Tabla de Contenidos
Exponer la aplicación al exterior
Notas del curso Docker a fondo e Introducción a Kubernetes: aplicaciones basadas en contenedores
En este módulo vamos a ver las técnicas que nos ofrece Kubernetes para exponer nuestra aplicación al exterior. Se trata de un módulo que puede ser ligeramente complicado porque, dependiendo de la infraestructura que tengamos, este acceso puede hacerse de diversas maneras.
Al finalizar el estudio serás capaz de entender los métodos que tiene Kubernetes para exponer una aplicación al exterior, las ventajas e inconvenientes de cada uno y sus limitaciones… y por el camino aprenderás algunas cosillas más sobre “la filosofía de Kubernetes”.
¿Qué más se puede pedir?
Servicios NodePort
Para exponer una aplicación (o sea un pod) en Kubernetes necesitamos hacerlo siempre a través de un servicio. Ya conoces los servicios, fue uno de los primeros objetos que introdujimos. De hecho, los servicios son el mecanismo para “exponer” pods ya sea internamente o externamente (de ahí que el comando imperativo para crearlos se llame kubectl expose).
En su momento te comenté que la IP del servicio (llamada ClusterIP) es una IP privada y que no puedes acceder desde el exterior del clúster y eso es cierto. Pero la realidad es que al crear el servicio puedes especificar algún mecanismo para acceder a él desde fuera del clúster. Según el mecanismo que elijas tendrás un tipo de servicio u otro:
- Servicio ClusterIP: son los que has visto hasta ahora. Inaccesibles desde fuera del clúster.
- Servicio NodePort: los que vamos a ver en esta lección. Accesibles a través de un puerto en concreto de los nodos.
- Servicio LoadBalancer: los veremos en la siguiente lección

Crear un servicio NodePort
Crear un servicio NodePort es muy sencillo. Dado el YAML de un servicio sólo debes establecer el valor de spec.type en NodePort:
apiVersion: v1 kind: Service metadata: name: hello-svc-declarative spec: ports: - port: 80 type: NodePort selector: run: hello-declarative
No necesitas nada más. Con esto le indicas a Kubernetes que el servicio es de tipo NodePort. ¿Y qué significa eso exactamente? Pues que Kubernetes abrirá un puerto en los nodos del clúster y accediendo a cualquier nodo por ese puerto te estará respondiendo el servicio.
Da igual el nodo al que accedas, accediendo a la IP de cualquier nodo por el puerto indicado (llamamos, como no, nodeport a ese puerto) la petición será redirigida de forma transparente al servicio. Y el servicio la redirigirá a uno de los pods que tenga bajo su paraguas. Por lo tanto, es perfectamente posible que el pod que te responda esté en otro nodo al cual tú has hecho la petición. Pero eso da igual, Kubernetes se encarga de los detalles.
Imagina el siguiente deployment:
apiVersion: apps/v1 kind: Deployment metadata: name: hello spec: selector: matchLabels: app: hello template: metadata: labels: app: hello spec: containers: - name: hello image: dockercampusmvp/go-hello-world ports: - containerPort: 80 name: http
Nada nuevo bajo el sol, ¿verdad?
Bueno, igual te has fijado en el atributo name que está en el puerto (name: http). Eso simplemente le da nombre a ese puerto (el nombre puede ser el que quieras). Luego, como verás, podemos usar ese nombre (http) en lugar del número (80) para referirnos al puerto. Es útil porque, no sé tú, pero a mí me resulta más sencillo recordar nombres que números
Veamos ahora el YAML del servicio NodePort:
apiVersion: v1 kind: Service metadata: name: hello spec: selector: app: hello ports: - name: http port: 8080 targetPort: http type: NodePort
Observa como en spec.ports.targetPort usamos el nombre http que hemos definido en deployment en lugar del valor. Por otro lado, que no te confunda que spec.target.ports.name también tenga el valor de http. El nombre del puerto en el servicio y en el pod no tienen porqué coincidir.
Observa que este servicio escucha por su 8080 y redirige el tráfico al puerto http (el 80) del pod. Y observa el type: NodePort para indicar que queremos que sea de tipo NodePort.

La captura te muestra la salida del comando kubectl get svc con este servicio creado. Observa la columna PORT(S) que pone 8080:31570. Eso significa que el servicio es de tipo NodePort y que, si accedes a cualquier nodo del clúster usando el puerto 31570, accederás al servicio.
Para probarlo en Minikube necesitas saber la IP del nodo que ejecuta Minikube, no es localhost. A pesar de que Minikube se ejecute en tu máquina, se está ejecutando bien como un contenedor (si instalaste Minikube con el driver de Docker) o bien en una máquina virtual. Sea como sea, tendrá su propia IP. Y para obtenerla Minikube nos da el comando minikube ip.
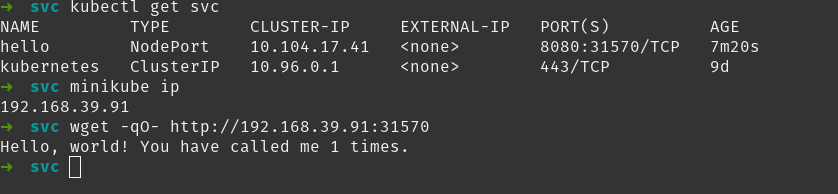
En la captura se ve el comando minikube ip y como luego se usa wget para acceder a la IP del nodo, por el puerto 31570 y como responde el servicio (es decir, uno de los pods que está debajo de este servicio).
También podemos obtener la URL del servicio que tiene expuesto su puerto mediante minikube service hello --url (devolvería http://192.168.39.91:31570/, para nuestro ejemplo). Si no le pasámos el parámetro --url, minikube abrirá un navegador con la URL del servicio.
Especificar el puerto
Si no indicas nada, Kubernetes asignará un nodeport al azar entre el rango 30000 y 32767, pero a veces te puede interesar ser tú quien indique el puerto a usar para cada servicio. En este caso, simplemente, debes establecer el valor spec.ports.nodePort al valor correspondiente.
Ese rango de posibles puertos (30000-32767) se puede modificar usando el modificador --service-node-port-range al iniciar Kubernetes. Si usas un Kubernetes en el cloud lo más probable es que no puedas modificar ese rango, pero como verás en breve, tampoco te va a importar demasiado.
Recuerda que un servicio puede tener varios puertos. Si el servicio es un servicio NodePort cada puerto del servicio se expondrá por un nodeport distinto.
Servicios LoadBalancer
El siguiente tipo de servicio que vamos a ver es el servicio de tipo LoadBalancer. Se trata, de hecho, del otro mecanismo que nos da Kubernetes para exponer un servicio al exterior. Y se trata de un tipo peculiar porque Kubernetes, por defecto, no sabe qué hacer con un servicio de tipo LoadBalancer.
Y es que los servicios LoadBalancer están pensados para ser usados en Kubernetes que se ejecutan en entornos cloud. Recuerda que un servicio NodePort requiere que accedamos a los nodos a través de un cierto puerto para poder acceder al servicio. En un entorno on premises eso lo podemos solucionar de dos formas:
- Los nodos de Kubernetes son directamente accesibles desde nuestra red, por lo que podemos acceder a ellos.
- Los nodos de Kubernetes están en alguna otra subred y accedemos a ellos usando un balanceador de carga que hemos configurado a mano.
La primera opción es la más sencilla y no requiere de mucho trabajo, pero en según qué escenarios (por seguridad) puede no ser posible. En estos casos, tocará configurar un balanceador para que cuando accedamos al balanceador por un cierto puerto se nos redirija a uno de los nodos por otro puerto. De este modo, el balanceador hace de “puerta de enlace” entre nuestra máquina y los nodos de Kubernetes.
Imagina un Kubernetes con dos nodos con IPs 10.100.0.1 y 10.100.0.2. Tienes un servicio cuyo nodeport es 31000. Eso significa que puedes acceder al servicio usando 10.100.0.1:31000 o bien 10.100.0.2:31000. Pero, en la configuración de red que tienes desde tu máquina, no tienes acceso a las IPs de los nodos.
Solo puedes acceder a un balanceador a través de la IP 10.100.0.255. En este caso, alguien ha configurado el sistema manualmente, asignando esta IP al balanceador para que cuando se llame a dicho balanceador por el puerto 31000 se redirija a cualquiera de los nodos del clúster.
Por lo tanto, cuando tú quieras llamar al servicio usarás la dirección 10.100.0.255:31000. Es decir, usarás la IP asignada al balanceador quien redirigirá la petición a uno de los nodos, quien la mandará al servicio, quien la mandará al pod. Esa configuración y asignación de IPs al balanceador se hace a mano por alguien del equipo.
Pues bien, esa situación en la que no tienes acceso a los nodos del clúster es la habitual en el cloud. El problema es que si cada vez que despliegas un servicio en el cloud debes configurar un balanceador, no sería muy operativo. Y para eso están los servicios LoadBalancer.
Cuando se crea un servicio de tipo LoadBalancer, este se expone a través de un balanceador de carga propio del cloud. Es decir, toda esa configuración que en on premises es manual, en el cloud está automatizada. Por supuesto, eso requiere que cada Kubernetes del cloud (por ejemplo, GKE en Google Cloud o AKS en Azure) tenga un módulo específico encargado de realizar esa configuración. Este módulo debe implementar una interfaz que define Kubernetes, pero la implementación es propia de cada cloud.
Por lo tanto, un servicio LoadBalancer termina recibiendo una IP pública y debemos acceder a él usando la IP pública y el puerto del servicio. Cómo se asigna la IP depende de cada implementación de cloud, pero cada servicio LoadBalancer recibe una IP pública distinta.
Un servicio LoadBalancer es también un servicio NodePort (quien a su vez es también un servicio ClusterIP). Así, podemos decir que, hay tres maneras de acceder a un servicio LoadBalancer: usando la IP externa del balanceador y el puerto del servicio, usando la IP de cualquier nodo (si tenemos acceso a ellos) y el nodeport o usando la ClusterIP y el puerto del servicio desde dentro del clúster
Minikube nos permite simular servicios LoadBalancer:
apiVersion: v1 kind: Service metadata: name: hello spec: selector: app: hello ports: - name: http port: 8080 targetPort: http type: LoadBalancer
Este fichero define un servicio LoadBalancer. Puedes ver como el valor de spec.type es LoadBalancer. No es necesario indicar nada más. Con eso le indicamos a Kubernetes que queremos que configure el balanceador de carga asociado.
Una vez despliegues el fichero en el clúster, el comando kubectl get svc te dará la IP externa del servicio en la columna EXTERNAL-IP.

En la imagen puedes ver la salida del comando kubectl get svc y observa como:
- El servicio tiene nodeport (el
31570en la imagen). Eso es porque los servicios LoadBalancer son también NodePort - El valor de
EXTERNAL-IPes<pending>. Desde que creas el servicio hasta que este obtiene una IP externa puede pasar algún tiempo (el tiempo que tarde Kubernetes en configurar el balanceador). No obstante, si hubiera algún error al configurar el balanceador, Kubernetes no te informará de ello directamente yEXTERNAL-IPse quedará en<pending>eternamente. Para ver detalles del error debes usar el comandokubectl describe svcdonde (con suerte) encontrarás detalles del error.
En entornos cloud hay varios errores que pueden hacer que un servicio LoadBalancer no reciba una IP pública: quizá la conexión entre el clúster y el balanceador ha fallado (muchas veces hay que configurar permisos), quizá te has quedado sin IPs públicas, etc…
Existe un proyecto, llamado MetalLB cuyo objetivo es dar soporte a servicios LoadBalancer a Kubernetes instalados on premises.
En Minikube, por defecto, la EXTERNAL-IP se quedará eternamente en <pending>, debido simplemente a que Minikube no tiene ningún balanceador de carga asociado.
Acceder a un servicio LoadBalancer en Minikube
Esa sección es propia de Minikube. En un Kubernetes con soporte LoadBalancer simplemente accederíamos a la IP pública indicada en EXTERNAL-IP y nos respondería el servicio
Minikube nos permite simular servicios LoadBalancer pero para poder acceder a ellos debemos usar el comando minikube tunnel. Este comando bloquea la terminal así que es mejor lanzarlo desde otra terminal distinta:
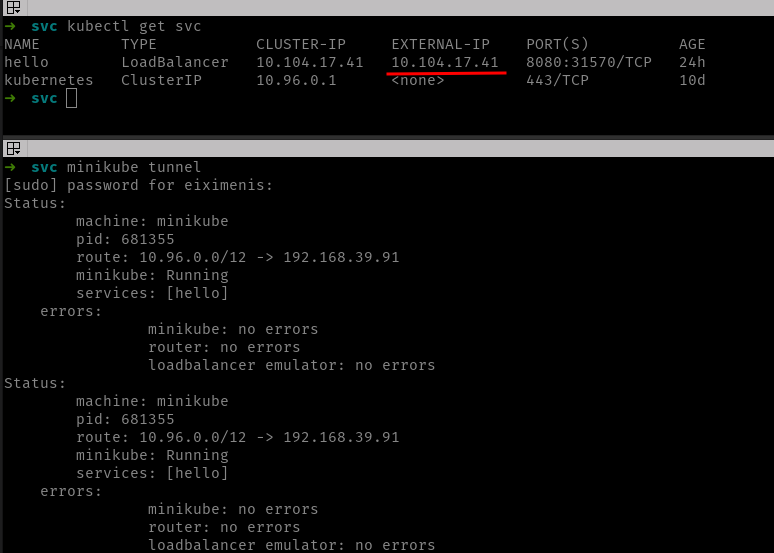
En la imagen de arriba se ven dos terminales. En el inferior está corriendo el comando minikube tunnel. Este comando crea un emulador de balanceador de carga, así que mientras este emulador se está ejecutando, el servicio obtiene, ahora sí, una IP externa (10.104.17.41). Accediendo a esta IP (siempre mientras el comando minikube tunnel se está ejecutando) responderá el servicio:

Observa cómo accedo al servicio usando la IP externa y el puerto del servicio. ¡Ojo! El puerto del servicio, ¡no el nodeport!
