Tabla de Contenidos
Usar Docker para compilar
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
Hasta ahora hemos visto cómo usar Docker para ejecutar aplicaciones y sus dependencias. Hemos visto también la manera de crear imágenes Docker para nuestras propias aplicaciones y cómo ejecutar aplicaciones que requieran más de un contenedor.
Pero Docker nos ofrece ventajas también en la compilación de nuestro código. La idea subyacente es exactamente la misma que en el caso de las dependencias: a fin de cuentas un SDK en concreto no deja de ser una dependencia, salvo que es en tiempo de construcción de la aplicación, en lugar de ser en tiempo de ejecución. Y del mismo modo que Docker te permite independizarte de las dependencias en tiempo de ejecución (tales como bases de datos, caché, sistemas de mensajería y un largo etcétera), también te puede liberar de las dependencias en tiempo de compilación.
Es decir, puedes compilar (casi) cualquier aplicación sin necesidad de tener ningún SDK instalado en tu máquina.
¿Necesitas generar unos binarios de una aplicación .Net, pero no tienes .Net instalado en tu máquina? ¡Ningún problema! ¿Debes generar un JAR de una aplicación Java, pero no dispones de JDK? ¡No te preocupes! Docker te puede ayudar en todos estos casos, y en este módulo vamos a ver cómo.
Compilando con Docker
Este ejercicio está desarrollado con netcore2, que es una tecnología ya obsoleta. Pero, precisamente sirve para ilustrar cómo Docker nos permite ejecutar aplicaciones desarrolladas en tecnologías, digamos “viejas”, sin necesidad de instalar nada en nuestro ordenador. ¿La única condición? Que exista una imagen de Docker, claro.
Supongamos que tienes un programa desarrollado con .Net Core2 (luego veremos ejemplos con otros lenguajes). Descárgate el fichero helloworld-netcore2.zip y descomprímelo. Este será el primer ejemplo que compilemos.
Cómo lo haríamos si tuviéramos .Net Core 2 SDK instalado
En el caso de que tuvieras el SDK de .Net Core instalado, podríamos ejecutar:
dotnet run
Y eso ejecutaría el proyecto en nuestra máquina. Pero a nosotros nos interesa poder hacer eso mismo sin necesidad de instalar nada, ahí es donde entra, claro está, Docker.
Una primera aproximación
El comando dotnet run nos permite ejecutar un proyecto de .NET Core 2 necesidad de compilarlo previamente.
Pues bien, eso mismo lo podemos hacer en un contenedor. El único requisito, claro está, es que este contenedor esté creado a partir de una imagen que tenga el SDK de .Net Core instalado. Podríamos crearla nosotros (a partir de una imagen como la de ubuntu), pero por suerte Microsoft ya ha creado una. Vamos a partir de la imagen microsoft/dotnet.
Esa imagen tiene muchos tags, ya que Microsoft mantiene muchas versiones. Dado que nuestro código es .Net Core 2, necesitamos alguna que tenga el SDK de esa versión. En este caso, la imagen que nos interesa es: mcr.microsoft.com/dotnet/sdk:2.1.
A continuación debemos crear un Dockerfile que haga lo siguiente:
- Parta de la imagen
mcr.microsoft.com/dotnet/sdk:2.1 - Copie el código fuente en una carpeta (p. ej.
/src) - Como comando del contenedor ejecute
dotnet run
Tómate tu tiempo y crea por tu cuenta el Dockerfile necesario. Estudiamos todos los comandos necesarios cuando vimos cómo crear imágenes propias. Tienes una posible solución en las descargas, en el archivo helloworld-netcore2-Dockerfile1.zip.
Una vez tengas el Dockerfile construye la imagen con:
docker build . -t dotnet-run
Y ejecútala: docker run dotnet-run.
Ya deberías ver el Hello World! por pantalla: ¡Has ejecutado un programa .Net Core sin necesidad alguna de tener ni el SDK ni el runtime de .Net Core!
¡ojo!, esa no es una aproximación deseable para producción. Los dos problemas principales son que cada vez que ejecutamos el contenedor se tiene que compilar on-the-fly la aplicación, y que el contenedor que estamos usando para ejecutar tiene el SDK instalado (cuando debería bastarle con el runtime).
Cómo lo haríamos si tuviéramos .Net Core SDK instalado (para publicar en producción)
A pesar de que dotnet run nos sirve para ejecutar código fuente si tenemos el SDK, cuando publicamos en producción queremos desplegar los binarios ya precompilados. Eso no solo nos da un mayor rendimiento, sino que además evita que en producción necesitemos el SDK y nos basta solo con el runtime. En el caso concreto de .Net Core, se usa la instrucción del SDK dotnet publish -o <directorio>, que compilará la aplicación y publicará los binarios.
Por ejemplo, el siguiente comando generaría los binarios y los dejaría en el directorio ./out. El contenido de ese directorio (pueden ser uno o más ficheros) conforman los binarios que representan nuestra aplicación:
dotnet publish -o out
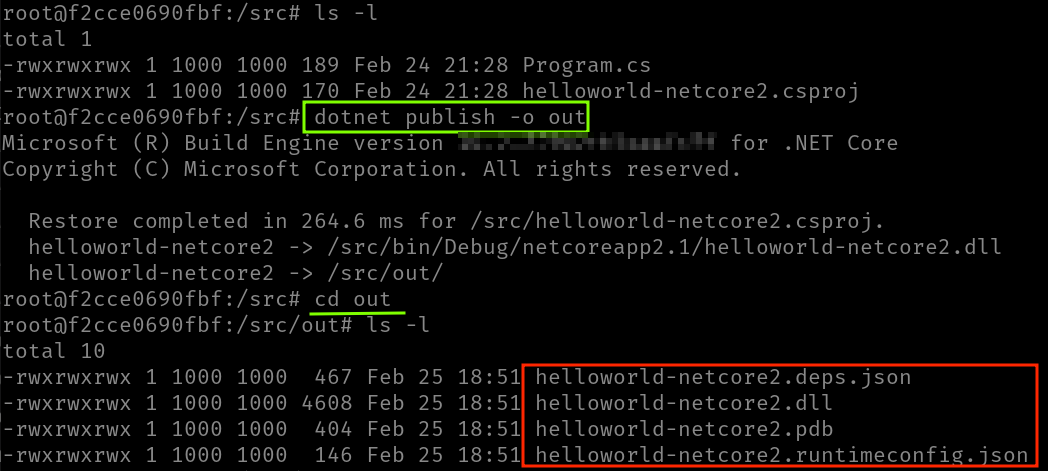
Para poder ejecutar esos binarios se requiere que la máquina tenga el runtime (que no el SDK, ojo) de .NET Core (del mismo modo que para ejecutar una aplicación Java se requiere el JRE o debes tener Node.js instalado para ejecutar una aplicación en esa plataforma, por poner dos ejemplos).
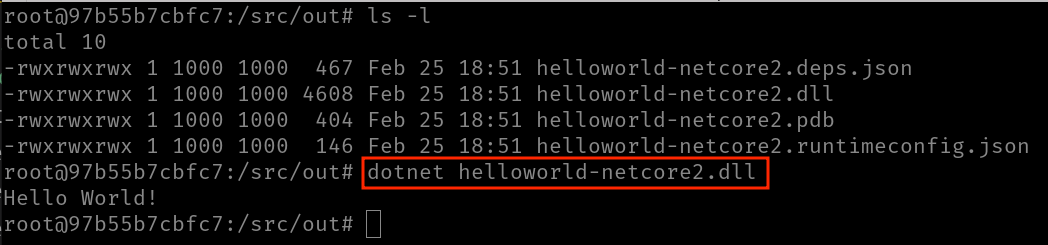
Una vez tenemos los binarios generados, los copiaríamos en cualquier máquina que tuviese el runtime y podríamos ejecutar con dotnet [nombre-de-la-dll] (observa que no se usa run).
¿Cómo podríamos usar la imagen del SDK de .Net Core para compilar el proyecto? Pues bien, con un Dockerfile como este:
FROM mcr.microsoft.com/dotnet/sdk:2.1 WORKDIR /src COPY . . ENTRYPOINT [ "dotnet", "publish", "-o", "out" ]
Luego podríamos crear una imagen a partir de ese Dockerfile y un contenedor a partir de esa imagen. Pero… ¿adivinas cuál es el problema? Piénsalo un poco, prueba a ejecutarlo si quieres, y a ver si ves el problema de esa aproximación …
Usando volúmenes para compilar
Bueno, el problema del contenedor anterior es que los ficheros se publican dentro del contenedor, pero luego… ¡no tenemos forma de poder obtener los ficheros compilados!
Eso es porque la idea de usar un contenedor con el SDK para compilar es correcta, pero tenemos que conseguir que los ficheros generados se guarden en un directorio del host. ¿Y cuál es la forma más sencilla de conseguir eso?
Exacto: usando un bind mount.
La idea es que el contenedor haga exactamente lo mismo que hacía, pero que el directorio /src/out donde guarda la publicación sea un bind mount de un directorio del host. Y con eso conseguimos compilar nuestro proyecto usando Docker.
De hecho, no tenemos ni que modificar el Dockerfile ni la imagen si no queremos, nos basta con usar -v cuando hagamos el docker run:
docker run -v <dir-host>:/src/out <nombre-imagen>
Así montamos un bind mount para que el directorio /src/out del contenedor sea en realidad un directorio del host y, de ese modo, el resultado del dotnet publish lo tendremos en local.
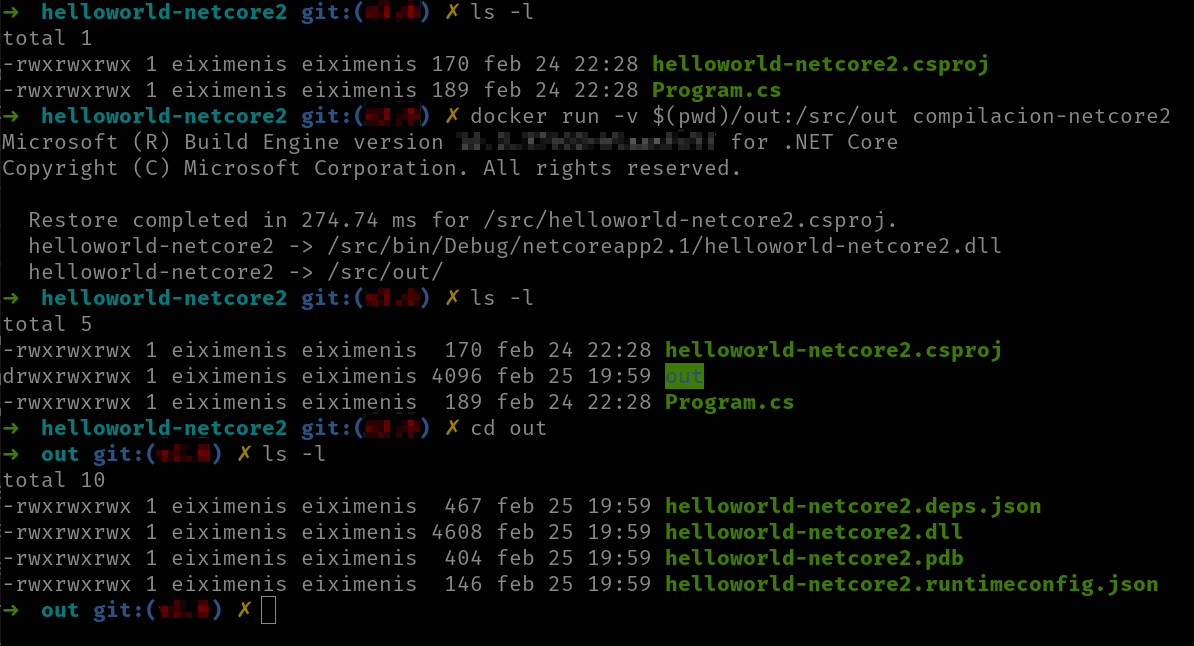
Observa el uso de -v $(pwd)/out en el comando docker run. Ese era un truco para poder usar directorios relativos en el modificador -v. Anteriormente, ese modificador solo aceptaba directorios absolutos. El comando pwd en Linux (y en Powershell) devuelve el directorio actual, así que la cadena $(pwd)/out se resuelve al directorio actual y /out, es decir al directorio out dentro del directorio actual. Eso funciona en Linux y en Powershell, pero no en la línea de comandos tradicional de Windows (cmd). De todas formas actualmente ya puedes usar directorios relativos con el modificador -v, pero los humanos somos animales de costumbres, así que no te sorprendas si ves a mucha gente usando este truco.
¡Fantástico! Ahora sí: hemos conseguido compilar un proyecto .Net Core sin usar para nada el SDK de .Net Core en nuestro equipo. Ahora ya podríamos distribuir los binarios en cualquier máquina que tuviese .Net Core o… ¡construir un contenedor Docker para ejecutar esos binarios! Por supuesto, este contenedor ya no requiere el SDK, solo el runtime.
Ahora bien, esa nueva solución sigue presentando un problema importante: cada vez que modifiques el código fuente deberás volver a crear una imagen, ya que el código fuente está copiado en esta (es la sentencia COPY . . del Dockerfile). Por lo tanto, cada vez que modificas el código fuente, debes recrear la imagen para poder compilarlo de nuevo.
¿Se te ocurre alguna solución al respecto?
Usando volúmenes para compilar (2ª parte)
El problema que ahora queremos solucionar es el de tener que recrear la imagen cada vez que modificamos el código. Eso nos pasa porque el código fuente forma parte de la imagen, por lo que una vez lo modificamos necesitamos una imagen nueva que lo contenga. Si planeas usar Docker de forma habitual para compilar eso no es muy eficiente que digamos.
Es posible que ya tengas una intuición acerca de cómo podemos solventar eso. Si has pensado en usar, otra vez, un bind mount te diré que has acertado: en lugar de copiar los ficheros de código fuente a la imagen, ¿por qué no usar un bind mount y compartir directamente el directorio del host que los contiene?
El primer paso es eliminar el COPY . . del Dockerfile: ya no necesitamos copiar nada en la imagen:
FROM mcr.microsoft.com/dotnet/sdk:2.1 WORKDIR /src ENTRYPOINT [ "dotnet", "publish", "-o", "out" ]
Y ahora simplemente debemos crear dos bind mounts cuando ejecutemos el contenedor:
- El que ya usábamos para poder tener los ficheros compilados en el host
- El nuevo para que el contenedor tenga los ficheros de código fuente
Así, si tenemos nuestro código fuente en una carpeta llamada C:\src\ y nuestra imagen se llama compilacion-netcore2 la sentencia a ejecutar sería algo parecida a:
docker run -v /C/src:/src -v /C/out:/src/out compilacion-netcore2
Y con esto tendríamos en el directorio C:\out el resultado de la compilación. Ahora, cuando queramos compilar solo tenemos que ejecutar este comando de Docker y listos: ¡ya no hay que recrear imagen alguna!
Nota (no muy importante): en este caso concreto nos podríamos ahorrar (si queremos) el segundo bind mount. La razón es que el primero nos monta el directorio C:\src al directorio /src del contenedor. Y el contenedor publica el resultado en /src/out, que es un subdirectorio de /src. Por lo tanto, si no ponemos el segundo bind mount tendremos en C:\src\out el resultado de la compilación. Por supuesto, si lo queremos en otro sitio (como en nuestro ejemplo que lo queremos en C:\out, o si el contenedor publicase en otro directorio que no fuese hijo de /src, entonces sí que necesitamos el segundo bind mount).
Vale, ahora observa un punto interesante: ¿qué contiene realmente nuestra imagen ahora? Es decir, ¿qué diferencia nuestra imagen de la imagen base mcr.microsoft.com/dotnet/sdk:2.1? Pues la verdad es que, por lo que respecta a los archivos, nada: nuestra imagen es, en esencia, la imagen base con un comando inicial distinto.
Y a través del comando docker run podemos redefinir el comando inicial de una imagen, así que la pregunta que ahora nos queda es… ¿para qué necesitamos una imagen propia?
La respuesta es: para nada.
Compilar directamente con la imagen base
La realidad es que podemos compilar directamente con la imagen base:
docker run -v /C/src:/src -v /C/out:/src/out mcr.microsoft.com/dotnet/sdk:2.1 bash -c "cd /src && dotnet publish -o out"
En este caso estamos levantando un contenedor de la imagen mcr.microsoft.com/dotnet/sdk:2.1 pero le indicamos que en lugar de ejecutar el comando inicial que tuviese definido en la imagen, lance el comando que nosotros le indicamos; en este caso que haga un cd /src y luego un dotnet publish -o out.
Nota aclaratoria: (Esta nota es más de Linux que de Docker, pero es interesante). Observa que el comando que le decimos al contenedor que ejecute es realmente bash -c “…”. Eso significa ejecutar bash (un intérprete de comandos) y que bash ejecute lo que sea que haya después del -c. La razón de tener que usar bash y no poder poner como comando directamente cd /src && dotnet publish -o out es que cd no es un ejecutable, sino un comando built in de bash. Por lo tanto si como comando ponemos directamente cd /src recibiremos un error similar a: exec: \“cd\”: executable file not found in $PATH“. Este error nos dice que al ejecutar el comando cd no se ha encontrado ningún ejecutable que se llame cd. Normal, porque no existe, ya que es un comando de bash. Por lo tanto debemos ejecutar eso en un contexto de bash, para que interprete el comando cd.
Ya hemos llegado al final de nuestra solución: la única cosa que nos genera “un poco de fricción” es tener que ejecutar esta sentencia docker run tan “larga”, pero por suerte, incluso para esto tenemos una solución: Compose nos puede ayudar aquí también.
Usando Compose
No es imprescindible emplear Compose, pero dado que una de las funcionalidades básicas de Compose es facilitarnos la vida, ¿por qué no usarlo? La idea es sustituir el docker run … por un simple docker compose up.
Este docker compose up tan solo levantará el contenedor de compilación (la imagen base) para que ejecute el comando que nosotros queremos. Y seguiremos usando bind mounts para compartir los ficheros (de código fuente y generados) entre el contenedor y el host.
Para ello vamos a crear un fichero Compose. Vamos a llamarlo docker-compose.build.yml para distinguirlo del docker-compose.yml (ahora no lo tenemos, pero más adelante lo vamos a querer), para que quede claro que la idea es levantar un contenedor para compilar.
Creación de un fichero Compose:
- Definimos un servicio (llamado
build) - Este servicio debe estar implementado por la imagen de compilación
- Configuramos los bind mounts (usando la sección
volumes) - Redefinimos el comando inicial (usando la sección
command)
El fichero Compose obtenido será:
version: '3' services: build: image: mcr.microsoft.com/dotnet/sdk:2.1 volumes: - .:/src working_dir: /src command: /bin/bash -c "dotnet publish -o out"
Observa que solo usamos un bind mount (ya se ha comentado antes en qué casos lo podíamos hacer. Si queremos usar los dos, simplemente añadiríamos otra entrada a la sección volumes).
No las habíamos visto hasta ahora, pero también se usa:
- La sección
working_dir: para establecer el directorio de trabajo del contenedor. Esto sobrescribe el valor deWORKDIRque haya establecido en la imagen. - La sección
command: para establecer el comando inicial del contenedor.
