,{.status}devuelve el valor del campo “status” y{.status.phase}el valor del campo “phase” dentro de “status”. - Si tenemos arrays es posible usar la notación de índice. Así
{myArray[0]}devuelve el primer valor del arraymyArray. - Si quieres “saltarte” una clave puedes usar dos puntos. Así
{.status.containerStatuses[0].state..reason}te devuelve el valor de:- El campo
reasonque está… - … dentro de cualquier otro campo que está…
- … dentro del campo
state… - … en el primer elemento del array
containerStatuses… - … dentro del elemento
status
No te preocupes si por ahora no tienes claro que claves y campos existen en la definición de un pod. En breve introduciremos el despliegue declarativo y será entonces cuando empecemos a ver todos esos conceptos.
Pods y nodos
Cuando se crea un pod Kubernetes debe decidir en qué nodo se ejecuta dicho pod. Esta decisión es importante, ya que actualmente Kubernetes no soporta mover un pod entre nodos.
El componente de Kubernetes que realiza esa asignación es el scheduler (planificador) y para hacerlo toma en consideración varios aspectos:
- La carga de los nodos (uso de CPU, Memoria,…)
- Los recursos que el pod declara necesitar.
- Declaraciones adicionales de los pods y los nodos.
Los dos primeros puntos los veremos más adelante en detalle (cuando hablemos de recursos), así que por ahora basta con saber que el scheduler intenta repartir la carga entre los nodos, garantizando a la vez que todo pod obtiene los recursos que necesita.
El scheduler es el componente del control plane (se ejecuta en los nodos master) que se encarga de decidir en qué nodo debe ejecutarse un pod. Para ello, en primer lugar selecciona de entre todos los nodos aquellos que pueden ejecutar el pod y luego de todos los nodos resultantes, elige uno. Si, por cualquier motivo, el scheduler no puede encontrar ningún nodo para ejecutar el pod, este quedará en pending
En esta lección nos vamos a centrar en el tercer punto: de qué manera un pod puede definir preferencias entre los distintos nodos susceptibles de ejecutarlo.
Taint (mancha, contaminado)
Este es el primer concepto que vamos a ver. Consiste en, como su nombre indica, literalmente contaminar o manchar un nodo. Todo nodo que tenga una mancha no puede ejecutar pods. Es como decirle al scheduler: “No coloques ningún pod en este nodo”.
Puedes aplicar y quitar una mancha a un nodo en cualquier momento (usando el comando kubectl taint). Eso plantea una cuestión: ¿qué ocurre si manchamos un nodo que ya está ejecutando pods? La realidad es que depende del tipo de mancha que tenga el nodo, ya que no todas son iguales. Veamos cómo funciona el comando kubectl taint:
kubectl taint node <nombre-node> <clave>=<valor>:<efecto>
<nombre-nodo>: nombre del nodo a manchar. Conkubectl get nodeslistas los nodos del clúster<clave>=<valor>: el nombre de una mancha siempre tiene la forma clave=valor. Por ejemplo, un nombre válido seríaos=linux.<efecto>: puede serNoScheduleoNoExecute. Si se añade el símbolo menos al final (por ejemplo,NoSchedule-) se elimina la mancha.
El efecto define qué afectación tiene dicha mancha sobre los pods que se estén ejecutando en el nodo cuando se aplica:
NoSchedule: el scheduler no ejecutará nuevos pods en este nodo, pero los pods existentes se seguirán ejecutando.NoExecute: el scheduler no ejecutará nuevos pods en este nodo y los pods existentes serán desalojados (evicted) del nodo. Desalojar un pod significa que sus contenedores se detienen y si el pod estaba controlado por un deployment, ese deployment creará otro pod nuevo para reemplazar al desalojado.
Tolerancias (tolerations)
Las tolerancias, a veces (mal) llamadas “tolerancias”, se aplican a los pods y permiten que un pod se ejecute en nodos, aunque estos tengan una determinada mancha. Son pues, una manera de decirle al scheduler “Para este pod en concreto, ten en cuenta también todos los nodos que tengan esta mancha en particular”.
Cada toleration tolera una mancha o bien un grupo de manchas. Las tolerancias se definen en la especificación YAML del pod en spec.tolerations de la siguiente forma:
tolerations: - key: "os" operator: "Equal" value: "linux" effect: "NoSchedule"
Esta tolerancia, por ejemplo, permite que el pod sea desplegado en aquellos nodos que tengan la mancha os=linux:NoSchedule. Así pues, debemos especificar la clave, el valor y el efecto de la mancha asociada. Si el nodo tuviera la mancha os=linux:NoExecute este pod no se podría desplegar en este nodo: los efectos deben coincidir.