Ejercicio: el problema de los servicios LoadBalancer
El principal problema de los servicios LoadBalancer es que cada servicio obtiene una IP distinta y eso puede dar lugar a que se agoten las IPs, ya que estas son un recurso limitado.
Igual te estás preguntando cuál es la solución a ese problema o igual directamente ya la estás imaginando, ¿verdad?
Una solución podría ser la sencilla:
- Creamos un deployment que ejecute algún proxy inverso como pueda ser NGINX
- Exponemos este proxy inverso al exterior a través de un servicio LoadBalancer
- Configuramos ese proxy inverso para que en función de rutas, hosts virtuales, etc., nos llame a un servicio ClusterIP u otro. Como el proxy se ejecuta como un pod en el interior del clúster tiene acceso a los servicios ClusterIP.
Con eso consigues exponer dos, tres o los servicios que quieras al exterior a través de una única IP. El único servicio LoadBalancer es el que expone NGINX al exterior.
Por supuesto, lo mismo aplica a servicios NodePort. Es decir, puedes exponer todos tus servicios a partir de un único servicio NodePort que exponga NGINX.
¡Vamos a probarlo! Te propongo un ejercicio, que además te servirá de repaso de todo lo que hemos visto hasta ahora.
Ejercicio propuesto: Desplegar y configurar NGINX
El esquema que queremos obtener es parecido al siguiente:
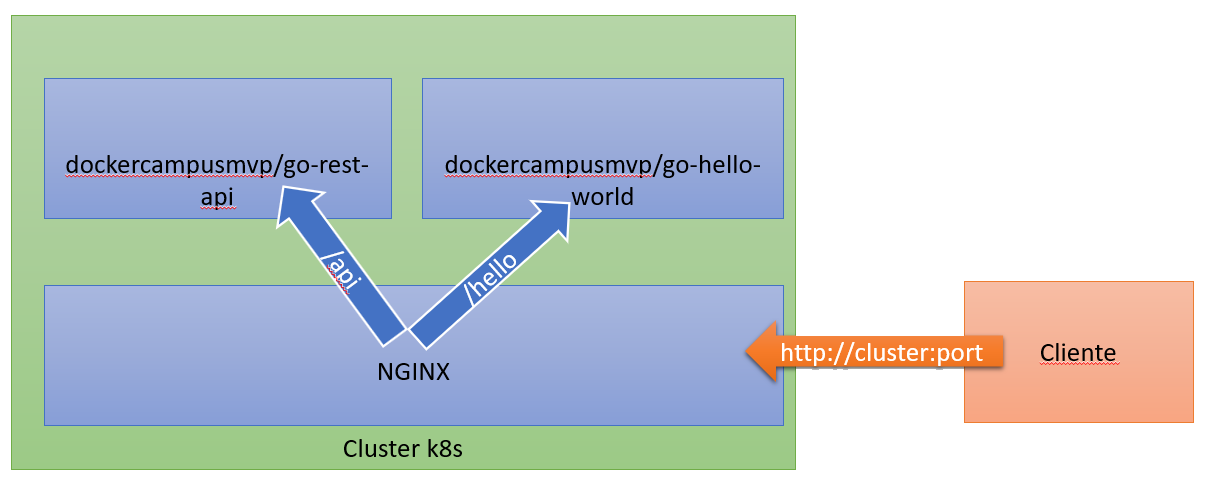
Vamos a usar tres imágenes en este ejercicio:
dockercampusmvp/go-hello-world: ya la hemos usado varias veces y es nuestro hello worlddockercampusmvp/go-rest-api: es una API REST de ejemplo hecha en Gonginx:1.23.3: es la imagen oficial de Nginx
La idea es exponer tan solo Nginx al exterior y hacer que, en función de la URL facilitada, Nginx redirija la petición al servicio interno deseado. Así:
http://cluster:port/apidebe redirigir la petición a la API (go-rest-api)http://cluster:port/hellodebe redirigir la petición al hello world (go-hello-world)
Imagen dockercampusmvp/go-rest-api
Esta imagen es una COPIA EXACTA de la imagen chentex/go-rest-api. Simplemente la hemos vuelto a publicar en el repositorio del curso para garantizar que está disponible en todo momento.
Para ejecutarla en local basta con:
docker run -p 8080:8080 dockercampusmvp/go-rest-api:latest
Luego puedes ir a las siguientes URL:
Observa que el contenedor escucha por su puerto 8080.
Realización del ejercicio
Este es un ejercicio complejo que te recomiendo que realices con calma. La idea es que crees tú todos los ficheros YAML necesarios y finalmente los despliegues en el clúster.
La solución final consta de:
- Tres deployments (uno para Nginx y uno para cada uno de los servicios internos)
- Tres servicios (uno para Nginx y uno para cada uno de los servicios internos). El servicio de Nginx lo expondremos al exterior vía NodePort (también puede ser LoadBalancer como prefieras).
- Un config map que contendrá el fichero de configuración de Nginx (
nginx.conf). Este fichero debe mapearse al directorio/etc/nginxdel contenedor de Nginx.
En el fichero nginx-start.zip tienes el material necesario para empezar el ejercicio. En concreto verás dos ficheros:
nginx.conf: es el fichero de configuración de Nginxdeployment-nginx.yaml: es el fichero de deployment de Nginx (debe modificarse). Te lo proporciono porque hay cierta configuración propia de Nginx a utilizar y no tienes por qué saber de este servidor de aplicaciones. De este modo, el ejercicio lo puedes centrar en Docker y Kubernetes que es lo que nos interesa.
El fichero de configuración de Nginx asume que los servicios se llaman de la siguiente manera:
apisvc: el servicio de la API (imagendockercampusmvp/go-rest-api)hellosvc: el servicio del hello world (imagendockercampusmvp/go-hello-world)
Asegúrate pues de que los ficheros YAML de los servicios usan estos nombres, sino no te funcionará. El nombre del servicio para Nginx es irrelevante.
Pasos a seguir para resolver el ejercicio
Par empezar descomprime el fichero nginx-start.zip en un directorio vacío. Deberás ver dos ficheros:
nginx.conf: configuración de Nginxnginx-deployment.yaml: fichero YAML del deployment de Nginx
Ahora sigue los siguientes pasos:
- Crea un fichero YAML para el deployment de
dockercampusmvp/go-hello-world - Crea un fichero YAML para el deployment de
dockercampusmvp/go-rest-api - Crea un fichero YAML para el servicio de
dockercampusmvp/go-hello-world. Recuerda que el servicio debe llamarsehellosvc. - Crea un fichero YAML para el servicio de
dockercampusmvp/go-rest-api. Recuerda que el servicio debe llamarseapisvcy ten presente que el contenedor escucha por el puerto 8080. - Crea un config map con el contenido del fichero
nginx.conf - Modifica el fichero
nginx-deployment.yamlpara agregar el volumen a partir del config map creado en el punto anterior. Piensa que Nginx espera el ficheronginx.confen el directorio/etc/nginx - Crea un fichero YAML para el servicio de Nginx. Recuerda que debe ser de tipo NodePort. Ten presente que el contenedor de Nginx escucha por el puerto 8080.
- Despliega todos los ficheros en el clúster
Consejos importantes:
- Usa
containerPortsen los deployments para asegurar que el contenedor dedockercampusmvp/go-hello-worldescucha por el puerto 80 y el dedockercampusmvp/go-rest-apipor el 8080. Es cierto que si elDockerfilede las respectivas imágenes tiene la sentenciaEXPOSEeso no es necesario, pero cuando uses imágenes que no has creado tú, más vale tomar este tipo de precauciones. - Este ejercicio es un ejercicio complejo. Tómatelo con calma y repasa todos los conceptos necesarios (incluidos los de módulos anteriores si es necesario).
Comprueba que:
- Yendo a la URL
http://<ip>:puerto/recibes un 404 de Nginx - Yendo a la URL
http://<ip>:puerto/api/testte responde la API - Yendo a la URL
http://<ip>:puerto/api/hola/<cualquier-nombre>te responde la API - Yendo a la URL
http://<ip>:puerto/hellote responde el hello world
Solución
En el fichero nginx-end.zip tienes todos los ficheros YAML finales por si te atascas con alguno.
En la solución se incluyen dos ficheros adicionales:
deploy.sh(odeploy.cmd) para el despliegue en entornos Linux o Windows. Crea el config map y despliega los ficheros YAMLclean.sh(oclean.cmd) para limpiar el clúster de Kubernetes.
Ingress
En el ejercicio anterior has desplegado una solución completa en Kubernetes utilizando un contenedor Nginx como reverse proxy para dar acceso (bajo una sola URL base) a dos servicios (aplicaciones).
Todo ha funcionado correctamente, pero hay un pequeño punto de fricción y tiene que ver con la filosofía de empoderamiento de los equipos que defiende Kubernetes.
Uno de los objetivos de Kubernetes es ayudar a que los equipos sean autosuficientes a la hora de desplegar y configurar su aplicación. Eso es, idealmente cada equipo debería ser capaz de desplegar y configurar su servicio o aplicación sin ayuda externa. Y esa configuración incluye, por supuesto, configurar el cómo se accede a su aplicación desde fuera.
Por norma general en Kubernetes existen dos grandes roles:
- El operador del clúster: es un rol administrativo, con altos permisos quien se encarga de administrar el clúster. La idea es que este rol realice tareas de configuración (más o menos iniciales), que se suelen realizar una única vez pero luego no debe ser alguien bloqueante para los equipos.
- El desarrollador: o equipo de desarrollo, es el rol de quien instala una aplicación en el clúster. La idea de Kubernetes es que, una vez dado un clúster configurado correctamente (tarea del operador), el desarrollador pueda desplegar su aplicación sin requerir en ningún momento al operador para nada.
En general, el operador hace tareas que “afectan a todo el clúster”, mientras que el desarrollador hace tareas que se circunscriben a su propia aplicación.
Revisemos el ejercicio anterior desde este punto de vista:
- El despliegue de Nginx es una tarea del operador, ya que este Nginx será usado por varias aplicaciones
- El despliegue de cada una de las aplicaciones que teníamos es tarea del desarrollador
- El configurar el Nginx adecuadamente en cada caso debería ser tarea del desarrollador (según la filosofía de Kubernetes), pero ahí está el punto de fricción.
Tenemos un operador que es el encargado de desplegar y administrar este Nginx. Así, lo más habitual es que sólo el operador tenga permisos para cambiar la configuración de este Nginx, ya que es un recurso global. Pero si sólo tiene permisos el operador, entonces los equipos de desarrollo tienen una dependencia con el operador para que este configure Nginx. Por lo tanto, los equipos de desarrollo ya no pueden desplegar por sí solos y sin depender de nadie más su aplicación. No están empoderados. Y Kubernetes persigue justamente lo contrario.
Una posible solución es dejar que los equipos de desarrollo modifiquen el fichero de configuración de Nginx. Al final está en un ConfigMap que cualquier equipo podría modificar. Pero ahí surgen fricciones también: esta configuración (en nuestro ejemplo este ConfigMap) es un recurso global y compartido:
- ¿Cómo garantizamos que ningún equipo rompa la configuración de otro equipo?
- ¿Dónde guardamos la definición de este ConfigMap? Con distintos equipos trabajando potencialmente en distintos repositorios o ramas, no está tan claro.
- ¿Quién soluciona conflictos si los hay?
Lo ideal sería tener un mecanismo que permitiese que cada equipo definiese las reglas de acceso a su aplicación (y sólo a su aplicación). Esas reglas de acceso formarían parte de la definición de su aplicación al igual que lo forman los deployments o los servicios, por poner dos ejemplos. Sólo el equipo mantendría esas reglas de acceso y las desplegaría acorde a sus necesidades.