Es importante que el fichero Compose esté en el mismo directorio del código fuente, ya que en el bind mount montamos el directorio actual (.) y este es relativo al fichero Compose.
Y ahora sí: ¿quieres compilar? Pues teclea simplemente docker compose -f docker-compose.build.yml up. Y listos.
Ejecutar sin necesidad del runtime
Hemos visto cómo podemos compilar (generar los binarios) sin necesidad de tener el SDK instalado gracias a Docker. Hemos ido iterando sobre la solución hasta llegar a usar Compose y conseguir que un simple up nos compile todo nuestro código.
Pero una vez compilado, ahora queremos ejecutarlo. Por supuesto tienes los binarios, así que puedes ejecutarlos en tu máquina… si tienes el runtime, claro. Pero existe otra opción: generar una imagen de Docker, solo con el runtime para ejecutar tu código. Así, usamos Docker para compilar y también para ejecutar.
Vamos a seguir con el ejemplo anterior. Habíamos terminado con un fichero Compose (docker-compose.build.yml) que usaba la imagen del SDK (hemos visto cómo usando volúmenes para compartir tanto el código fuente como el resultado compilado no necesitamos usar una imagen propia) y nos dejaba el código compilado en nuestro disco. Es decir, dado este directorio inicial (resultado de descomprimir el fichero helloworld-netcore2.zip) y con nuestro fichero Compose, ejecutamos docker compose -f docker-compose.build.yml:
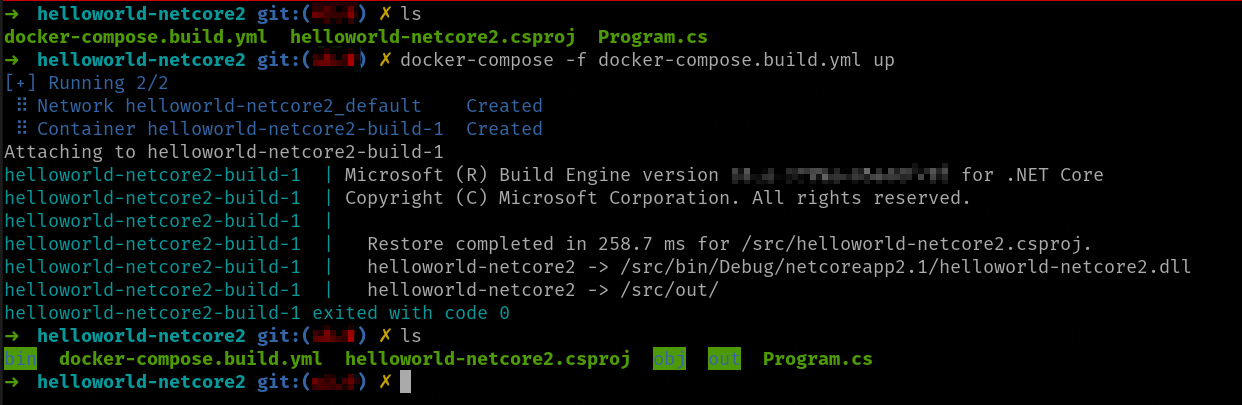
En la carpeta out están los binarios; las carpetas bin y out son temporales y se pueden borrar.
¡Genial! Ahora necesitamos un Dockerfile para crear la imagen ubicado en el mismo directorio donde esté el código fuente y el fichero Compose. Prueba a hacerlo por tu cuenta, ¿vale?
Debe hacer lo siguiente:
- Usar la imagen
mcr.microsoft.com/dotnet/runtime:2.1 - Copiar el contenido de la carpeta
outen alguna carpeta del contenedor (yo he usado/app) - Establecer el comando
dotnet helloworld-netcore2.dllcomo comando inicial del contenedor
Si quieres ver la solución con el Dockerfile buscado:
FROM mcr.microsoft.com/dotnet/runtime:2.1 WORKDIR /app COPY ./out . ENTRYPOINT ["dotnet", "helloworld-netcore2.dll"]
Una vez creado ya puedes construir la imagen (yo le he dado el nombre de hello-world-netcore) y finalmente claro… ¡ya la puedes ejecutar!
Por supuesto, puedes crear un fichero Compose para construir y ejecutar tu imagen todo en uno. Aquí tienes cómo sería el docker-compose.yml:
version: '3' services: hello-world: image: hello-world-netcore build: context: . dockerfile: Dockerfile
Así, para compilar debes usar docker compose -f docker-compose.build.yml y para ejecutar la aplicación docker compose up.
Y listos: has compilado y ejecutado un programa sin necesidad de tener ni el SDK ni el runtime necesario. ¡Solo usando contenedores!
Pues espera, que todavía podemos mejorar este proceso, usando una técnica llamada multi stage build.
Multi-Stage builds
Hemos visto cómo compilar sin tener el SDK y ejecutar sin tener el runtime. El proceso no es que no funcione (que lo hace y bien) pero tiene un par de fricciones:
- Hemos de ejecutar dos ficheros Compose, uno para compilar y otro para ejecutar. Lo ideal sería ejecutar un solo comando que compilase y ejecutase a la vez.
- Nos deja “residuos” en nuestra máquina: los binarios compilados (y quizá ficheros temporales). Si no vamos a ejecutarlos directamente desde nuestra máquina… ¿para qué los queremos?
El primer punto lo podemos solventar con un script que ejecute los dos Compose, uno tras otro; pero el segundo no tiene una solución fácil… y precisamente para solucionarlo existen las multi-stage builds.
Qué es una multi-stage build
Una multi-stage build es un proceso de construcción de una imagen en el cual interviene más de un contenedor de distintas imágenes base y se pasan datos entre ellos.
Hasta ahora, en el proceso de construcción de una imagen siempre usábamos una única imagen base (recuerda, la instrucción FROM del Dockerfile). A partir de esa imagen se creaba un contenedor que ejecutaba las instrucciones del Dockerfile para terminar generando la imagen final. Pues bien, una multi-stage build nos permite usar más de un contenedor base, es decir más de una instrucción FROM en el Dockerfile.
En este contexto la palabra build no se refiere a compilar nuestro proyecto ni nada parecido. Se refiere a construir una imagen de Docker.
La mejor manera entender una multi-stage build es a través de un ejemplo, así que vamos a verlo. A continuación tienes un ejemplo de un Dockerfile para la multi-stage build de nuestro hello world:
FROM mcr.microsoft.com/dotnet/sdk:2.1 AS build WORKDIR /src COPY . . RUN dotnet publish -o /app FROM mcr.microsoft.com/dotnet/runtime:2.1 AS final WORKDIR /app EXPOSE 80 COPY --from=build /app . RUN ls /app ENTRYPOINT ["dotnet", "helloworld-netcore2.dll"]
Te puedes descargar este Dockerfile desde las referencias cruzadas de la lección o desde las descargas del curso: helloworld-netcore2-multistage.zip.
Se han separado las tres partes con una línea en blanco, pero son fáciles de detectar porque cada sección empieza con un FROM. Esa es la clave diferenciadora de una multi-stage build: más de una sentencia FROM. Cada sentencia FROM define un stage que va desde este FROM hasta el siguiente (o hasta el final del fichero). El comando docker build construye hasta el último stage.
Empecemos por el principio:
- Primera sección: definimos una imagen llamada
buildque hereda demcr.microsoft.com/dotnet/sdk:2.1. Esa es la imagen que usaremos para compilar el proyecto. Y, de hecho, el resto de instrucciones lo que hacen es copiar el código fuente y ejecutar eldotnet publishpara generar los binarios. Esos binarios se generan dentro del contenedor que ejecuta esa imagen, en su directorio/app. Aquí no estamos usando volumen alguno. - Segunda sección: por un lado, definimos una imagen
finalque hereda demcr.microsoft.com/dotnet/runtime:2.1. Luego lo que hacemos, y esa es la clave, es copiar los ficheros que están en la imagenpublisha la imagenfinal. Observa el modificador--fromusado en elCOPY. Este modificador establece que el origen de datos no es el host sino otra imagen (definida en el mismo multi-stage build). Por lo tanto, podemos copiar ficheros de imagen a imagen sin pasar por el host. De este modo, evitamos los “residuos” que comentábamos antes: no se genera ningún fichero en el host.
No quiero olvidarme de mencionar que un stage puede, o bien heredar de una imagen de Docker (como es el caso del ejemplo que hemos visto), pero también puede heredar de otros stages definidos previamente. Por ejemplo, el siguiente Dockerfile es equivalente al anterior (en el sentido de que la imagen final del último stage es idéntica):
FROM mcr.microsoft.com/dotnet/runtime:2.1 AS base
WORKDIR /app
EXPOSE 80
FROM mcr.microsoft.com/dotnet/sdk:2.1 AS build
WORKDIR /src
COPY . .
RUN dotnet publish -o /app
FROM base AS final
COPY --from=build /app .
RUN ls /app
ENTRYPOINT ["dotnet", "helloworld-netcore2.dll"]
Observa cómo el ultimo stage (llamado final) hereda del stage base definido al principio del fichero. Eso nos da una gran flexibilidad.
¿Cuál es el resultado de construir un Dockerfile multi-stage?
Pues, por defecto, el de la última sección declarada, que en nuestro caso es la imagen que solo tiene el runtime (la final). Las otras dos imágenes (base y build) son descartadas.
Pero es posible construir una imagen hasta un stage intermedio usando el modificador --target <nombre-stage>. Eso es muy interesante en según qué escenarios, ya que nos permite “exportar” stages intermedios como imágenes (y crear contenedores a partir de ellas).
Por ejemplo, Visual Studio usa mucho esa técnica cuando nos permite depurar nuestro código, pero ejecutándose en Docker. Para ello, genera un Dockerfile con tres stages (muy parecido al segundo Dockerfile que se ha mostrado más arriba), el primero del cual simplemente hereda de la imagen base del runtime y poco más. Eso le permite tener el runtime, luego usa el comando docker build con el modificador --target para construir una imagen de ese primer stage y finalmente crea un contenedor de esa imagen, comparte el código usando bind mounts y conecta el depurador a dicho contenedor.
Luego ese mismo Dockerfile es el que usa para construir la imagen final, usando docker build sin --target para construir el último stage.
¡Y listos! Ahora sí que ya hemos llegado al final: podemos compilar y ejecutar en un solo paso sin necesidad de tener ni SDK ni runtime alguno. Docker se convierte en nuestro único requisito.
Usando Compose
Por supuesto, un Dockerfile multi-stage es un Dockerfile normal, así que podemos usar Compose sin problemas:
version: '3' services: hello-world: image: hello-world-netcore build: context: . dockerfile: Dockerfile
Observa que es exactamente el mismo docker-compose.yml que teníamos antes para ejecutar (no para compilar). Pues bien, ahora el proceso de build de la imagen también la compila, así que tecleando simplemente docker compose up compilamos y ejecutamos el proyecto a partir del código fuente: ¡exactamente igual que usar “run” en tu IDE favorito! Ya no necesitas, obviamente, el docker-compose.build.yml.
Vamos a ver ahora un par de ejemplos de multi-stage builds para otros lenguajes, pero no vamos a introducir ningún concepto nuevo.
Aprovechando la caché de Docker
Como ya sabes las imágenes de Docker están formadas por una sucesión de capas. Durante el proceso de construcción de una imagen, Docker se guarda esas capas en una caché, de forma que las reutiliza si es posible.
El algoritmo que usa Docker para reutilizar una capa o no es muy sencillo:
- Si la capa se genera a partir de un
COPY(o unADD) Docker se asegura de que el hash de los ficheros añadidos sea el mismo. Eso significa que si no has modificado ningún fichero, la capa se reusará. Pero, sólo con que uno de los ficheros sea distinto, la capa será invalidada (y se ejecutará de nuevo) - Si la capa se genera a partir de cualquier otra sentencia del
Dockerfile(tal comoEXPOSEoRUN), se reusará si la sentencia delDockerfileno se ha modificado - Cuando se invalida una capa, todas las siguientes quedan invalidadas
Aprovechar la caché de Docker significa construir tus Dockerfiles tal que las capas generadas se apilen de forma que las primeras capas tengan más probabilidad de ser reusadas que las últimas. Eso puede parecer un poco complejo y la verdad es que es un poco “un arte” que depende de cada tecnología, pero déjame mostrarte un ejemplo.
El fichero hello-world-net6.zip contiene el ejercicio del “hello world” que hemos estado implementando, pero usando net6. No obstante, no es el cambio de tecnología lo relevante, si no el Dockerfile. Si lo miras verás que sigue siendo un multi stage, pero el primer stage (build) es un poco distinto:
FROM mcr.microsoft.com/dotnet/sdk:6.0 AS build WORKDIR /src COPY ["./HelloWorldNet6.csproj", "."] RUN dotnet restore "HelloWorldNet6.csproj" COPY . . RUN dotnet build "HelloWorldNet6.csproj" -c Release -o /app/build RUN dotnet publish "HelloWorldNet6.csproj" -c Release -o /app/publish
Observa como en lugar de copiar todo el código (con un COPY . .) se copia primero solo el fichero HelloWorldNet6.csproj y luego se ejecuta un RUN dotnet restore. Eso a nivel de capas:
- Crea una primera capa con el fichero
HelloWorldNet6.csproj - Crea una segunda capa con el resultado de ejecutar
dotnet restore. Ese comando, en .NET se encarga de obtener los paquetes externos al proyecto y guardarlos en disco.
Luego sí que copia todo el código con el COPY . . y finalmente ejecuta dotnet build y dotnet publish, lo que añade tres capas más:
- Una tercera capa con todos los ficheros
- La cuarta con el resultado de ejecutar
dotnet build - Y la quinta con el resultado de ejecutar
dotnet publish
¿Y qué ganamos con esa organización de capas? Pues que en .NET la operación dotnet restore es “relativamente” lenta, ya que debe conectarse a internet para descargarse los paquetes. Las referencias a esos paquetes se encuentran solo dentro del fichero csproj, por lo que, si este cambia basta con volver a restaurar los paquetes (es cierto que hay otros posibles cambios en el fichero csproj que nada tienen que ver con los paquetes externos, pero no es posible afinar tanto). Pero si este fichero no cambia, restaurar los paquetes cada vez es una pérdida de tiempo, porque serán los mismos que la vez anterior.
Aquí es donde entra la caché de Docker. Si por ejemplo, sólo has hecho un cambio en un fichero de código (por ejemplo, el Program.cs), cuando hagas el siguiente docker build:
- La primera capa se reusará (porque el
csprojno se ha modificado) - La segunda capa se reusará (porque la sentencia
RUNno se ha modificado en elDockerfile) - La tercera capa se invalidará (porque alguno de los ficheros copiados es distinto)
- A partir de ahí, las otras capas quedan invalidadas.
El resultado es que consigues optimizar el tiempo de docker build ya que sólo ejecutas dotnet restore en aquellos casos en que es necesario: cuando se ha modificado el fichero csproj. En el resto de casos te ahorras esa tarea.
Esa misma filosofía la podrías seguir en otros lenguajes. Por ejemplo, en Node, es habitual copiar primero solamente el package.json, ejecutar luego el npm restore y finalmente copiar el resto de código. La razón es siempre la misma: es más habitual que se modifique un fichero de código, que no que se modifique una referencia a un paquete externo.
Optimizar bien tus Dockerfiles puede marcar una gran diferencia, especialmente en aquellos procesos en que hay tareas que se realizan con poca frecuencia, pero que pueden llegar a consumir mucho tiempo (sí, NPM, te miro a ti).
Ojo, que a veces la caché tiene efectos contraproducentes, especialmente en sentencias RUN. A lo mejor no deseas que una sentencia RUN se reaproveche. En este caso debes usar el modificador --no-cache al comando docker build, lo que invalida toda la caché para esa imagen y reconstruirá todas las capas.
Un par de ejemplos de multi-stage build
Vamos a ver y a comentar un par de casos adicionales para tener ejemplos con otros entornos y plataformas de desarrollo. Dispones del código fuente de los proyectos (incluidos Dockerfile y fichero Compose) para verlo y ejecutarlo y por supuesto… ¡experimentar con él!
Hello World con Go
El primer ejemplo que vamos a ver es muy sencillo, se trata de un sencillo “hello world” creado con Golang. Lo que hace es levantar un servidor web que escucha por el puerto 80 y a cada petición muestra un mensaje que se va incrementando en cada petición.