También es posible que una tolerancia afecte a un grupo de manchas:
tolerations: - key: "os" operator: "Exists" effect: "NoSchedule"
En este caso este pod se podrá desplegar en cualquier nodo que tenga una mancha de la forma os=xxx:NoSchedule siendo xxx un valor arbitrario. Observa cómo en la especificación YAML de la tolerancia el operator es Exists y antes era Equal.
Podemos ir más allá y crear una tolerancia que permita al pod ser desplegado en cualquier nodo que tenga una mancha de la forma os=xxx:yyy siendo xxx cualquier valor e yyy cualquier efecto:
tolerations: - key: "os" operator: "Exists"
Y por último, podemos crear “la madre de todas las tolerancias”, que permite al pod ser desplegado en cualquier nodo da igual la mancha que tenga:
tolerations: - operator: "Exists"
Así, podemos manchar un nodo para evitar que ningún pod se ejecute en él y luego agregar tolerancias a los pods que queramos que se puedan ejecutar en este nodo. Pero ¡ojo! eso no significa que los pods con tolerancias se ejecuten siempre en los nodos manchados: simplemente significa que esos serán considerados por el scheduler, pero podría ocurrir que un pod con tolerancias termine ejecutándose en un nodo sin mancha alguna.
Selector de nodos (node selector)
Existe otro mecanismo para darle instrucciones al scheduler sobre en qué nodo debe ejecutar un determinado pod y es que este defina un selector de nodo. Los selectores de nodo son independientes de las manchas y tolerancias (aunque los puedes combinar). Al igual que las tolerancias, se definen en la especificación YAML del pod, concretamente en spec.nodeSelector:
nodeSelector: disk: ssd
Un nodeSelector define una o más etiquetas (clave:valor). En este ejemplo está definiendo la etiqueta disk con el valor ssd. Eso significa que este pod solo podrá ser desplegado en nodos que tengan dicha etiqueta. ¿Y dónde se definen las etiquetas de los nodos?
Pues en la sección metadata.labels de la especificación YAML del nodo.
Combinando manchas, tolerancias y selectores de nodos
Veamos un ejemplo de cómo podemos combinar las manchas, las tolerancias y los selectores de nodos, con un ejemplo concreto.
Imaginemos un clúster de Kubernetes con varios nodos:
- Algunos usan Linux
- Otros usan Windows, de los cuales sólo uno tiene una GPU potente.
Tenemos tres tipos de pods (tres deployments):
- Uno que despliega pods con contenedores Linux. Llamémosle
pod-linux - Otro que despliega pods con un contenedor Windows que usa CUDA para tareas que requieren una GPU potente. Llamémosle
cuda-windows - Otro que despliega pods con contenedores Windows. Llamémosle
pod-windows.
Queremos asegurar lo siguiente:
- Los pods con contenedores Windows deben ejecutarse en un nodo Windows que no tenga GPU.
- Los pods con contenedores Linux deben ejecutarse en un nodo Linux
- Los pods que usan CUDA deben desplegarse en el nodo Windows que tiene la GPU potente.
Eso lo podemos solucionar de la siguiente forma:
- Los pods de
pod-linuxdefinen unnodeSelectorcon la etiquetakubernetes.io/os:linux - El nodo que tiene la GPU define una mancha
gpu:present:NoExecute - El nodo que tiene la GPU define una etiqueta:
cuda:enabled - Los pods de
cuda-windowsdefinen una tolerancia para la manchagpu:present. Eso permite a esos pods ejecutarse en este nodo, pero no obliga a ello. - Los pods de
cuda-windowsdefinen unnodeSelectorcon la etiquetacuda:enabled. De este modo obligamos al scheduler a desplegarlos al único nodo que tiene dicha etiqueta. Observa que la tolerancia anterior permite ese despliegue a pesar de la mancha del nodo. - Los pods de
pod-windowsdefinen unnodeSelectorcon la etiquetakubernetes.io/os:windows. Esta etiqueta selecciona cualquier nodo con Windows, incluyendo el que tiene la GPU, pero este es descartado por la manchagpu:present:NoExecute.
La etiqueta kubernetes.io/os es propia de Kubernetes y contiene el sistema operativo del nodo.
Ejercicio propuesto
Crear un pod y exponerlo
- Crea un pod llamado test que ejecute
dockercampusmvp/go-hello-world - Crea un servicio llamado
test-svcque exponga al pod - Ejecuta un pod de
busyboxy enlázate al terminal- Verifica que puedes usar
wgetpara acceder al pod usando el DNS del servicio
- Elimina el pod test
- Crea otro pod llamado
test2que ejecutedockercampusmvp/go-hello-world - Desde
busyboxintenta acceder al servicio.- ¿Qué ocurre? ¿Por qué?
- Sin eliminar ni recrear
test2haz que el serviciotest-svcenrute sus peticiones al pod