Y una vez desplegadas Kubernetes se encargaría de que se cumpliesen. Si el equipo A define que la ruta a su aplicación es /web y el equipo B define que la ruta a la suya es /api, ambos equipos pueden desplegar por separado y sin conflictos sus aplicaciones. Y Kubernetes se encargará de que cuando se acceda al clúster con la URL /web, se llame al servicio del equipo A y cuando se use la ruta /api se llame al servicio del equipo B.
Los desarrolladores ahora están empoderados: pueden desplegar autónomamente su aplicación ya que las políticas de acceso externo forman parte de ella y no necesitan ni la actuación ni el permiso de nadie para desplegarlas. Además, como regalo adicional, esas rutas se pueden definir en un formato estándar, definido por Kubernetes, por lo que no hay necesidad de que un detalle de infraestructura (que estamos usando Nginx como proxy inverso) se filtre a los equipos.
¡Pues eso es lo que permite el uso de Ingress que vas a ver en las próximas lecciones! Lo que vas a ver es:
- Qué es un recurso ingress
- Qué es un controlador ingress
- Crear un recurso ingress
- Crear un controlador ingress y asociarlo a un determinado ingress
Proxy de nivel 7
Antes de entender qué son los recursos ingress y cómo crearlos, debes saber que un ingress es la abstracción en el mundo Kubernetes de un proxy de nivel 7. Así que, lo primero es entender bien qué es un proxy de nivel 7 y qué significa.
Usar ingress no es la única manera de tener un proxy de nivel 7 en Kubernetes. De hecho, en la lección anterior ya implementaste uno manualmente instalando Nginx y configurándolo. La ventaja de ingress es que es un mecanismo estándar para implementarlo.
Modelo OSI
El modelo OSI (Open System Interconnection) es un modelo de referencia para los protocolos de red, que permite catalogar cada protocolo existente dentro de un nivel (del 1 al 7) en función de sus características. Cuanto más arriba esté un protocolo en el nivel OSI, más abstraído está del “mundo físico”. Así, los protocolos de nivel 1, son protocolos que definen el medio físico por el que pasará la información (al detalle de señales eléctricas incluso). Por el contrario, los protocolos de nivel 7, son protocolos con una abstracción mucho más alta, pensados para construir aplicaciones.
Seguro que has oído hablar de TCP/IP, el protocolo sobre el cual está construido Internet. Bien, pues, TCP/IP no es un protocolo, sino dos en realidad. Uno es TCP y el otro IP, y están ubicados en capas OSI distintas. Nos solemos referir siempre a ellos como TCP/IP, como si fuese un único protocolo, aunque realmente significa “TCP sobre IP” y ambos protocolos son independientes. Existen otros protocolos de nivel 4 OSI que también pueden usarse (¡y se usan!) junto con IP, como por ejemplo UDP.
Así pues, en nuestro día a día, usamos multitud de protocolos de red, de distintos ámbitos, y todos ellos pertenecen a alguna capa OSI. Las capas OSI son las siguientes:
- Capa física. La más baja de las capas OSI. Se encarga de definir el medio físico. Los protocolos de nivel 1 OSI son pues protocolos a bajo nivel, que entran de lleno en el ámbito de las telecomunicaciones. Cuando hablamos de Firewire o de 10BASE-T hablamos de protocolos de nivel 1.
- Capa de enlace de datos. Esta capa se ocupa del direccionamiento físico, del acceso al medio, de la detección de errores, de la distribución ordenada de tramas y del control del flujo. Protocolos como IEE802.2 pertenecen a dicha capa.
- Capa de red. Esta capa se encarga de conectar hosts que pueden no tener conexión directa. Proporciona pues servicios de conectividad y enrutamiento: su misión es permitir que los datos lleguen del origen al destino aunque ambos no estén directamente conectados. El protocolo IP pertenece a este nivel. Un protocolo de este nivel puede garantizar la entrega de un mensaje, pero ello no es obligatorio.
- Capa de transporte. Esta capa se encarga de mantener el flujo de datos entre el emisor y el receptor y gestionar los errores incluso cuando estos no están directamente conectados. Conceptos como mandar un ACK o no mandarlo se definen a este nivel. Los protocolos TCP y UDP mencionados antes, trabajan a este nivel.
- Capa de sesión. Esta capa controla las conexiones entre hosts. Cerrar una conexión de forma “correcta” se define a este nivel. Hay que mencionar que el protocolo TCP (recuerda que es de nivel 4), define también algunos aspectos de capa de sesión (por ejemplo cómo abrir/cerrar una conexión está definido en TCP). Otros conceptos definidos en esta capa son cómo recuperar y reanudar una sesión que se había interrumpido.
- Capa de presentación. Esta capa controla la presentación o formato de los datos para que estos sean reconocidos entre distintos dispositivos conectados, que pueden tener diferentes formatos de representaciones de datos. En este nivel ya no nos centramos en cómo enviamos los datos, sino que nos centramos en los datos en sí mismos y en la manera de representarlos. Cómo serializar estructuras de datos o cómo convertir de EBCDIC a ASCII, son dos ejemplos de capa de presentación. Otra tarea que puede hacerse en esta capa (aunque también se puede hacer en otras) es encriptar y desencriptar los datos.
- Capa de aplicación. La capa más alta del modelo OSI. Los protocolos que caen en este nivel definen cómo interactúan dos hosts entre ellos: qué funcionalidades tiene cada host y cómo se accede a dichas funcionalidades desde el resto. El uso de estos protocolos permite la creación de aplicaciones (que ya caen fuera del modelo OSI). Esto te puede sonar muy abstracto, pero seguro que te suenan muchos protocolos que caen en este nivel: FTP, HTTP, LDAP, Telnet, SSH, SMTP, POP y XMPP son protocolos de nivel 7 OSI.
Proxies de nivel 4
Un proxy de nivel 4 es aquel que actúa en el nivel 4 del modelo OSI. Si hablamos de Internet, donde el nivel 4 suele ser TCP, eso significa que es un proxy que actúa a nivel de TCP. Por lo tanto un proxy de nivel 4 puede tomar decisiones en base a lo que se conoce en dicho nivel: direcciones IP y cabeceras TCP.
Por ejemplo, un balanceador de carga que enrute todas las peticiones a una IP concreta hacia un conjunto de máquinas es un proxy de nivel 4, ya que usa la dirección IP solo para funcionar.
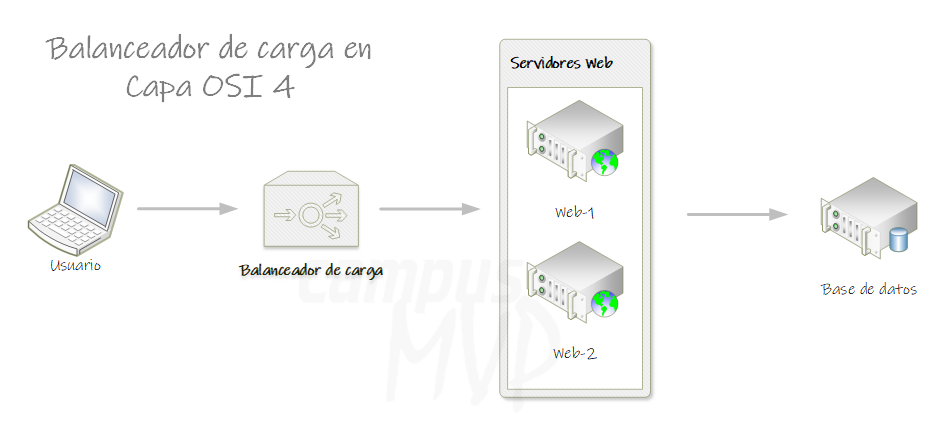
Nginx puede funcionar como un proxy de nivel 4.
Proxies de nivel 7
Como ya te debes imaginar, un proxy de nivel 7 es aquel que actúa a nivel 7 del modelo OSI. Es decir actúa en la capa de aplicación, lo que equivale a decir en nuestro caso a nivel de HTTP. Por lo tanto un proxy de nivel 7 puede inspeccionar los paquetes HTTP y tomar decisiones en base a dichos paquetes. Así, un balanceador de carga de nivel 7, puede enrutar no solo en base a una IP de destino sino, en base a cualquier elemento HTTP, como por ejemplo la ruta o una cabecera. Es decir, por ejemplo, puede enrutar peticiones a /api1 a un conjunto de servidores y enrutar las peticiones a /api2 a otro conjunto distinto de servidores. Y, del mismo modo, podría inspeccionar cabeceras HTTP para modificar su comportamiento.
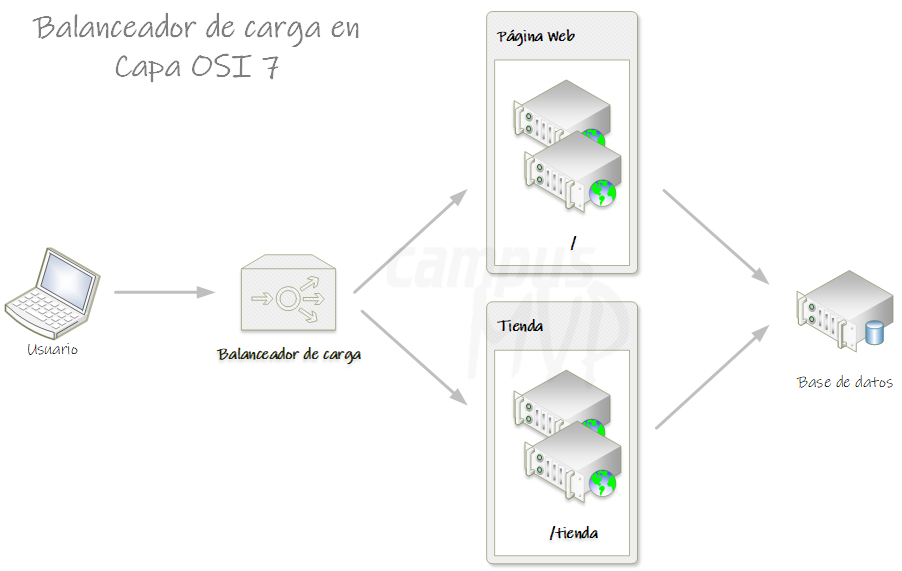
HAProxy es un proxy de nivel 7 y Nginx puede funcionar como proxy de nivel 7 también.
Si recuerdas al principio comenté que ingress era la abstracción de un proxy de nivel 7 en el mundo Kubernetes. Ahora ya debes tener un poco más claro lo que ingress permite: a grandes rasgos, exponer varios servicios del clúster al exterior, bajo una sola IP externa y diferenciándolos mediante su URL.
La diferencia principal entre exponer 3 servicios públicamente al exterior usando 3 servicios de tipo LoadBalancer o usando ingress, es que en el primer caso tendrás 3 IPs distintas (una por cada servicio) y en el segundo, una sola IP (y usarás distintas rutas para acceder a cada servicio).
Recursos Ingress
Cuando comenté la filosofía de empoderamiento de los equipos de Kubernetes comenté que lo ideal es que cada equipo pudiese definir las reglas de acceso a su aplicación. En Kubernetes esas reglas de acceso las definimos mediante el recurso ingress.
Así, un recurso ingress es básicamente, una colección de reglas que permiten que conexiones externas accedan a servicios del clúster. Es decir, en el ejercicio anterior teníamos un pod que ejecutaba un Nginx y exponíamos este pod al exterior mediante un servicio. La única función de este Nginx era ofrecernos acceso al resto de servicios del clúster (el hello world y la API).
Pues bien, ingress es un objeto de Kubernetes y, por lo tanto, tiene su propia definición YAML, que mantiene básicamente estas reglas.
A continuación se muestra la definición de un recurso ingress:
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: labels: app: demo-ingress name: demo-ingress annotations: ingress.kubernetes.io/ssl-redirect: "false" spec: rules: - http: paths: - path: /api pathType: ImplementationSpecific backend: service: name: apisvc port: number: 80 - path: /hello pathType: ImplementationSpecific backend: service: name: hellosvc port: number: 80
Nota sobre el valor de apiVersion: en Kubernetes anteriores a 1.14 (ya ha llovido bastante desde entonces) se debía usar extensions/v1beta1 como apiVersion, en lugar de networking.k8s.io/v1beta1. A partir de Kubernetes 1.14 era preferible usar networking.k8s.io/v1beta1, ya que ingress se eliminó de extensions/v1beta1 en Kubernetes 1.20. Por su parte, a partir de 1.19 debemos ya usar networking.k8s.io/v1 que es la versión final. Si miras recursos de internet es posible que te encuentres con versiones no actualizadas, tenlo presente.
Vamos a analizar este fichero YAML. Por un lado, tenemos las típicas apiVersion y kind (observa el valor Ingress) y, luego, la no menos típica metadata. En metadata tenemos:
labels: etiquetas asociadas a este recurso ingress.name: nombre del recurso.annotations: anotaciones del recurso. Recuerda que las anotaciones son pares (clave,valor) asociadas al recurso que permiten personalizar su comportamiento. Son un elemento clave en ingress ya que nos permiten configuraciones avanzadas.
Finalmente, como siempre, la especificación del recurso está en spec, donde definimos las reglas (rules) por cada protocolo.