Lo importante aquí no es el programa en sí, que podría hacer cualquier otra cosa, sino ver el proceso con Docker, por lo que vamos a mantenerlo lo más sencillo posible. El código Go de ese ejemplo ha sido sacado del siguiente repositorio en GitHub, pero tienes el código fuente y el Dockerfile en el fichero helloworld-go.zip.
El Dockerfile multi-stage para este proyecto de Go es como sigue:
FROM golang:1.9-stretch WORKDIR /go/src/hello_world COPY hello_world.go . RUN go build FROM ubuntu:latest WORKDIR /root/ COPY --from=0 /go/src/hello_world . ENTRYPOINT ["/root/hello_world"]
La primera sección es la que se usa para generar el binario. En este caso usamos la imagen golang:1.9-stretch que contiene el SDK de Go. Simplemente nos situamos en el directorio /go/src/hello_world, copiamos el código fuente (en este caso consta de un solo fichero llamado hello_world.go) y ejecutamos el comando go build para compilar.
La segunda sección es la que genera la imagen final, la de ejecución. En este caso partimos de la imagen ubuntu:latest (Go compila a nativo, por lo que no suele necesitar un runtime específico instalado, lo que viene por defecto con el sistema operativo es suficiente). En la sentencia COPY copiamos el binario de la primera imagen a esta nueva. Observa que usamos el --from pero con un índice numérico (0) en lugar de un nombre. Eso es porque no hemos otorgado nombre a la primera imagen (en el ejemplo anterior usábamos FROM imagen as nombre y eso nos permitía usar el nombre luego. Si no quieres usar nombres, siempre puedes usar los índices numéricos). Como Go genera ejecutables directos, el ENTRYPOINT es simplemente ejecutar el ejecutable compilado.
Hello World con Kotlin
Kotlin es un lenguaje del ecosistema JVM desarrollado por JetBrains y que ha ganado mucha tracción y cada vez es más popular. Vamos a realizar un “hello world” en Kotlin: en este caso se levanta un servidor web (por el puerto 8000) que devuelve “Hello World” a cualquier petición.
El código (un solo fichero de código fuente) está sacado de este Gist. Tienes tanto el fichero de código fuente como el Dockerfile desde helloworld-kotlin.zip.
El Dockerfile es tal y como sigue:
FROM rayyildiz/kotlin:1.1.51 WORKDIR /src COPY hello-world.kt . RUN kotlinc hello-world.kt -include-runtime -d hello-world.jar FROM openjdk:8-jre WORKDIR /app COPY --from=0 /src/hello-world.jar . ENTRYPOINT ["java", "-jar", "hello-world.jar"]
A esas alturas no deberías necesitar muchas explicaciones para entender las dos secciones de este Dockerfile.
La primera sección es la que se usa para compilar y usa la imagen rayyildiz/kotlin:1.1.51 que ya nos provee de un entorno de Kotlin. Simplemente copiamos el fichero de código fuente y usamos el compilador de Kotlin para generar un JAR que tenga todo lo necesario para ejecutar.
La segunda sección es la que genera la imagen de ejecución. Es el mismo patrón que en el caso anterior con Go: básicamente copiamos el JAR y al final usamos el comando java para ejecutarlo.
El contexto de build
Al estudiar Compose, en el apartado “Construir imágenes usando Docker Compose”, cuando se explicaba la entrada context del fichero Compose, mencionamos algo sobre “el contexto de creación de una imagen” (contexto de build), posponiendo la explicación para más adelante. Pues bien: ha llegado el momento de ahondar un poco en el contexto de build.
Qué es el contexto de build
El primer paso que el cliente de Docker realiza al construir una imagen es enviar el contexto de build al daemon. Eso es literal: el contexto es un directorio y el cliente lo comprime y lo envía al daemon. Para entender el porqué de eso, es necesario que recordemos que en la arquitectura de Docker, la herramienta de línea de comandos se comunica con un daemon (dockerd) que es el que realmente ejecuta el proceso de construcción de la imagen. Recuerda, además, que el daemon puede estar en otra máquina (de este hecho se aprovecha Docker Machine por ejemplo).
Por lo tanto, si el daemon puede estar ejecutándose en otra máquina, este necesita que se le pase todos los datos necesarios para poder construir la imagen. No le basta solo con el Dockerfile (porque en este, a través de las sentencias COPY o ADD, hacemos referencias a otros ficheros). Así, el cliente de Docker lo que hace es mandarle todo un directorio (y sus subdirectorios, por supuesto).
Cuando usamos docker build el contexto es siempre el directorio DESDE EL CUAL ejecutamos el docker build. Y, además, espera que en este directorio haya siempre un Dockerfile. Este es un patrón muy habitual y es el que hemos ido siguiendo hasta ahora. Pero no siempre tiene por qué ser así.
Cambiando el contexto en docker build
Como se ha dicho, usando docker build el contexto es siempre el directorio desde el cual ejecutamos el comando. Así, pues, para cambiar el contexto nos basta con cambiarnos de directorio antes de lanzar el comando. Claro que eso, hará que el comando falle ya que no encontrará un Dockerfile en este nuevo directorio. Para solucionarlo debemos usar el modificador -f o --file que debe contener la ruta al fichero Dockerfile a usar.
Cuando usas rutas relativas en una sentencia COPY (o ADD) esas son relativas respecto la raíz del contexto, no a la ubicación del Dockerfile. Por supuesto, una ruta relativa nunca puede empezar por ../ porque eso apuntaría a un directorio fuera del contexto (y, por lo tanto, no sería enviado al daemon).
Cambiando el contexto en Compose
No es docker build la única manera de construir imágenes. Compose también puede hacerlo, para ello tenemos la sección build del fichero Compose:
build: context: . dockerfile: Dockerfile
En este caso el contexto es el directorio actual (donde esté el fichero Compose) y el fichero Dockerfile se llama Dockerfile (ubicado en este mismo directorio). Este es el escenario habitual en que el fichero Compose y el Dockerfile van juntos.
Pero podemos modificar el contexto simplemente indicando en context qué directorio es la raíz del contexto. El valor de context: es, pues, un directorio y puede ser relativo a la ubicación del fichero Compose.
¿Y para qué quiero cambiar el contexto de build?
Hechas estas (importantes) aclaraciones, vayamos ahora a responder a la pregunta: el motivo para querer cambiar el contexto se da cuando el daemon necesita utilizar ficheros que no están en el mismo directorio (incluyendo hijos) que el directorio donde está el Dockerfile. Y esto se da muy a menudo cuando tienes ficheros compartidos por varios proyectos.
Veamos algunos ejemplos:
- En .Net Core tienes una solución (
.sln) que abarca varios proyectos (.csproj) con referencias entre ellos. Al compilar un proyecto, uno o varios deben compilarse también. De todos esos proyectos hay algunos que quieres desplegar como contenedores (los otros son proyectos de soporte). En este caso puedes tener unDockerfileen el directorio de cada proyecto, pero que el contexto de build sea el directorio raíz que contiene la solución entera. - En Node.js tienes dos APIs que usan módulos de JavaScript comunes. En este caso puedes tener un
Dockerfileen el directorio de cada API (o sea, dos diferentes), pero que el contexto de build sea el directorio superior que contiene también los módulos comunes. - En C++ tienes dos proyectos que requieren cabeceras (.h) y bibliotecas estáticas adicionales compartidas. En este caso cada proyecto puede tener el
Dockerfileen su propio directorio y el contexto de build debe ser un directorio superior que contenga todas las cabeceras y bibliotecas adicionales.
Seguro que captas la idea: el contexto de build suele ser un directorio superior al del Dockerfile, ya que nos interesa que el daemon tenga acceso al directorio del Dockerfile (e hijos) y a algunos adicionales que contienen elementos necesarios (generalmente compartidos) para la compilación y creación de la imagen.
En escenarios donde usas Compose para construir varias imágenes que tienen elementos compartidos suele ser habitual establecer el contexto de build al mismo directorio donde está el fichero Compose. Por ejemplo un sistema parecido al siguiente:
/src
docker-compose.yml
/common
shared.js
/api1
Dockerfile
api1.js
/api2
Dockerfile
api2.js
Este esquema intenta ilustrar el ejemplo de Node.js comentado antes, en el que tanto la “Api 1” como la “Api 2” utilizan un módulo compartido (shared.js). En este caso, en el fichero docker-compose.yml se establece el contexto de build al propio directorio del fichero Compose (/src) y se indica dónde está el Dockerfile en relación al contexto:
build: context: . dockerfile: api1/Dockerfile
Esto implica que el fichero Dockerfile ahora debe hacer referencia a los directorios desde la raíz del contexto. Así por ejemplo en “Api 1” podríamos usar:
WORKDIR /src COPY common ./common COPY api1 ./api1
Eso copiaría los ficheros de la carpeta common en el directorio /src/common del contenedor y la carpeta api1 en el directorio /src/api1 del contenedor manteniendo así la estructura relativa de directorios que tenemos en el código fuente.
Por supuesto podríamos hacer esto también:
WORKDIR /src COPY . .
Con esto copiamos todo el contexto de build al contenedor. Esto implica que copiaríamos no solo common y api1 sino también api2 al contenedor. Luego, las siguientes instrucciones del Docker solo compilarían api1, por lo que realmente todo lo que se ha copiado de api2 al contenedor no se usa. Como el contenedor de build es temporal, tampoco es nada excesivamente grave. Por supuesto, es mejor la primera opción que esa (los Dockerfile deben intentar siempre copiar tan solo lo necesario).
El fichero .dockerignore
El fichero .dockerignore nos permite especificar qué ficheros deben omitirse cuando la CLI manda el contexto de build al daemon. Este fichero debe estar localizado en la raíz del contexto de build y su sintaxis es muy sencilla:
- Una línea que empieza por
#es un comentario - Cada línea especifica un directorio o fichero relativo al directorio raíz del contexto de build que debe ser excluido del contexto de build
- El uso de
*/permite especificar “cualquier directorio” - El uso de
**indica cualquier número de subdirectorios, incluyendo cero. - El uso de
*especifica cualquier número de caracteres - El uso de
?indica cualquier carácter
Así, asumiendo que / es la raíz del contexto:
bin: omite el directorio/bintodo su contenido o bien el fichero/bin. A partir de ahora diremos “elemento” en lugar de decir “directorio y todo su contenido o fichero”.*/bin: omite el elemento/cualquierpath/bin, pero no omite/bin.**/bin: omite cualquier elementobinen cualquier ubicación; tanto/cualquierpath/bin, como/bin, comocualquierpath/otropath/yotromas/bin.*/*/bin: omite cualquier elementobinubicado en un subdirectorio de un subdirectorio de la raíz. Es decir, omite/cualquierpath/otropath/bin, pero no/bin, ni/cualquierpath/bin, nicualquierpath/otropath/yotromas/bin.**/bin*: omite cualquier elemento cuyo nombre empiece porbinubicado en cualquier ubicación. Así omitirá/bin,/cualquierpath/binnary-data/o/logs/bin10.txt.**/*.log: omite cualquier elemento con la extensión.logubicado en cualquier ubicación.**/temp?: omite cualquier elemento cuyo nombre seatempy un carácter más. Así omite/temp1y/cualquierpath/temp2, pero no omite/temp.
Negar una regla previa
Las líneas en el fichero .dockerignore se procesan por orden. En algunos casos nos puede interesar evitar que se omita un fichero que ha sido procesado por una regla previa más general. En este caso podemos empezar la línea con !:
*.md !readme.md
La primera línea omite todos los elementos .md (de la raíz del contexto de build). Pero el fichero readme.md sí que será incluido en el contexto debido a la segunda línea.
Recuerda que las líneas del .dockerignore se procesan secuencialmente. Por lo tanto, su orden es importante; es la última línea la que afecta a un elemento en concreto la que decide si dicho elemento se añade o no.
Así, el siguiente fichero .dockerginore:
!docs/readme-important.md **/*.md
No añade ningún fichero .md en el contexto de build, ya que la segunda línea afecta a todos los ficheros .md por lo que excluye incluso a /docs/readme-important.md. Si las líneas estuvieran invertidas, entonces sí que el fichero /docs/readme-important.md estaría incluido.
Especificar exactamente el contenido del contexto de build
Para ello basta con añadir como primera línea del .dockerignore la entrada *. Con eso se excluyen todos los elementos del fichero de build. Luego usas varias líneas con ! para especificar uno a uno los elementos que quieres.
Por ejemplo, el siguiente fichero incluye solo el contenido de /out con independencia de todo lo demás:
* !out
¡Evita excluir el Dockerfile y el propio .dockerignore usando .dockerignore porque si no, no podrás construir la imagen!
Docker-in-Docker
Se conoce como “Docker-in-Docker” (dind) a la posibilidad de ejecutar el motor de Docker desde un contenedor Docker. La primera pregunta a hacerse es ¿Eso es posible? Y la segunda es, ¿por qué querría alguien hacer eso?
Docker-in-Docker: Las posibilidades
Empezaremos por responder la segunda de las preguntas con un ejemplo: imagina que tienes un servidor de Integración Continua, por ejemplo Jenkins, que utilizas para generar todos los binarios de tu proyecto. Puesto que has visto las ventajas de usar Docker y, por lo tanto, estás empezando a usar contenedores en tus aplicaciones, entre los binarios que se generan hay varias imágenes Docker.
Pero, llega un momento en que te planteas que, en lugar de tener una máquina dedicada a Jenkins, podría ser posible ejecutar Jenkins en un contenedor, ¿no?
Igual te puede sonar extraño, pero tener tu servidor de CI (Continuous Integration) en un contenedor es algo bastante común y presenta varias ventajas. Pero volvamos al tema: quieres tener Jenkins ejecutándose en un contenedor, pero este contenedor como parte de su ejecución debe generar otros contenedores.
Este es un escenario donde Docker-in-Docker te puede ayudar.
Docker-in-Docker: La realidad
Claro que si esa lección se llama “Docker-in-Docker” eso significa que la respuesta a la primera pregunta (si es posible conseguirlo) es afirmativa. Efectivamente, se puede. Y es, sorprendentemente fácil. Abre un terminal y teclea:
docker run --privileged -d docker:dind

Ahora tienes un contenedor que está ejecutando el motor de Docker. Lo puedes verificar entrando en él y creando un contenedor (dentro del contenedor):

En la imagen anterior puedes ver como abrimos una sesión interactiva con el contenedor (usando docker exec para lanzar sh) y luego dentro del contenedor creamos otro contenedor ejecutando la imagen hello-world con un docker run.
Todo lo que está dentro del recuadro rojo de la imagen ocurre dentro del contenedor.
Entonces la imagen docker:dind, la podemos usar como punto de partida para nuestras propias imágenes en las que deseemos que se pueda usar Docker.
Docker-in-Docker: Lo malo
Ahora que ya te hemos visto qué es dind y cómo usarlo, viene la recomendación: no lo uses  Es más: seguramente no lo necesitas. Lo más probable es que creas que lo necesitas pero no sea cierto. ¿Recuerdas el ejemplo del servidor de CI que hemos usado antes? Se puede solucionar sin usar Docker-in-Docker. Luego te cuento cómo, pero ahora déjame que te diga, por qué no usar dind:
Es más: seguramente no lo necesitas. Lo más probable es que creas que lo necesitas pero no sea cierto. ¿Recuerdas el ejemplo del servidor de CI que hemos usado antes? Se puede solucionar sin usar Docker-in-Docker. Luego te cuento cómo, pero ahora déjame que te diga, por qué no usar dind:
- Tiene problemas conocidos con algunos LSM y “peta” en ejecución.
- Puede dar lugar a pérdidas de datos. La causa es que cuando usas dind, el Docker externo (el de tu máquina) se ejecuta en un sistema de ficheros tradicional, tal como ext4, btrfs o el que tengas en tu máquina. Pero el Docker “interno” (el que se ejecuta dentro del contenedor), se ejecuta en un sistema de ficheros de Docker (copy-on-write) tal como “Device Mapper” o aufs. Y, sencillamente, algunas combinaciones no van, otras solo funcionan parcialmente y otras funcionan bien pero presentan problemas de seguridad.
Así que el consejo es no usar Docker-in-Docker. Se creó con un propósito básico, que es ayudar en el propio desarrollo de Docker. Así que, a no ser que ese sea tu caso, mejor no lo uses. Si te lo hemos comentado es sólo para que sepas que existe ya que a veces es bueno conocer las cosas, incluso para saber que no debemos usarlas 
Ejecutar comandos Docker desde un contenedor
Bueno… olvidémonos de Docker-in-Docker, pero seguimos teniendo la necesidad de crear contenedores desde mi contenedor Jenkins. Por eso antes te decía que probablemente puedes pensar que necesitas dind, pero realmente no lo necesites: Docker-in-Docker va de ejecutar el daemon de Docker dentro de un contenedor Docker.
Pero para usar comandos de Docker desde dentro de un contenedor, no necesitas que el contenedor ejecute el daemon de Docker: te basta con que te tenga la CLI y tenga acceso a un deamon.
Si lo meditas unos instantes verás que daemon ya hay uno: el de la máquina que ejecuta el contenedor. Por lo tanto, si puedes conectar el cliente de Docker ejecutándose dentro de un contenedor, con el daemon de Docker de la máquina host (daemon que sabes que existe, puesto que estamos ejecutando un contenedor Docker), podrás lanzar comandos de Docker desde dentro del contenedor.
¿Y cómo de difícil es establecer esta comunicación? Pues, en realidad, es trivial…
¿Recuerdas cómo se comunican el cliente y el daemon? Efectivamente: a través de un pipe (/var/run/docker.sock). Y los pipes son como ficheros y los ficheros los puedo compartir entre el host y un contenedor usando bind mounts:
docker run -v /var/run/docker.sock:/var/run/docker.sock ...