Actualmente se soportan solamente reglas de http y aunque en su momento la idea era añadir nuevos protocolos, seguramente no sea así, ya que la más nueva “Gateway API” se ha diseñado para soportar aquellos casos de uso en los que ingress no es suficiente.
La colección paths es la que define cada regla específica:
path: path externo.pathType: su valor por defecto esImplementationSpecificy hablaremos más adelante de qué significa exactamente.backend: a qué servicio interno (serviceNamees el nombre del servicio en Kubernetes yservicePortel puerto) debe redirigirse la petición.
Como siempre puedes usar kubectl apply sobre este fichero YAML para crear el recurso ingress. Una vez creado puedes verlo con kubectl get ing:
NAME CLASS HOSTS ADDRESS PORTS AGE demo-ingress nginx * 80 10s
Si usas kubectl describe ing <nombre-recurso-ingress> sobre el recurso ingress verás la información de las rutas que este define:
Name: demo-ingress
Labels: app=demo-ingress
Namespace: default
Address:
Ingress Class: nginx
Default backend: <default>
Rules:
Host Path Backends
---- ---- --------
*
/api apisvc:80 (<error: endpoints "apisvc" not found>)
/hello hellosvc:80 (<error: endpoints "hellosvc" not found>)
Annotations: ingress.kubernetes.io/ssl-redirect: false
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 50s nginx-ingress-controller Scheduled for sync
Controlador ingress
Ahora bien, un recurso ingress por sí solo no hace nada. Es necesario que haya “alguien” que se encargue de hacer cumplir esas reglas definidas. Es decir, necesitamos alguien que escuche peticiones externas y las redirija según indica el recurso ingress. Necesitamos un controlador ingress.
Es decir, tener un recurso ingress no implica que automáticamente las URLs definidas se expongan al exterior. Debes entender que ingress es poco más que una configuración de rutas. La clave está en el controlador ingress, que es el responsable de inspeccionar el recurso ingress y de crear los endpoints necesarios según las rutas definidas.
Kubernetes, por sí mismo, no hace nada con los recursos ingress. Debe haber una pieza instalada en el clúster que se encargue de leer esos recursos y actuar en consecuencia. A esta pieza la llamamos “controlador ingress”. Instalar el controlador ingress es una tarea administrativa que debe hacerse una sola vez (por el operador del clúster). Hay muchos controladores ingress e incluso es posible tener instalado más de uno en el clúster y que cada aplicación elija el que quiere usar. A “nivel de Kubernetes”, un controlador ingress es poco más que un deployment que ejecuta un pod con un proxy inverso (por ejemplo, Nginx) y un servicio que expone dicho deployment al exterior. Eso sí, a diferencia del Nginx que usaste en el ejercicio anterior, el Nginx usado en el controlador de ingress tiene código específico que lee los recursos ingress creados y se “autoconfigura”. ¡En breve lo vas a ver!
La propiedad pathType
La introdujimos antes brevemente, pero vamos a verla ahora con mayor detalle. Recuerda que su valor por defecto es ImplementationSpecific.
El valor de esa propiedad define la manera en que las URLs se mapean contra las rutas. Tiene tres valores posibles:
Prefix: si la URL empieza por el path indicado. Por ejemplo, si el valor del path es/exampley la url es/example/1.Exact: la URL debe ser exactamente el valor indicado en path. Ojo con esa opción que es “case sensitive” (las mayúsculas y minúsculas deben coincidir).ImplementationSpecific: depende del controlador ingress decidir cómo se mapea este path en la URL (es lo que ocurre en Kubernetes 1.17 y anteriores). Puede ser que se comporte comoPrefix, comoExacto tenga otro comportamiento distinto.
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: my-ingress spec: ingressClassName: ambassador rules: - http: paths: - path: /foo pathType: Prefix backend: service: name: FooService port: number: 80 - path: /bar/ pathType: Exact backend: service: name: BarService port: number: 80
En la documentación de Ingress hay varios ejemplos de pathType y cómo afecta a la resolución de reglas en base a la URL.
Usar Ingress en Minikube
Instalar el controlador ingress
Cuando vas a usar ingress lo primero es la operación de instalar el controlador ingress. Esta es una operación administrativa que se realiza una sola vez y es responsabilidad del operador del clúster.
El cómo se instala el controlador de ingress depende, por un lado del propio controlador que se desee usar y, por otro, del clúster que se tenga. Algunos clústeres pueden venir con un controlador propio ya instalado, otros sin él, etc…
Hay muchos controladores de ingress disponibles, pero el que se considera el canónico es el que llamamos ingress-nginx. Este es un controlador ingress basado en Nginx, pero desarrollado por la propia comunidad de Kubernetes. Que sea el canónico no significa que tenga que ser el mejor ni el más avanzado, pero seguramente es el que vas a ver más. Pero hay muchos más:
- NGINX ingress controller: no lo confundas con el anterior, este es otro controlador también basado en Nginx, pero en este caso desarrollado por la misma empresa que desarrolla Nginx.
- Traefik ingress controller: basado en traefik.
- HAProxy ingress controller: basado en HAProxy
Y varios más que puedes encontrar en la propia documentación de Kubernetes.
Cuando elijas el que quieras usar, deberás mirar cómo instalarlo. En este curso no te puedo dar soporte a cómo instalar cada controlador ingress en cada posible clúster, pero sí que aspiro a darte los conocimientos necesarios para que luego puedas hacerlo por tu cuenta. En general, instalar un controlador ingress significa instalar los objetos de Kubernetes (muchas veces un deployment, un servicio y un ConfigMap, pero pueden haber otros) y configurarlos. Al final, recuerda, un controlador ingress es “poco más” que uno o más pods corriendo algún proxy inverso que está modificado para autoconfigurarse en base a los recursos ingress y exponerlo al exterior.
Minikube tiene soporte para ingress directo y, además, no debes instalar el controlador ingress, el propio Minikube lo hará por ti mediante el comando:
minikube addons enable ingress
La salida del comando será parecida a la siguiente:

Este comando instala automáticamente el controlador de ingress ingress-nginx
Una vez el comando ha finalizado ya podemos usar recursos ingress. El controlador de ingress está instalado. El controlador ingress se instala en el espacio de nombres ingress-nginx:
kubectl get ns
Lo que realmente necesitas saber es por qué servicio se expone el controlador al exterior. Para ello puedes ejecutar el comando:
kubectl get svc -n ingress-nginx
Cuya salida será parecida a la siguiente imagen:

El servicio que te interesa es ingress-nginx-controller ya que es quien se expone al exterior. Puedes ver que, en este caso es un servicio de tipo NodePort (dependiendo de tu configuración, tu clúster y el controlador de ingress que instales el servicio puede ser de tipo LoadBalancer).
Usando recursos ingress en Minikube
Bien, ahora descomprime el fichero minikube-demo.zip en una carpeta vacía. Te aparecerán tres ficheros YAML (son los mismos en realidad que la demo de GCE): el recurso ingress, el servicio y el deployment. Usa kubectl apply para instalar todos los ficheros en el clúster.
Ahora si lanzas el comando kubectl get ing deberías ver el recurso ingress creado:
NAME CLASS HOSTS ADDRESS PORTS AGE nginx-minikube nginx * 80 8s
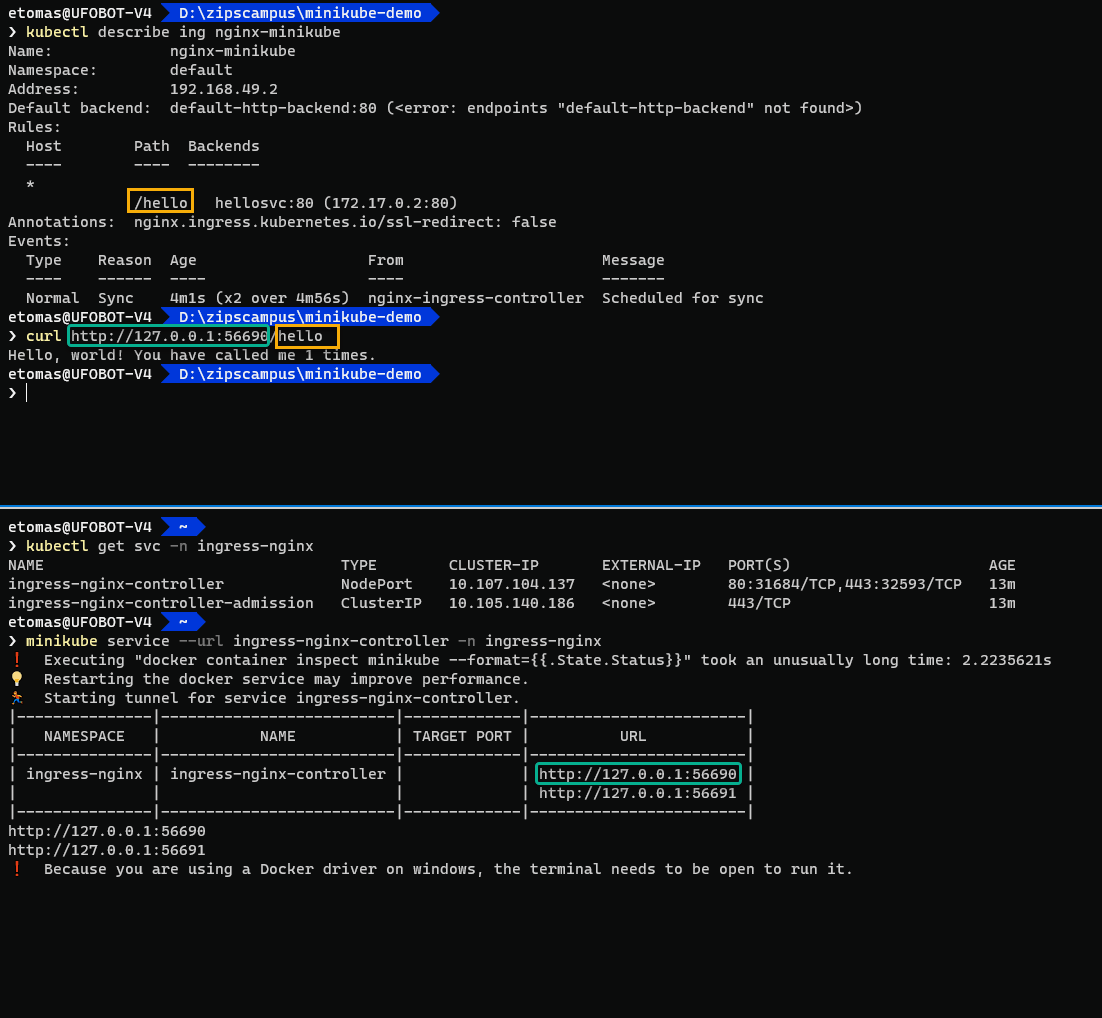
Acceder al servicio con Minikube (Linux)
Los ficheros del ejemplo han instalado un deployment, un servicio y el recurso ingress.
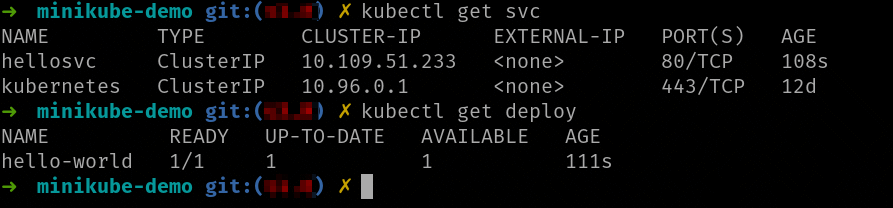
Puedes ver como el servicio es de tipo ClusterIP, es decir accesible solo desde dentro del clúster, pero esa es la idea, ya que accederemos a él usando ingress.
Recuerda que el controlador ingress se exponía como un servicio NodePort, así que debemos usar el comando minikube ip para obtener la IP del nodo y acceder a esta IP usando el nodeport del servicio del controlador ingress:
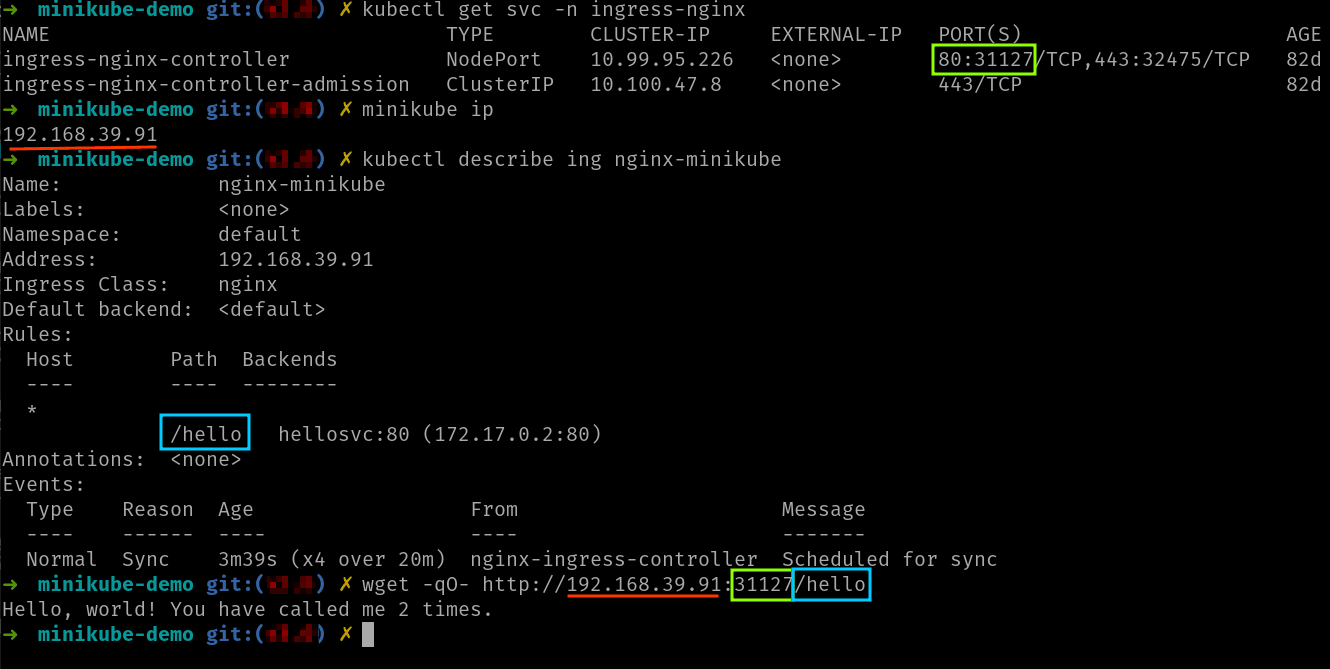
Otra opción es usar el comando minikube service que te dará directamente la IP y puerto del servicio:
Acceder al servicio con Minikube en Windows con el driver de Docker
Si tienes Minikube ejecutándose con el driver de Docker, debes crear un túnel para poder acceder al servicio del controlador ingress desde tu máquina. Para ello, puedes usar el comando:
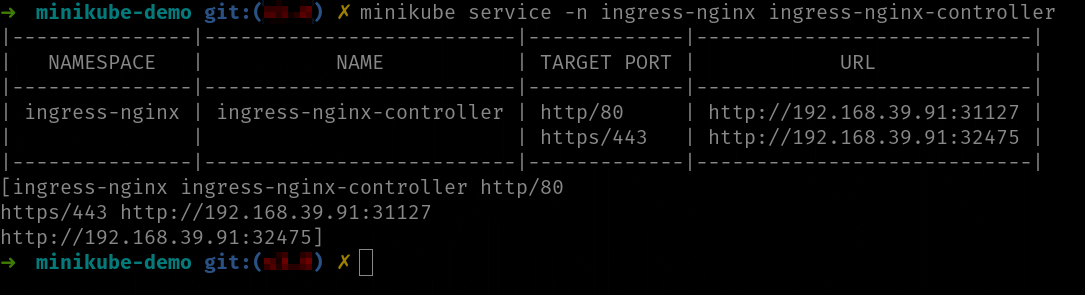
minikube service --url ingress-nginx-controller -n ingress-nginx
El comando minikube service te permite obtener el URL del servicio indicado. En el caso del driver de Docker, además, creará un túnel TCP que permitirá acceder a la IP que te devuelva. Este comando bloquea el terminal y debes tenerlo en ejecución mientas necesites acceder al servicio indicado. En nuestro caso queremos acceso al servicio que ejecuta el controlador de ingress.
Una vez tengas el URL del servicio del controlador de ingress (que será la IP de localhost y un puerto asignado al azar por el túnel TCP), lanza una petición al endpoint (/hello): el servicio te debería responder:
Acceder al servicio con Minikube en Windows con el driver de HyperV
La forma más sencilla para obtener acceso es usar, al igual que el caso anterior, el comando minikube service para obtener una IP y un puerto. A diferencia del caso anterior, es posible que el comando no te cree un túnel TCP:

¿Sencillo, verdad? Dependiendo de la configuración de red de la MV y de tu sistema de virtualización es posible que tengas acceso directo al nodo de Minikube o que no. Si tienes acceso directo al nodo, entonces puedes usar la misma técnica que en Linux, usando el comando minikube ip:

Observa que ejecuto el comando desde un terminal administrativo. Eso es porque, en ese ejemplo, estoy usando HyperV como driver de VM, que requiere permisos administrativos. Observa también el uso del modificador --profile, para seleccionar el perfil de Minikube que usa HyperV (eso es porque tengo dos Minikubes instalados: uno con Docker, el otro con HyperV, siendo el primero el “por defecto”).
Una vez tienes la IP del nodo, simplemente debes obtener el puerto a través del que se expone el servicio ingress-nginx-controller (usando el comando kubectl get svc). Ya podrás acceder a tu servicio usando la IP del nodo, el puerto del servicio y la ruta del ingress:

Observa como la combinación de IP y puerto obtenida mediante este segundo método, ha sido la misma que nos daba minikube service. En general, si Minikube detecta que tienes acceso al nodo, entonces el comando minikube service te devolverá la URL y terminará. En caso contrario te abrirá el túnel TCP como cuando usamos el driver de Docker.
Anotaciones en recursos Ingress
Cuando antes hemos descrito el recurso ingress, hemos comentado la sección annotations indicando que eran entradas (clave, valor) que permitían modificar su comportamiento. Por supuesto, el recurso ingress no posee ningún comportamiento: es el controlador ingress asociado el que lo tiene. Como consecuencia, las anotaciones:
- Modifican el comportamiento del controlador ingress asociado al recurso
- Dependen de cada controlador ingress
Por lo tanto, por ejemplo, si usas el controlador ingress que viene instalado de serie en los clústeres de GKE, emplearás unas anotaciones distintas a si usas el controlador ingress Nginx. Debes consultar la documentación del controlador ingress asociado para determinar qué anotaciones aplicar al recurso ingress. Aunque, hay que decir que, el propio Kubernetes define un conjunto de anotaciones estándar pensadas para ser respetadas por todos los controladores. Pero, siempre hay que consultar la documentación del controlador ingress que se use, porque no todas las anotaciones estándares se respetan en todos los controladores (eso va evolucionando con el tiempo).
Por ejemplo, la anotación ingress.kubernetes.io/ssl-redirect indica si debe redirigir las peticiones HTTP a HTTPS (si vale “true”) en el caso de que TLS esté habilitado.
Aquí puedes consultar una lista de todas las anotaciones que soporta el controlador Nginx.
Si miras la lista, verás que la anotación para la redirección de SSL tiene el nombre de nginx.ingress.kubernetes.io/ssl-redirect, en lugar de la ingress.kubernetes.io/ssl-redirect que usamos nosotros. La diferencia es que la primera (con el prefijo de nginx) la entiende solo el controlador de Nginx, mientras que la segunda es una anotación estándar definida por Kubernetes y está soportada por más de un controlador ingress.
Todas las anotaciones que empiecen por ingress. son las definidas por el estándar de Kubernetes. Luego, cada controlador ingress define las suyas propias, generalmente con un prefijo. Así, las anotaciones que empiezan por nginx.ingress. son propias del controlador de Nginx. Esto permite tener un ingress preparado para varios controladores distintos (usando los prefijos para configurar de forma distinta cada controlador).
Algunas anotaciones importantes
A continuación viene un listado, no exhaustivo, con algunas de las anotaciones más habituales que te puedes encontrar.
ingress.kubernetes.io/ssl-redirect: ya comentada, si valetruelas peticiones HTTP son redirigidas a HTTPS (lo que implica que se debe tener un certificado instalado en el clúster). Para desarrollo, lo más sencillo es que la pongas afalse. En producción lo recomendable sería que estuviera a true.ingress.kubernetes.io/rewrite-target: esta es otra anotación muy importante. Reescribe el base path de las peticiones al valor indicado. Imagina que tienes una API que enruta peticiones usando/api/xyz. Eso significa que la API devolverá un 404 por cualquier otra petición que no tenga esa ruta. Si usas un recurso ingress para acceder a tu API, esta estará accesible mediante/ruta-ingress/api/xyz. Pero, cuando a tu API le llegue esta URL, devolverá un 404 ya que no la reconoce (la API no espera rutas que empiecen por/ruta-ingress). En este caso debes indicarle a ingress que cuando llame a tu API use/como base path. Para ello usarás la anotacióningress.kubernetes.io/rewrite-target: "/". Con eso le indicas al controlador ingress que cuando llame a los servicios internos lo haga pasándoles/como base path. De ese modo, el usuario usa la url/ruta-ingress/api/xyz, pero tu API (el servicio interno) recibe/api/xyz(la ruta de ingress se sustituye por el valor derewrite-target) y, de ese modo, todo funciona correctamente.
Las anotaciones al final aparecen porque la definición de ingress es muy básica: hace poco más que mapear URLs a servicios. Pero cualquiera que haya trabajado configurando un proxy inverso sabe que esa es sólo una parte de la configuración: como tratar cabeceras HTTP, configurar CORS o HSTS, aspectos más avanzados como “sticky sessions” y muchas cosas más suele ser necesario configurarlas. Ingress no da soporte de forma directa para ninguno de esos casos y, además, cada controlador ingress tiene sus propias características únicas y limitaciones. Por eso terminamos configurando usando las anotaciones, que al ser pares (clave, valor), cada controlador puede definir las suyas. Eso por supuesto viene con un precio: si nunca cambias de controlador ingress, seguramente te tocará retocar los recursos ingress para adaptar las anotaciones.
Afinidad de sesión con ingress
Hace algunas lecciones viste la afinidad de sesiones en servicios, donde en base a la IP del pod llamante se le podía garantizar que todas las llamadas al servicio serían respondidas por el mismo pod.
Esa afinidad de los servicios no funciona cuando el llamante es alguien externo y usamos ingress: Cuando usamos ingress todas las llamadas desde el exterior pasan por el mismo servicio (el del controlador ingress) y son respondidas por el mismo conjunto de pods (los pods del controlador ingress). Cuando el servicio interno recibe la llamada, la IP que ve es la del pod del controlador ingress, no la IP del cliente externo. Por lo que, aunque implementen afinidad de sesiones, esta afinidad sería a nivel del pod del controlador ingress. Pero eso no nos sirve para nada, ya que lo que queremos es afinidad basada en el cliente externo.
Eso significa que la afinidad de sesiones debe ofrecerla el controlador ingress. Es una característica no definida en ingress y que habitualmente se configura a través de anotaciones. Por supuesto, cada controlador ingress la establecerá y soportará (si lo hace) a su manera.
En el caso del controlador ingress-nginx el soporte es mediante cookies (recuerda que ingress es conceptualmente un proxy de nivel 7, así que usar un mecanismo propio de HTTP como son las cookies es aceptable) y se configura mediante las anotaciones:
nginx.ingress.kubernetes.io/affinity: "cookie" nginx.ingress.kubernetes.io/session-cookie-name: "stickounet" nginx.ingress.kubernetes.io/session-cookie-expires: "172800" nginx.ingress.kubernetes.io/session-cookie-max-age: "172800"
Estas anotaciones establecen que este recurso ingress usará afinidad de sesión usando cookies y las características de la cookie (su nombre y tiempo de expiración). Para más información puedes consultar la documentación oficial.
Te voy a contar un tema más de funcionamiento interno de (me atrevería a decir casi todos) los controladores ingress. No necesitas saberlo para usarlos, pero no está de más ver lo que realmente hacen. Dada la definición de un ingress, uno podría pensar que el controlador ingress recibe la petición externa y luego llama al servicio interno correspondiente. Eso, se podría hacer y funcionaría, pero limita mucho los servicios “extra” que el controlador ingress puede ofrecer. Por ejemplo, es imposible implementar sticky sessions usando ese mecanismo. Así que, los controladores ingress optan por otro mecanismo más complejo (para ellos, que no para nosotros), pero mucho más potente. Los controladores ingress, cuando reciben la petición externa, invocan directamente a uno de los pods que están expuestos por el servicio. La API de Kubernetes da mecanismos para saber las IPs de los pods que en todo momento están bajo el paraguas de un servicio, y eso es lo que usan los controladores ingress. Al “saltarse” el servicio e ir directamente a uno de los pods subyacentes, pueden ofrecer características más avanzadas como las mismas sticky sessions. Incluso hay controladores ingress que (dada la correcta infraestructura montada en el clúster) son capaces de seleccionar el pod que esté “más libre” de todos los posibles pods que pueden atender la petición.
Desplegar varios recursos Ingress
Hasta ahora hemos visto el escenario en el que tenemos un solo controlador de ingress.
Y en nuestro caso también hemos desplegado un solo recurso ingress en el clúster. En muchos casos este escenario es más que suficiente: obtienes un punto de entrada a tu clúster y mediante el controlador ingress das acceso a los servicios internos del mismo.