Como en la imagen anterior, todo lo que está dentro del recuadro rojo, se ejecuta en el contenedor. Observa que se parece mucho al caso de dind. Pero eso no es Docker-in-Docker: aquí simplemente estamos ejecutando el cliente Docker dentro de un contenedor, conectado al daemon de Docker del host.
En la imagen se ve cómo ejecutamos el contenedor, con la opción -v para crear el bind mount y poder compartir /var/run/docker.sock y así que el cliente de Docker del contenedor pueda acceder al daemon de Docker. Luego, ya dentro del contenedor:
- Usamos
apt-getpara instalarcurl - Usamos
curlpara descargar la CLI de Docker - Usamos el cliente de
dockerpara ejecutar un contenedor
Ahora bien, es importante que entiendas las diferencias conceptuales entre esta solución y dind. La siguiente imagen te las clarificará:

La imagen muestra dos terminales uno al lado del otro (es muy ancha, así que quizá tengas que hacer algo de scroll dependiendo de la resolución de tu pantalla):
- En el terminal izquierdo estamos dentro del contenedor y ejecutamos
docker ps. - En el terminal derecho estamos fuera de cualquier contenedor y ejecutamos
docker ps
Observa como la salida es la misma. Desde dentro del contenedor vemos el propio contenedor al hacer docker ps, y eso es porque daemon de Docker solo hay uno: el del host. Eso con Docker-in-Docker no ocurriría: el contenedor tendría su propio daemon de Docker.
Esta opción de usar el daemon del host, es totalmente segura, funciona perfectamente y nos solventa el 99.9% de casos en los que creíamos que necesitábamos Docker-in-Docker: todos aquellos en los que queríamos ejecutar comandos de Docker desde dentro de un contenedor, como es el caso del ejemplo de Jenkins que hemos estado mencionando.
Eso también funciona con Docker for Windows usando contenedores Windows, usando los mismos comandos. Quizá te puede parecer raro que en Windows hagas un bind mount de /var/run/docker.sock (cuando eso no existe en Windows), pero la CLI de Docker en Windows es suficientemente inteligente para darse cuenta de que quieres compartir el pipe de la máquina virtual Linux que ejecuta los contenedores, y no una ruta de tu máquina Windows 
Ejecutando test con multistage build
Si has definido una batería de test unitarios, una opción es ejecutarlos como paso durante la construcción de la imagen final de Docker. Para ello puedes definir un stage adicional que ejecute los test. Vamos a verlo con un ejemplo muy sencillito, paso a paso en este caso, usando el lenguaje Rust. No te preocupes si no conoces Rust o si no tienes las herramientas de desarrollo instaladas: ¡vamos a usar Docker para todo, así que no necesitas tener nada instalado en tu máquina!
Esta lección es un poco larga y está planteada como un ejercicio para seguir paso a paso. En algunos puntos puede resultar un poco compleja. Tómate tu tiempo y no dudes en preguntar cualquier duda.
Para realizar este ejercicio, descárgate el fichero test-samples-rust.zip y descomprímelo en una carpeta vacía.
Paso 1: Ejecutar la aplicación
La aplicación de ejemplo es muy sencilla: suma dos números y muestra el resultado. Pero es lo de menos. Lo importante es que lo aprendido se puede generalizar para una aplicación real.
Para ejecutar el proyecto podemos usar un contenedor de Docker a partir de la imagen rust:1.62-buster con el siguiente comando:
docker run -v "$(pwd):/app" rust:1.62-buster cargo run --manifest-path=/app/Cargo.toml
Este comando solo te funcionará en Powershell o en Linux. Si usas cmd.exe (el “símbolo del sistema” tradicional de Windows) debes sustituir $(pwd) por el nombre completo de la carpeta donde hayas descomprimido el fichero.
La salida del comando será parecida a la siguiente:

Aunque a estas alturas del curso ya lo conoces, no está de más repasar lo qué hace este comando para que quede claro:
docker run: crea un contenedor-v “$(pwd):/app: establece un bind mount que monta el directorio actual del host al directorio/appdel contenedorrust:1.62-buster: imagen a usar (contiene el SDK de Rust).cargo run --manifest-path=/app/Cargo.toml: comando de la imagen. En este caso usamoscargo runque es la forma habitual en Rust de ejecutar proyectos. El parámetro--manifest-pathle indica a Rust donde está el proyecto a ejecutar.
Paso 2: Ejecutar los test
La aplicación viene con test (los puedes ver en el fichero src/adder.rs). Son dos test llamados test_add y test_add_negative que verifican el funcionamiento de la función add_positive. Los puedes ejecutar usando Docker con el siguiente comando:
docker run -v "$(pwd):/app" rust:1.62-buster cargo test --manifest-path=/app/Cargo.toml
Observa que es el mismo comando de antes, pero sustituyendo cargo run por cargo test para ejecutar los test en lugar de la aplicación. Al igual que antes, si usas cmd.exe debes sustituir $(pwd) por la ruta completa de la carpeta donde hayas descomprimido el fichero.
La salida del comando será parecida a la siguiente:

Puedes ver como ambos test han pasado correctamente.
Paso 3: Creando un Dockerfile
Vamos a crear un Dockerfile para terminar generando una imagen, pero añadiremos un stage para ejecutar los test como parte de la construcción de la misma:
FROM rust:1.61-buster as test WORKDIR /app COPY Cargo.toml . COPY src/ ./src RUN cargo test FROM test as build RUN cargo build --profile release FROM debian as final WORKDIR /app COPY --from=build /app/target/release/adder . RUN chmod +x adder ENTRYPOINT ["/app/adder"]
Este Dockerfile define tres stages:
test: el primer stage ejecuta el comandocargo testpara pasar los test unitariosbuild: el segundo stage ejecuta el comandocargo buildpara generar el ejecutable final. El resultado decargo buildes un único fichero ejecutable (en el directorio/app/target/release).final: el último stage copia el ejecutable generado en el stagebuildy lo establece como entrypoint de la imagen. En este caso partimos de la imagen genérica dedebianya que Rust es un lenguaje que compila a nativo y no tiene un runtime específico.
Ahora ya puedes usar docker build para construir la imagen.
La salida del comando (asumiendo que tienes las imágenes base ya descargadas) será parecida a la siguiente:

Si observas con atención la imagen, verás que se ejecuta el comando cargo test (de hecho la salida de dicho comando aparece brevemente mientras la imagen está siendo construida).
Paso 4: Simulando un test que falle
Vamos a hacer que uno de los test falle. Para ello te basta con editar el fichero /src/adder.rs y en la línea 13 cambiar:
assert_eq!(add_positive(1, 2), 3);
por:
assert_ne!(add_positive(1, 2), 3);
El cambio es sustituir assert_eq por assert_ne. Con eso modificamos el test de modo que verifique que 1+2 es distinto de 3 (cosa que no sucederá y por lo tanto el test fallará).
Si ahora intentas construir la imagen verás que el comando docker build termina fallando, ya que al ejecutar los test hay uno que no pasa y entonces cargo test devuelve un error que interrumpe la generación de la imagen:

Así pues, ¡si los test unitarios no pasan, la imagen Docker no se genera!
¡Acuérdate de deshacer el cambio para que los test vuelvan a pasar!
Paso 5: Integrando con algún sistema de CI (integración continua)
Es habitual tener un sistema de integración continua (CI) que genere las imágenes cuando se suba código nuevo al repositorio. Una de las ventajas que tiene el ejecutar los test como parte del Dockerfile es que la definición de las pipelines de CI se simplifica, ya que no hay que tratar los test como algo adicional. Pero viene con un problemilla adicional de regalo: hay que conseguir extraer el fichero de resultados de test para poder pasárselo al sistema de CI.
Este fichero es importante porque es el que permite que el sistema de CI nos muestre los resultados de los test desde su propia interfaz. Existen varios formatos de resultados de test y cada sistema de CI es compatible con algunos de ellos. Es importante tener presente que la tecnología que uses (Java, Rust, .NET o lo que sea) pueda generar esos ficheros de resultados en el formato que espera tu sistema de CI. En caso contrario no podrás integrar los resultados de los test.
Uno de los formatos más usados es el de JUnit. Vamos a ver cómo podemos generar este fichero de resultados con nuestro ejemplo. Por supuesto, eso depende de cada tecnología utilizada. El objetivo es mostrarte solo un ejemplo para que luego puedas adaptarlo a tus necesidades concretas.
En Rust existen varias formas de conseguir el fichero de resultados en formato JUnit. En este ejemplo lo haremos usando cargo nextest que se trata de una herramienta adicional para ejecutar test en Rust con funcionalidades extra.
Así, vamos a modificar el stage de test del Dockerfile de la siguiente forma:
- Descargaremos
cargo nextesty lo instalaremos - Añadiremos un fichero de configuración para indicarle a
cargo nextestque queremos generar el fichero de resultados en formato JUnit - Cambiaremos el comando
cargo testporcargo nextestpara ejecutar los test usando cargo nextest.
El nuevo stage queda tal y como sigue (el resto del Dockerfile sigue sin cambios):
FROM rust:1.61-buster as test
RUN curl -LsSf https://get.nexte.st/latest/linux | tar zxf - -C ${CARGO_HOME:-~/.cargo}/bin
WORKDIR /app
RUN mkdir ./.config && echo '[profile.ci.junit]\n\
path = "testresults.xml"\n'\
>> ./.config/nextest.toml
COPY Cargo.toml .
COPY src/ ./src
RUN cargo nextest run --profile ci
- La línea 2 (
RUN curl…) es la encargada de descargar cargo nextest e instalarlo - A partir de la línea 4 y hasta la línea 6, tenemos un comando multilínea (observa el separador
\final). Lo que hace es crear el fichero de configuración.config/nextest.tomlque usa cargo nextest. - Finalmente la última línea (la 9) invoca
cargo nextestpara ejecutar los test y crear el fichero de resultados en formato JUnit.
Observa cómo puedes crear comandos multilínea en el Dockerfile, simplemente usando el carácter \ para indicar que el comando continúa en la siguiente línea (al igual que puedes hacer en un terminal de Linux).
Si ahora construyes la imagen con docker build, el fichero de resultados es generado en el stage test pero luego es ignorado y se pierde en la imagen final. Así tenemos que buscar una manera de “sacar” este fichero, y ahí es donde nos ayuda el modificador target de docker run.
El modificador target de docker run
Este modificador lo que te permite es construir una imagen hasta un stage en concreto. O sea, en lugar de ejecutar todo el Dockerfile, ejecutarlo solo hasta el stage indicado. En nuestro caso podemos generar una imagen con el contenido del stage test con el comando:
docker build --target test -t addertest .
Este comando genera una imagen llamada addertest que es el resultado de ejecutar el stage de test (y todos sus stages previos, si los hubiese).
Podemos crear un contenedor y ver que, efectivamente, tenemos el fichero de resultados generados. Para crear el contenedor podemos usar docker run -it addertest /bin/bash. Eso abrirá una sesión interactiva contra /bin/bash (podemos ejecutarlo, porque la imagen rust:1.61-buster incluye bash). En esta sesión podemos navegar hacia el directorio targets/nextest/ci y allí estará el fichero (es en formato XML y se llama testresults.xml):

Usar docker cp para extraer el fichero (de un contenedor)
Si quieres extraer este fichero, existen dos opciones:
- Puedes usar el comando
docker cppara sacar el fichero del contenedor - Puedes usar
docker savepara guardar la imagen en disco (en formato comprimido) y luego buscar el fichero dentro del archivo comprimido.
Si optas por la primera aproximación, debes saber que docker cp funciona a nivel de contenedor, no de imagen, por lo que necesitas tener antes un contenedor. No es necesario que esté en marcha, pero debes tenerlo. En este caso el comando docker cp <id-contenedor>:/app/target/nextest/ci/testresults.xml . copiará el fichero del contenedor al sistema de ficheros de tu máquina:

En la imagen anterior se puede ver cómo uso el comando docker cp contra un contenedor de la imagen addertest y copio el fichero testresults.xml a mi máquina local.
El comando docker cp se estudia con más detalle en el módulo “Depurar contenedores”
Como se ha comentado, esta aproximación requiere tener un contenedor que haya ejecutado la imagen. Pero, en realidad, los contenedores de la imagen addertest no ejecutan nada útil (recuerda que el fichero de resultados de JUnit que es lo que queremos, se crea al crear la imagen y forma parte de esta). Si usaras esta aproximación en tu sistema de CI, deberías crear un contenedor que terminase en el momento (en nuestro caso bastaría con un docker run addertest ya que la imagen base de Rust ejecuta un bash por defecto, de forma que al hacer docker run se ejecutaría este bash que terminaría al momento por no tener un terminal enlazado). Lo puedes automatizar con los siguientes comandos:
id=$(docker run addertest) docker cp $id:/app/target/nextest/ci/testresults.xml . docker rm $id
Nota: ¿Cómo sé que la imagen base de Rust ejecuta un bash por defecto? Bueno, una forma es probarlo, es decir, ejecutar un contenedor con docker run y luego mirar (con docker ps) el comando ejecutado:

Otra opción sería usar el comando docker history sobre la imagen de Rust y mirar la última capa que tenga un CMD o un ENTRYPOINT:

Pero existe otra opción, que en nuestro caso es todavía mejor: usar el comando docker create. Este comando crea un contenedor de la imagen especificada pero no lo pone en marcha, lo que es ideal cuando lo único que quieres es poder usar luego docker cp para poder sacar un fichero del contenedor. ¡Así no tienes por qué preocuparte de cual es el comando inicial que el contenedor ejecuta!
Un ejemplo (GitHub Actions)
Para realizar este ejercicio (totalmente opcional) necesitas una cuenta de GitHub, así como tener Git instalado en tu máquina.
Vamos a ver un ejemplo de integración con GitHub Actions, un sistema de CI muy utilizado ya que está disponible incluso en los planes gratuitos de GitHub. Por supuesto cada sistema de CI funciona de una forma distinta, pero el objetivo es que veas lo que hemos comentado en esta lección funcionando en un sistema “del mundo real”. ¡Vamos allá!
Lo primero que necesitas es crear un repositorio vacío en GitHub. Es importante que no inicialices el repositorio de manera alguna (por ejemplo, al crearlo no marques la casilla de “Initialize this repository with a README”, ni añadas un fichero .gitignore, ni tampoco ninguna licencia.
Una vez tengas el repositorio creado, crea una carpeta vacía en tu disco y descomprime en ella el fichero github-actions-tests-demo.zip. Esta carpeta contiene el ejercicio anterior, junto con el Dockerfile completado:

También vas a ver una carpeta .github que dentro tiene otra carpeta llamada workflows. Esta es la ubicación donde GitHub Actions espera que esté la definición de las pipelines de CI/CD.
Una pipeline no es nada más que la secuencia de acciones que se deben ejecutar para construir (CI) o desplegar (CD) nuestro sistema. En el caso de GitHub Actions, se definen en ficheros en formato YAML. Este ejemplo cuenta con una sola pipeline definida en el fichero ci.yaml.
Finalmente ejecuta los siguientes comandos desde la carpeta a la que has descomprimido el fichero github-actions-tests-demo.zip:
git init git add . git commit -m "first commit" git branch -M main # En el próximo comando: # xxxx es tu nombre de usuario de GitHub # yyyy es el nombre del repositorio que has creado git remote add origin https://github.com/xxxx/yyyy.git git push -u origin main
Estos comandos son los mismos que te indica GitHub cuando creas el repositorio vacío. No obstante en los comandos que te indica GitHub, el comando git add es git add README.md, pero en nuestro caso debemos sustituirlo por git add . para subir todo el contenido.