Pero la realidad es que se puede desplegar más de un controlador ingress y también se puede desplegar más de un recurso ingress. La primera pregunta que surge es… Si podemos tener varios controladores y varios recursos ingress ¿Cómo se sabe qué controlador ingress debe procesar qué recurso ingress?
La realidad es que tener varios recursos ingress es muy común (lo habitual es uno por aplicación), pero tener varios controladores ingress es mucho más raro.
Asociar controladores a recursos: ingressClassName
Cuando instalas un controlador ingress este debe saber cuáles de todos los recursos ingress definidos en el clúster son para él. Para ello hay que indicar en el recurso ingress, de todos los posibles controladores ingress instalados, cuál debe tratar este recurso. El cómo realizar esta tarea, depende de la versión de Kubernetes que uses, pero la forma más reciente es usar spec.ingressClassName:
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: hello spec: ingressClassName: nginx
Este recurso ingress especifica que su controlador de ingress asociado es el controlador de ingress para Nginx.
Acuérdate de definir siempre el valor de spec.ingressClassName, incluso aunque tengas un solo controlador ingress instalado. Algunos controladores ingress rehusarán tratar recursos ingress que no tengan este campo incluso cuando sólo haya un controlador ingress instalado.
Por lo general, cuando hablamos de instalar más de un controlador ingress nos referimos a que sean de tipos distintos. Por ejemplo, en un clúster GKE (que ya lleva su propio controlador ingress) agregarle (manualmente) el controlador ingress de Nginx. En este caso, el uso de kubernetes.io/ingress.class nos permite especificar qué recursos asociamos a cada controlador. Es posible instalar varias instancias de un mismo controlador y sigue siendo posible decidir qué recursos ingress usa cada instancia. Sin embargo, eso complica la configuración (que además es propia de cada tipo de controlador) y es un escenario especialmente avanzado que queda fuera del alcance de este curso. Por ejemplo, en el caso del controlador ingress de Nginx tienes más información aquí.
La antigua anotación ingress.class
El campo spec.ingressClassName es una adición relativamente reciente (se añadió en la versión 1.18) y para que funcione es necesario, no solo estar en dicha versión de Kubernetes o superior, sino que tu controlador ingress esté actualizado. Si por algún motivo debes trabajar con versiones más antiguas, entonces este campo no estará disponible.
Antes de Kubernetes 1.18, se usaba la anotación kubernetes.io/ingress.class para indicar qué controlador ingress estaba asociado a cada recurso ingress. Aunque ampliamente extendida, la verdad es que esta anotación era un estándar de facto más que real: nunca estuvo propuesta “oficialmente” por la gente de Kubernetes. Es posible que en estos escenarios antiguos incluso el apiVersion del recurso sea más viejo:
apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: hello annotations: kubernetes.io/ingress.class: nginx
Ten presente que hay una correspondencia (que depende de cada controlador) entre la apiVersion de los recursos ingress y la versión del controlador ingress. Versiones del controlador muy nuevas no reconocerán apiVersions antiguas (con independencia de que Kubernetes las soporte).
Usando esta anotación, los controladores ingress se asociarán a los recursos ingress en función del valor que tengan en esa clave. Al ser un estándar de facto no está definido el comportamiento que debe tener el controlador ingress para aquellos recursos que no tengan definida dicha anotación. Así, dependiendo de tu controlador ingress, es posible que este se asocie:
- Sólo con los recursos ingress que tengan definida la anotación
kubernetes.io/ingress.classal valor esperado (por ejemplo, el controlador ingress basado en Nginx espera “nginx”. Otros controladores esperarán otros valores). - Sólo con los recursos ingress que tengan definida la anotación
kubernetes.io/ingress.classal valor esperado, o que no tengan dicha anotación definida, o que la tengan definida con el valor de cadena vacía. ¡Ojo! Que este segundo punto no es siempre cierto, depende del controlador ingress.
Lo oficial, hoy en día, es usar spec.ingressClassName. Usa solo la anotación si estás en escenarios más antiguos y si es el caso ¡define la anotación siempre y evita posibles ambigüedades!
Más de un recurso ingress asociado al mismo controlador
Un recurso ingress puede contener varias reglas (por ejemplo, redirigir /web al servicio de la web y /api al servicio de la API), pero, si esas reglas pertenecen a aplicaciones distintas que son desplegadas y manejadas por distintos equipos, es mala práctica ponerlas en el mismo recurso ingress.
Si lo haces, volvemos a depender de un recurso centralizado (en este caso el recurso ingress) y recuerda siempre que pretendemos que cada equipo pueda desplegar su propia aplicación de forma totalmente autónoma. Por lo tanto, es muy habitual tener varios recursos ingress desplegados. Luego el controlador ingress mezcla todos los recursos ingress de forma automática.
Vamos a realizar un pequeño ejercicio y vamos a desplegar más de un recurso ingress. Para ello usa el fichero minikube-dos-ingress.zip. Esta carpeta replica el ejercicio de NGINX que hiciste manualmente pero usando ingress. Descomprímelo en una carpeta y despliega todos los ficheros en el clúster. Una vez desplegados verás que tienes dos recursos ingress (los puedes ver con el comando kubectl get ing):
NAME CLASS HOSTS ADDRESS PORTS AGE api nginx * 80 3s hello nginx * 80 3s
Ambos recursos ingress tienen la misma spec.ingressClassName y por lo tanto serán atendidos por el mismo controlador (además sólo tenemos uno) pero la gracia es que el controlador ingress ha mezclado los recursos:
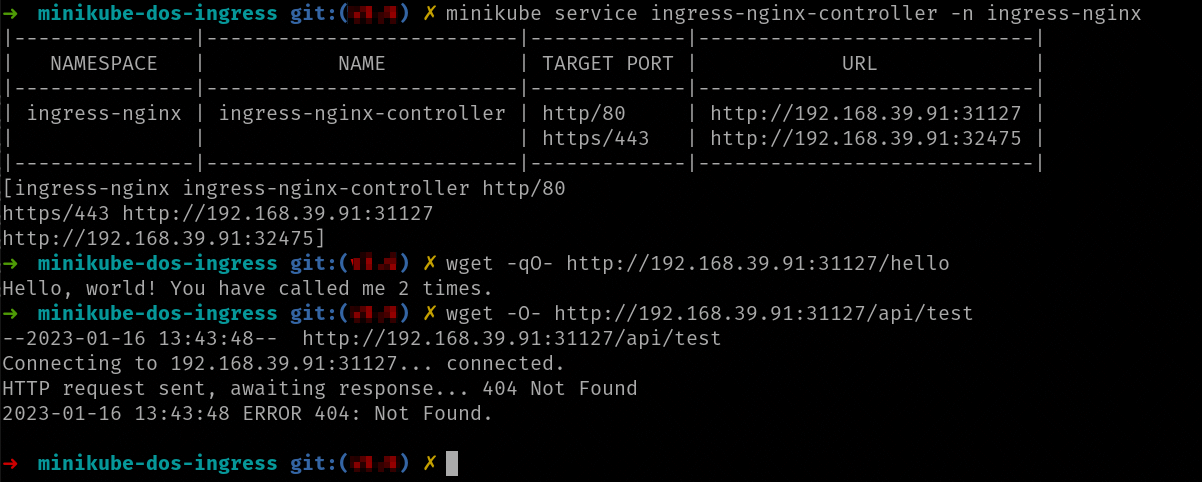
Como ves en la imagen parece que hay algún error: la llamada a /hello sí que funciona, pero la llamada a /api nos da un 404. Cuando recibas un 404 de una URL que pasa por ingress lo primero es discriminar la causa:
- La URL no es capturada por ningún recurso ingress
- La URL es capturada por un recurso ingress y quien nos devuelve 404 es la llamada al servicio
Esos dos 404 pueden tener formatos distintos ya que los generan elementos distintos:
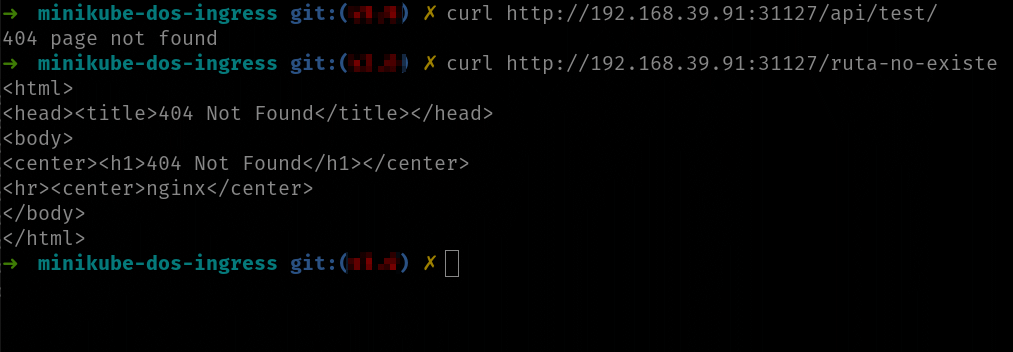
Si observas la imagen puedes ver la diferencia entre los dos 404. El primero está generado por la API y el segundo por el propio controlador ingress.
Pero… ¡espera! ¿Qué está ocurriendo ahí? Si recuerdas del ejercicio que hiciste cuando montaste NGINX a mano, la URL /test es una URL válida de la API:

Entonces… ¿por qué recibimos un 404 cuando llamamos a /api/test, si se supone que /api nos redirige las peticiones al servicio que ejecuta la API? Bueno, esa es una de las múltiples cosas que pueden ocurrir cuando se usa ingress (o un reverse proxy en general). Si no indicamos nada, ingress propaga la ruta entera al servicio. Es decir, el servicio de la API está recibiendo /api/test como ruta en lugar de /test y de ahí el 404.
Esa es una de las características que nos van a requerir una anotación para solucionarla. En nuestro caso (porque recuerda, eso depende de cada controlador ingress) la anotación es nginx.ingress.kubernetes.io/rewrite-target. Esa anotación lo que permite es configurar qué parte de la ruta que llega al controlador termina recibiendo el servicio. En nuestro caso el ingress arreglado nos quedaría así:
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: api annotations: nginx.ingress.kubernetes.io/ssl-redirect: "false" nginx.ingress.kubernetes.io/rewrite-target: /$2 spec: ingressClassName: nginx rules: - http: paths: - path: /api(/|$)(.*) pathType: ImplementationSpecific backend: service: name: apisvc port: number: 80
La anotación usa expresiones regulares que se evalúan sobre path. En este caso lo que se está haciendo es que dada una URL /api/xyz el servicio de la API reciba /xyz. En la documentación del controlador de ingress hay más ejemplos de esta anotación.
En el ejercicio que hiciste de desplegar NGINX manualmente también te podrías haber encontrado con ese problema. Lo que ocurre es que el fichero nginx.conf que preparé ya realiza esa transformación.
Razones para tener más de un controlador ingress
Tener más de un recurso ingress es muy habitual (de hecho, como comenté antes, lo normal es que haya, mínimo, uno por aplicación). Pero, tener dos o más controladores ingress no es tan habitual. ¿Qué posibles razones podría haber para ello?
Cada controlador ingress al final termina siendo expuesto al exterior mediante un servicio (LoadBalancer o NodePort) y, por lo tanto, obtiene una IP o puerto específico. Ahora imagina que tienes dos entornos en un clúster: desarrollo y testing. Para acceder a la web de desarrollo quieres usar la URL dev.myproject.com/web y para testing la URL test.myproject.com/web. Con lo visto hasta ahora este podría ser un motivo para tener dos controladores ingress y el DNS dev.myproject.com apuntando a un controlador y el DNS test.myproject.com al otro. Pero en la lección siguiente verás que eso NO es necesario.
Realmente hay pocas razones para tener más de un controlador ingress a no ser que quieras que sean independientes por motivos como:
- Controlar la carga de forma independiente: si las peticiones a desarrollo son mucho más numerosas que las peticiones a testing puedes tener dos controladores ingress escalados de forma distinta. Quizá prefieras eso que tener un controlador escalado para poder asumir todas las peticiones.
- Algún entorno requiere de algo muy específico: hay ciertas configuraciones del controlador que afectan a todo el controlador y a lo mejor alguna aplicación requiere alguna de esas configuraciones, pero no quieres que esa configuración global afecte al resto de aplicaciones. Puedes optar entonces por desplegar un controlador sólo para esa aplicación.
Además de las anotaciones en recursos ingress (que afectan al recurso ingress en concreto), se pueden establecer configuraciones avanzadas “a nivel global” del controlador ingress. Esas configuraciones se realizan creando o editando ConfigMaps específicos o incluso, en casos más avanzados, modificando el propio YAML del deployment (generalmente es un deployment) que ejecuta el controlador para añadir parámetros de línea de comandos al lanzar el proceso. Esas configuraciones dependen de cada controlador y quedan fuera del alcance de este curso.
Hosts virtuales
Los recursos ingress que hemos creado hasta ahora han estado vinculados a cualquier DNS que redirigiera a la IP del controlador ingress. Pero no van a ser esos los recursos ingress habituales que te vas a encontrar. Lo normal es que un recurso ingress esté vinculado a uno o más hosts virtuales, eso es DNS y que sólo se tengan en cuenta si se invoca al controlador ingress usando esos DNS.
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: hello-ingress spec: rules: - host: dev.campusmvp.es http: paths: - pathType: Prefix path: "/api" backend: service: name: hellosvc port: name: http
Observa como este ingress es ligeramente distinto a todos los que has visto hasta ahora. En spec.rules aparece la entrada host con el nombre del host virtual. Puedes tener reglas distintas que afecten a distintos DNS.
También hay otra ligera diferencia, y es que en backend.service.port se usa el nombre del puerto en lugar del número. Eso sólo es posible si el servicio ha dado nombre al puerto
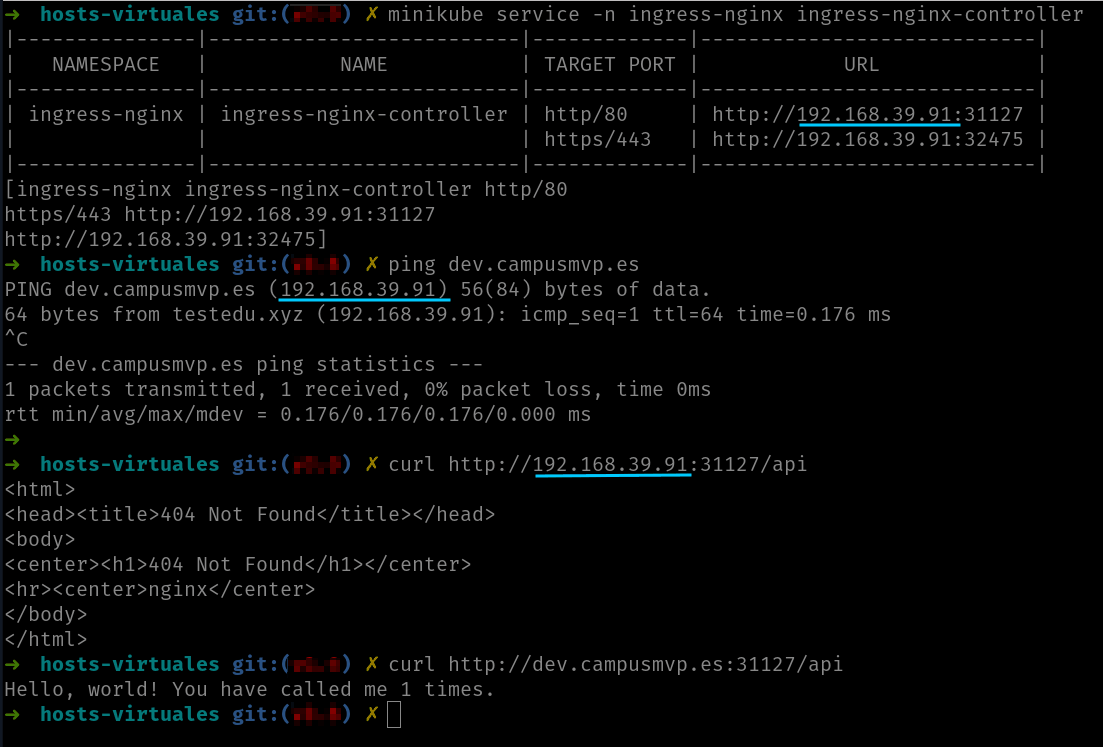
En la captura superior puedes ver como si accedo al controlador ingress usando directamente la IP, ahora recibo un 404 de NGINX. Eso es porque ahora el recurso ingress debe ser accedido usando el DNS dev.campusmvp.es. Puedes ver como este DNS resuelve a la IP del controlador ingress (tal y como muestra el comando ping) y que al acceder usando el DNS sí que funciona correctamente.
Para hacer esta prueba hemos tenido que editar el fichero hosts (/etc/hosts en Linux o C:\Windows\System32\Drivers\etc\hosts en Windows) y dar de alta la entrada del DNS dev.campusmvp.es a la IP del controlador ingress.
Esta aproximación es la que permite mediante un solo controlador ingress dar soporte a ingress que pueden ser de distintos entornos: simplemente apuntamos los DNS de los distintos entornos (por ejemplo, dev.myapp.com y test.myapp.com) a la misma IP (la del controlador ingress) y usamos distintos recursos ingress vinculados a los distintos entornos.
En general, es muy raro tener un recurso ingress que no use hosts virtuales. Mi recomendación es que los uses siempre.
Si usas hosts virtuales en tu ingress no hay manera de conseguir que el recurso ingress resuelva por IP.
Ingress y TLS
Hasta ahora no hemos hablado de SSL/TLS (HTTPS, vamos), pero ingress tiene soporte para ello, ya que, en caso contrario, de poco serviría para producción. Un escenario muy habitual es tener toda la comunicación interna entre contenedores usando HTTP y usar solo HTTPS en el ingress. De este modo se simplifica mucho la gestión de certificados. Este escenario es seguro, en el sentido que:
- Toda comunicación que entra/sale del clúster (a través de ingress) está protegida por SSL/TLS
- La comunicación interna (entre contenedores) del clúster está sin proteger, pero esta no es accesible desde el exterior
Por supuesto, si directamente expusieras otro servicio (usando LoadBalancer o NodePort) deberías securizarlo por tus propios medios.
Vamos a ver cómo configurar ingress para que use HTTPS, pero antes…
Funcionamiento de SSL/TLS
Para completitud déjame que te introduzca un poco, a grandes rasgos, cómo funciona SSL/TLS. Si ya conoces los fundamentos del protocolo, siéntete libre de saltarte esta sección y ¡nos encontramos en la siguiente! Si no, ningún problema, ahora te cuento lo básico que debes saber. Por cierto, que, para abreviar, usaré solo TLS, pero todo lo que voy a contar ahora es aplicable a SSL y a TLS.
SSL es un protocolo desfasado y ya obsoleto, hoy en día debe usarse TLS (cuya versión más reciente es la 3). Esto es una configuración del servidor, al final para el usuario todo se reduce a usar HTTPS. Entre bambalinas, cliente y servidor se pondrán de acuerdo en si usar SSL o TLS y en qué versión.
TLS es un protocolo para securizar las comunicaciones encriptándolas. Para ello se usa una mezcla de criptografía asimétrica con criptografía simétrica. La criptografía asimétrica es una idea genial y verás por qué si la comparas con la criptografía simétrica que es la que probablemente conozcas más.
Cifrado simétrico
Con la criptografía simétrica, alguien, llamémosle Alice, usa una “clave de encriptación” para encriptar un mensaje y pasárselo a Bob. Si Bob debe responder, encripta su mensaje usando la misma clave y Alice lo desencripta.
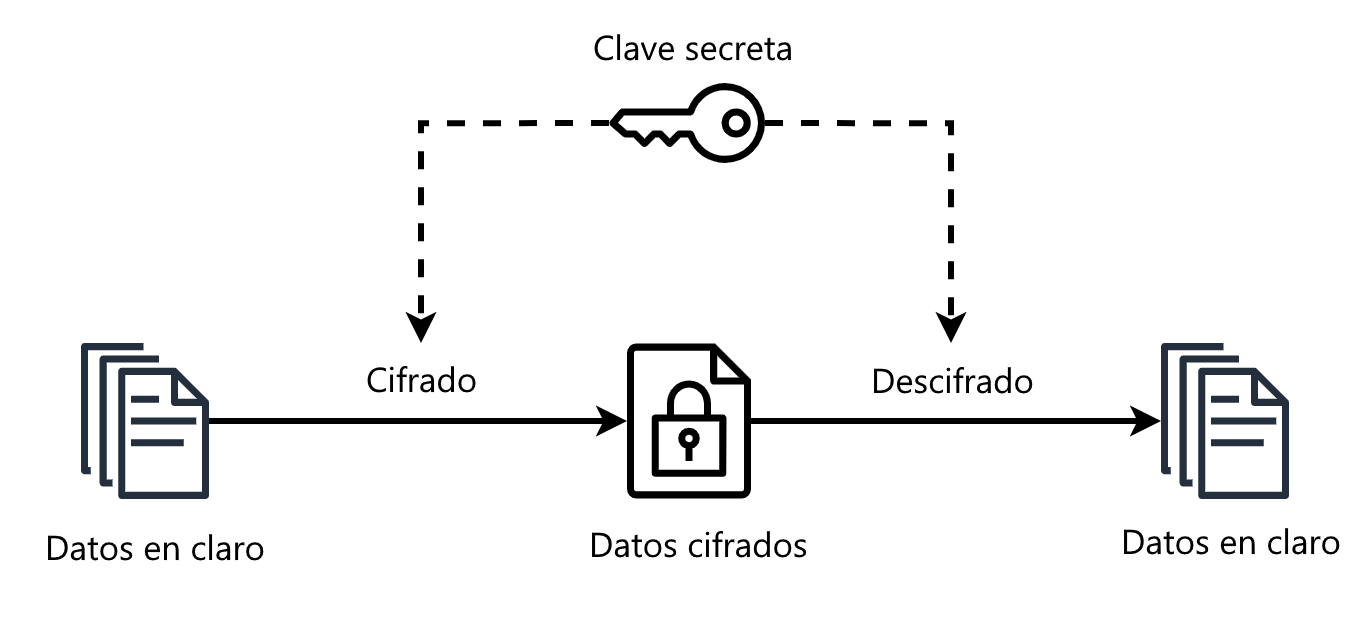
Asumiendo que el algoritmo de encriptación sea totalmente seguro, ese mecanismo de encriptación es tan seguro como… lo segura esté la clave de encriptación.
Y ese es el talón de Aquiles de la encriptación simétrica: de algún modo Alice debe hacerle llegar a Bob la clave de encriptación que ambos deben usar. Este proceso se conoce como “intercambio de clave” y es crítico: si alguien intercepta este mensaje en el cual Alice manda la clave, podrá descifrar todos los mensajes que Alice y Bob se envíen.
Y no solo eso: dado que el atacante conoce la clave de encriptación, puede desencriptar un mensaje de Alice modificarlo y mandárselo encriptado de nuevo a Bob. Este va a recibir datos alterados y ¡no tiene manera de enterarse!
Cifrado asimétrico o de clave pública
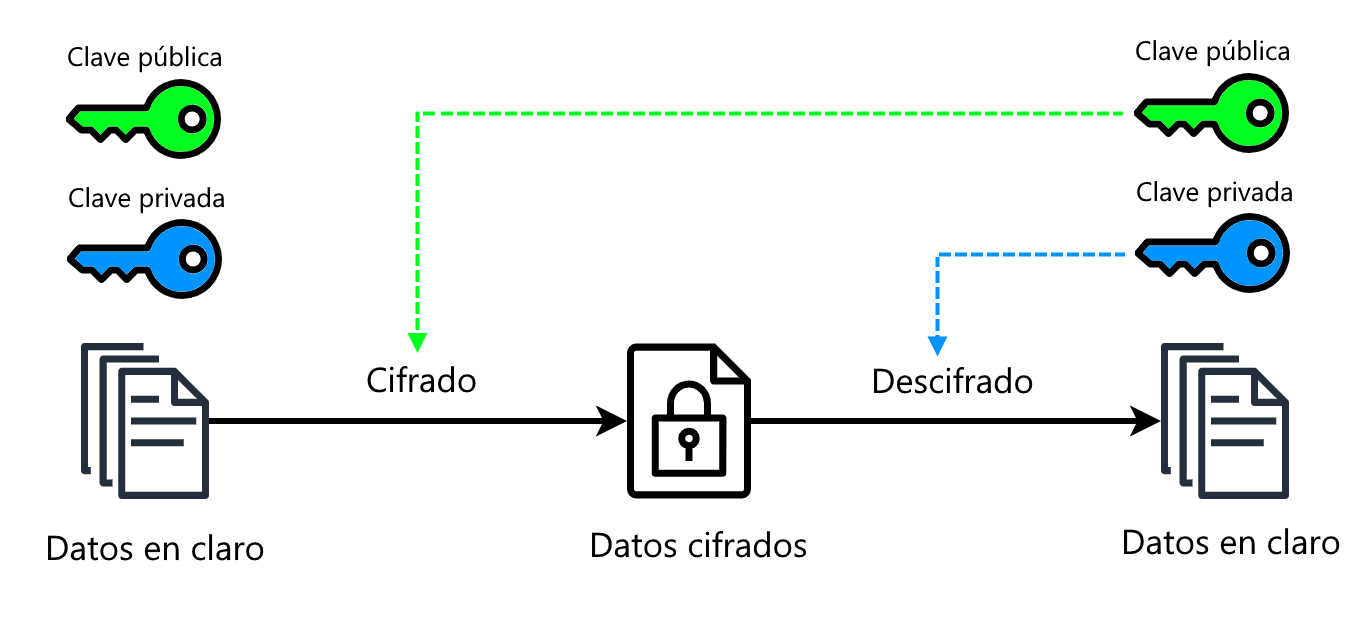
¿Cómo soluciona estos problemas la encriptación asimétrica? Pues en lugar de que Alice y Bob compartan una misma clave, cada uno de ellos tiene un par de claves, llamado par clave pública/clave privada. El par de llaves de Alice es suyo y es independiente del de Bob.