Fíjate que, en la captura, mi repositorio se llamaba eiximenis/dockerjunittest.git, pero el tuyo será otro.
El mero hecho de haber subido el código a GitHub, hará que se ejecute nuestra pipeline de CI (ya que existe el fichero /.github/workflows/ci.yaml). Si te vas a la pestaña de “Actions” de GitHub vas a ver la pipeline ejecutada:

En la captura de pantalla se ve el listado con una pipeline (“workflow” en la jerga de GitHub) ejecutada. Esta pipeline se corresponde con el código que hemos subido antes con git push.
Observa que el título se corresponde con el mensaje que pusiste al realizar el git commit, en mi caso “Initial commit”.
Si pulsas sobre el título, irás a la página de detalles de la ejecución de la pipeline:

Lo importante aquí es ver como tenemos resultados de test disponibles: en el listado de “Jobs” de la izquierda nos aparece un “Unit Test Results”. Si pulsas sobre él, podrás ver los resultados de los test:

¡Observa que había dos test y que ambos han pasado! Esa información es la que saca GitHub del fichero testresults.xml que hemos sacado de la imagen.
Ahora cada vez que subas código a ese repositorio se ejecutará esa pipeline y ¡podrás ver los resultados de los test!
(Opcional) Una breve explicación sobre GitHub Actions y cómo funciona la pipeline
Este no es un curso de técnicas de CI/CD en general ni de GitHub Actions en particular, pero creo necesario explicarte brevemente cómo funciona la pipeline que hemos creado. Este apartado es totalmente opcional dentro de esta lección, así que siéntete libre de saltártelo si ya lo conoces, no lo consideras relevante o, simplemente, no te apetece. No te preguntaremos nada sobre él
Como se ha mencionado antes, la existencia de ficheros YAML en la carpeta .github/workflows es lo que le indica a GitHub Actions qué pipelines debe ejecutar y cuando. A continuación se desgrana el fichero ci.yaml y se comenta brevemente para que sepas qué hace.
La primera parte es la definición general de la pipeline:
name: Demo de CI con tests en Docker on: workflow_dispatch: push: branches: - main
Se la otorga un nombre y luego, mediante on, se indica cuando debe ejecutarse. En este caso en cada push a la rama main y también de forma manual, como indica el apartado workflow_dispatch.
Una pipeline de GitHub Actions está compuesta por uno o más trabajos (jobs):
jobs: build-and-test: runs-on: ubuntu-latest
Cada trabajo se ejecuta en una máquina (agente) que provee GitHub de forma automática. Estos agentes llevan una serie de software preinstalado (como p. ej. Docker). En nuestro caso le indicamos a GitHub que queremos que este trabajo se ejecute en un agente cuyo SO sea un Ubuntu.
Cada trabajo se compone de un conjunto de pasos (steps) a realizar, y cada paso es lo que conocemos como action en la jerga de GitHub Actions:
steps: - name: Checkout uses: actions/checkout@v2 with: persist-credentials: false
Algunas de esas actions están incorporadas de serie, pero la mayoría son externas y se encuentran en repositorios de GitHub. Las actions externas se identifican porque usan el atributo uses. El valor de este atributo indica realmente el repositorio de GitHub que contiene el código de la action. En este ejemplo el repositorio actions/checkout. Esta action lo que hace es traerse el código fuente del repositorio hacia el agente.
A continuación hay otro paso más:
- name: Build to tests stage uses: docker/build-push-action@v3 with: tags: addertests:latest target: test
En este se utiliza la action docker/build-push-action para construir la imagen de Docker, pero sólo hacia el stage de test (atributo target).
El siguiente paso es usar docker cp para copiar el fichero testresults.xml de un contenedor creado a partir de la imagen que hemos construido en el paso anterior:
- name: Copy JUnit test file run: | id=$(docker create addertests:latest) docker cp $id:/app/target/nextest/ci/testresults.xml . docker rm $id
En este caso usamos la action run, que está predefinida y que ejecuta una serie de sentencias de línea de comandos que le indiquemos. Observa que podemos usar directamente docker porque está preinstalado en los agentes.
Por supuesto, podríamos haber usado run en el paso anterior, en lugar de docker/build-push-action. La decisión de cuando usar una action externa o bien run depende de varios factores: en general las actions externas nos evitan tener que conocer la sintaxis exactas de las herramientas que usan y son capaces de instalar software adicional en el agente. A cambio, a veces son menos flexibles.
La siguiente action publica un fichero de resultados en formato JUnit al sistema de GitHub Actions, para que podamos luego ver los resultados:
- name: Publish test results uses: EnricoMi/publish-unit-test-result-action@v1 with: files: "testresults.xml"
El fichero indicado (atributo files) debe estar en el sistema de ficheros del agente, que es lo que conseguimos con el paso anterior cuando usamos docker cp.
Finalmente, generamos la imagen final de Docker, usando de nuevo la action docker/build-push-action:
- name: Build final Docker image uses: docker/build-push-action@v3 with: tags: adder:latest
Ejercicios propuestos
Paso a paso: crear una aplicación .Net y compilarla usando a Docker
Empieza creando un directorio nuevo en tu ordenador y sitúate en él. En este directorio crearemos una aplicación .Net y la ejecutaremos todo ello con Docker.
Paso 1: Crear la aplicación
Para crear la aplicación vamos a lanzar el comando dotnet new mvc. Este comando se instala con el SDK de .Net Core, pero nuestro objetivo es no tener que instalarlo. Para ello vamos a usar la imagen mcr.microsoft.com/dotnet/sdk:6.0.
Microsoft migró, hace algún tiempo, a un repositorio propio de imágenes de Docker (llamado MCR). Todas las imágenes nuevas están en este repositorio (mcr.microsoft.com), aunque las antiguas siguen (por compatibilidad) en el Docker Hub. Así, para la versión 2.0 la imagen del SDK era microsoft/aspnetcore-build:2.0 mientras que a partir de la versión 3.0 ya se encuentran todas en el MCR. De todos modos el ejercicio funciona con todas las versiones.
- Descarga la imagen
- Ejecuta un contenedor de esta imagen con un bind mount de forma que el directorio
/appdel contenedor sea el directorio nuevo del host que has creado al principio. Este contenedor debe ejecutar el comandodotnet new mvc
Ahora en tu directorio del host deberías tener varios archivos y directorios, entre ellos el app.csproj. ¡Has creado el proyecto!
Paso 2: Compilar la aplicación
Usa de nuevo un contenedor de la imagen mcr.microsoft.com/dotnet/sdk:6.0 para ejecutar dotnet publish -o out sobre los ficheros del host.
En el subdirectorio out del host deberías tener la aplicación compilada.
Paso 3: Ejecutar la aplicación
Ahora vamos a usar la imagen mcr.microsoft.com/dotnet/aspnet:6.0 un Dockerfile para crear un contenedor que:
- Copie el contenido de
outen un directorio - Establezca este directorio como directorio de trabajo
- Exponga el puerto 80
- Ejecute
dotnet ejercicio.dll
Una vez lo tengas, crea la imagen y un ¡contenedor para ejecutar la aplicación! Accede a http://localhost:port con el puerto que hayas mapeado en el host para ver la web.
Paso 4: Usa una multi stage build
Observa que ahora si modificas el código fuente debes repetir los pasos 2 y 3. Para evitar eso, crea una multi stage build, que te permita compilar y ejecutar mediante un solo Dockerfile.
Solución a los ejercicios
A petición de varios alumnos a los que le resultaba complicado solucionar el ejercicio, se proporciona esta guía paso a paso para hacerlos. Por favor, no te limites a verla y ya está. Primero intenta solucionarlos por tu cuenta y luego lee esto si no te salen o si deseas contrastar tu forma de solucionarlo con esta. Será lo mejor para tu aprendizaje.
Paso 1: Crear la aplicación
Para descargar la imagen usa el comando docker pull:
docker pull mcr.microsoft.com/dotnet/sdk:6.0
Ahora debes crear un directorio en tu máquina y situarte en él. Luego ejecuta el comando:
docker run -v [path_local]:/ejercicio mcr.microsoft.com/dotnet/sdk:6.0 dotnet new mvc -n ejercicio

Dependiendo de la versión de la imagen usada te pueden aparecer distintos ficheros. No te preocupes por ello.
Observa el uso de -v para definir el bind mount y luego de -n en el comando dotnew new mvc para darle un nombre al proyecto. Este nombre es a su vez el directorio (dentro del contenedor) donde se generará el proyecto, de ahí que sea el mismo que el segundo valor de -v (ejercicio en el ejemplo).
Paso 2: Compilar la aplicación
Para ello usa el comando:
docker run -v [path_local]:/ejercicio mcr.microsoft.com/dotnet/sdk:6.0 dotnet publish ejercicio -o ejercicio/out

Paso 3: Ejecutar la aplicación
El Dockerfile es tal y como sigue, y lo debes tener situado en el directorio que has creado:
FROM mcr.microsoft.com/dotnet/aspnet:6.0 COPY out/ /app EXPOSE 80 WORKDIR /app ENTRYPOINT ["dotnet", "ejercicio.dll"]
Para construir la imagen el comando necesario es: docker build -t ejercicio .
Para ejecutarlo, recuerda usar -p para vincular un puerto local al puerto 80 del contenedor (P. ej. docker run -p 8080:80 ejercicio).
Paso 4: Usa una multi stage build
Hay varios posibles Dockerfile que puedes usar. Te muestro uno de ellos:
FROM mcr.microsoft.com/dotnet/sdk:6.0 AS build WORKDIR /src COPY ["ejercicio.csproj", ""] RUN dotnet restore "./ejercicio.csproj" COPY . . WORKDIR "/src/." RUN dotnet build "ejercicio.csproj" -c Release -o /app/build RUN dotnet publish "ejercicio.csproj" -c Release -o /app/publish FROM mcr.microsoft.com/dotnet/aspnet:6.0 AS final WORKDIR /app EXPOSE 80 EXPOSE 443 WORKDIR /app COPY --from=build /app/publish . ENTRYPOINT ["dotnet", "ejercicio.dll"]