Y ahora viene la gracia: todo lo que se encripte con la clave pública de un par de claves, se puede desencriptar solo con clave privada del mismo par de claves. ¡Y al revés también! Todo lo que se encripte con la clave privada de un par se puede desencriptar solo con la clave pública del mismo.
Ahora la cuestión es como sigue: recuerda que Alice y Bob han generado cada uno su propio par de clave pública/clave privada, de forma independiente. Lo que ambos hacen es guardarse la clave privada en una caja fuerte y publicar la clave pública en algún lugar de acceso público. O sea, todo el mundo conoce las claves públicas de las demás, pero las privadas solo las conoce cada uno.
De este modo no existe intercambio de claves entre Alice y Bob: si Alice quiere mandarle un mensaje a Bob lo que hará será encriptar el mensaje con la clave pública de Bob y de este modo solo Bob lo podrá desencriptar (ya que solo él tiene su clave privada):
Y viceversa: cuando Bob conteste a Alice usará la clave pública de Alice para encriptar el mensaje y así solo Alice lo podrá desencriptar, ya que solo ella tiene su clave privada.
Pero, espera, que aún hay más: ¿recuerdas que eso también funcionaba a la inversa?: si encriptamos con la clave privada, podemos desencriptar con la pública. Eso nos trae un regalo llamado firma criptográfica o firma digital. Básicamente consiste en lo siguiente:
- Alice debe mandar un mensaje a Bob.
- Calcula un hash del mensaje y lo encripta con su propia clave privada.
- Luego encripta el mensaje y el hash encriptado (todo junto) con la clave pública de Bob.
- Bob recibe el mensaje y lo desencripta con su clave privada (que solo él tiene), obteniendo el mensaje desencriptado y un hash encriptado.
- Ahora, como sabe que el mensaje lo ha mandado Alice, usa la clave pública de Alice para desencriptar el hash.
- Bob calcula el hash del mensaje desencriptado y verifica que es el mismo que el hash que ha desencriptado en el punto anterior.
De esta manera, no solo tenemos una comunicación segura entre Alice y Bob, sino que también tenemos la seguridad de que el mensaje es de quien dice ser y no está alterado ya que:
- Si alguien se quiere hacer pasar por Alice (y mandarle mensajes falsos a Bob), no podrá firmarlos, ya que no posee la clave privada de Alice que es la que se necesita para firmar el mensaje.
- Incluso, si Bob es descuidado y su clave privada fuese robada, quien tuviese la clave privada de Bob podría leer todos sus mensajes (y ¡ojo! hacerse pasar por él), pero no podría alterar lo que se le manda al verdadero Bob.
Es decir, en criptografía asimétrica el tener una clave comprometida solo compromete la mitad de la comunicación y, además, debes tener presente que, a diferencia de la criptografía simétrica, las claves que se pueden comprometer nunca circulan por la red, ya que jamás se intercambian.
Intercambio de claves
Volvamos a TLS. Cuando se empieza una conexión HTTPS eso es someramente lo que ocurre:
- El navegador hace la petición e indica que quiere usar HTTPS.
- El servidor responde con su clave pública y un certificado que contiene datos adicionales (su nombre, qué dominio es, etc).
- El navegador usa la clave pública para encriptar un mensaje que contiene una clave de encriptación simétrica que ha generado el propio navegador en el momento.
- El servidor usa su clave privada para desencriptar el mensaje y obtener dicha clave de encriptación simétrica.
- A partir de ese punto la comunicación entre servidor y navegador se sucede usando solo la clave de encriptación simétrica.
Es decir, TLS usa encriptación asimétrica solo para intercambiar la clave de encriptación simétrica.
Nota: esto se debe a que el cifrado de clave pública es mucho más demandante de recursos que el simétrico. Por ello, se usa el primero para intercambiar la clave simétrica y el segundo para el resto de la comunicación.
Por lo tanto, para que un servidor pueda usar TLS debe tener instalado un certificado. Dichos certificados los conocemos como certificados X.509.
Infraestructura de clave pública
Ahora bien, cualquiera puede generar un par de claves y con ellas un certificado X.509 con los datos que quiera, y hacerse pasar por cualquier otro (recuerda que el certificado contiene datos de quién es el servidor, si es Google o Amazon, por ejemplo).
Por ello, necesitamos un mecanismo mediante el cual el cliente (navegador) pueda verificar que el certificado que le muestra el servidor es de confianza. Para ello, lo que se hace es que el certificado está firmado por otra clave privada. Esa otra clave privada pertenece a una “organización de confianza”, que conocemos bajo el nombre de CA (Certificate Authority) o Autoridad Certificadora.
La idea es que tú no puedas autogenerarte un certificado y ponerlo en tu servidor, sino que debes pasarles los datos a la CA para que valide su autenticidad. Esta te emitirá un certificado (firmado con su clave privada) que instalas en tu servidor y que los clientes podrán validar con la clave pública de esa CA.
OJO: por supuesto la CA para emitirte el certificado te pedirá que pruebes ser quien dices ser y que el dominio al que quieras vincular el certificado es tuyo. Vamos, yo no puedo ir a una CA y pedir un certificado para el dominio google.com.
Así, los clientes pueden verificar que este certificado está generado por “alguien de confianza” (la CA, en la que todos los navegadores confían por defecto) y asumir entonces que los datos del certificado son correctos.
No hay “una lista universal de CAs”, ni ninguna organización supragubernamental que otorgue “títulos” de CA. Cualquiera pueda montar su propia CA y firmar certificados. Lo difícil será que los clientes confíen en ti. Cada cliente (por ejemplo, Firefox o Chrome) viene con su propia lista de CAs en las que confía y solo admitirá certificados emitidos por esas CAs. Esa lista la mantienen los desarrolladores de esos clientes (Mozilla y Google en nuestro ejemplo) y está incrustada dentro del propio cliente. A las CAs de confianza las llamamos CA root.
Nota: se podría dar el caso de que Chrome aceptase un certificado de una CA en la que Firefox no confiase. En este caso, la página web la verías bien en Chrome, pero en Firefox te daría un error de certificado. Por supuesto, hay algunas grandes CA en las que confía todo el mundo, como pueden ser Let's Encrypt, GoDaddy, Symantec, Digicert o GeoTrust entre otras. Ya te puedes imaginar que hay un negocio alrededor de las CAs: obtener un certificado X.509 no suele ser gratis. Además esos certificados, por seguridad, caducan cada cierto tiempo y hay que renovarlos, generalmente volviendo a pasar por caja.
Por supuesto, si la clave privada de una CA de confianza se ve comprometida, esta se halla en una grave situación: probablemente los clientes se actualizarán para dejar “de confiar” en esa CA y, probablemente, deba cerrar el chiringuito.
Para proteger mejor su clave privada, las CA crean “cadenas de certificados”. Básicamente consiste en que una CA de confianza puede crear otras CAs (que NO son de confianza) conocidas como CA intermedias y usarlas para firmar los certificados que emiten. Luego, esos certificados tienen una referencia a otro certificado (certificado intermedio), que este sí que está firmado por la propia CA de confianza e indica que la CA root confía en la CA intermedia. De este modo, en lugar de existir N certificados (uno por cliente) firmados por la CA de confianza, solo hay uno (el certificado intermedio, que es igual para todo el mundo) y los clientes obtienen un certificado firmado por la CA intermedia. De ese modo, la clave privada se protege mejor contra posibles ataques. Cuando el cliente recibe un certificado firmado por la CA intermedia, en principio, no confía en este certificado, pero como tiene una referencia a otro certificado firmado por una CA en la que sí confía, puede suponer que el certificado de la CA intermedia es de confianza.
Por supuesto, este modelo se puede extender a X niveles de CA intermedias donde cada una referencia el certificado de la anterior. A esta infraestructura de CAs, certificándose unas a otras y delegando confianza, se le conoce como PKI (Public Key Infrastructure) o Infraestructura de Clave Pública.
IMPORTANTE: te comento eso, no solo por cultura general, sino porque cuando instalas el certificado X.509 en tu servidor, debes instalar toda la cadena de certificados, es decir, debes instalar el certificado final y todos los certificados de todas las CAs intermedias que participen en el proceso.
Existe una entidad certificadora de confianza llamada Let's Encrypt (LE), que actúa como entidad sin fines de lucro que emite certificados X.509 de forma completamente gratuita. Usar LE no es tan sencillo como pedir un certificado a cualquier de las otras CAs, porque funcionan de forma totalmente automatizada por lo que hay que usar procesos específicos que sigan determinados protocolos. Además, la visión de LE es que los certificados X.509 deberían tener una duración corta (cuanto menos tiempo es válido un certificado, menor es el impacto en caso de que se vea comprometido, ya que será válido menos tiempo). Así, frente al típico año de duración de un certificado X.509 estándar, los certificados de LE duran un máximo de 90 días. Pero, como ellos mismos indican, tienen la intención de, en un futuro, llegar a ofrecer certificados X.509 con tiempos de validez incluso menores, que no debería ser especialmente problemático ya que todo el proceso está automatizado. Por su forma de funcionar, para usar LE hay que tener una buena cultura de DevOps y procesos automatizados para la gestión y renovación de certificados. Existen herramientas que te permiten integrar LE en tus ingress de Kubernetes de manera sencilla.
Habilitar TLS en Ingress
Vale, ahora que ya tienes los fundamentos básicos de TLS podemos pasar a ver cómo habilitar ingress para TLS. Para ello necesitas dos pasos:
- Modificar el recurso ingress para que soporte TLS.
- Tener en el clúster un secreto con la cadena de certificados.
La configuración de TLS en el recurso ingress se establece en la sección spec.tls:
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: nginx.ingress.kubernetes.io/rewrite-target: /$2 nginx.ingress.kubernetes.io/ssl-redirect: "false" labels: app: tt-webbff name: tailwindtraders-webbff-tt-webbff namespace: default spec: ingressClassName: nginx rules: - host: backend.tailwindtraders.com http: paths: - backend: service: name: webbff port: name: http path: /webbff(/|$)(.*) pathType: ImplementationSpecific tls: - hosts: - backend.tailwindtraders.com secretName: tt-tls-custom
Observa la sección spec.tls. Contiene un array de objetos donde cada objeto tiene:
- Otro array (
hosts) en el cual se colocan todos los dominios que se protegen bajo TLS - El nombre del secreto de Kubernetes que contiene la cadena de certificados
El motivo de usar arrays de hosts separados para la lista de hosts virtuales y de TLS es, básicamente, en que hay escenarios en que un mismo secreto (certificado) puede servir a varios dominios. Eso se da si tienes certificados “wilcard” o con soporte para SAN.
En este ejemplo (sacado de un ejemplo real), el secreto que contiene la cadena de certificados es el secreto tt-tls-custom, que existe en el clúster:
Si observas el tipo (TYPE) del secreto verás que es de tipo kubernetes.io/tls, es decir, que el clúster sabe que ese secreto contiene un certificado (o una cadena de certificados). Eso es, porque ese secreto tiene un formato específico:
apiVersion: v1 data: tls.crt: [[Cadena en BASE64 con el contenido del certificado con la clave pública]] tls.key: [[Cadena en BASE64 con el contenido de la clave privada]] kind: Secret metadata: name: tt-tls-custom namespace: default type: kubernetes.io/tls
Puedes usar una especificación YAML como esa o bien kubectl:
kubectl create secret tls <nombre-secreto> --key <fichero-clave-privada> --cert <fichero-certificado>
¡Y listos! Ya tienes el certificado TLS configurado para tu clúster.
El controlador ingress-nginx (que es el que hemos estado usando) viene de serie con un certificado TLS incorporado y tus recursos ingress usarán este certificado si no especificas otro (en spec.tls). Eso sirve para poco más que para pruebas, ya que este certificado no es de confianza, pero si configuras tu máquina para que confíe en él, ya tienes https configurado en local de forma automática. La captura siguiente muestra un ejemplo de una llamada https a un recurso ingress:

Puedes ver que me da error de certificado, ya que mi máquina no confía en el certificado Kubernetes Ingress Controller Fake Certificate.
Cómo obtener los ficheros de clave pública y de clave privada
Eso ya depende un poco de tus preferencias, pero voy a imaginar el caso más habitual que es en el que has pedido un certificado X.509 a una Autoridad Certificadora (CA) comercial y te lo has descargado. Este certificado puede venir en varios formatos. Lo que necesitas es:
- Obtener el fichero de certificado en formato PEM (generalmente ficheros con extensión
.crto.cert, aunque no tiene por qué). - Obtener el fichero de clave privada en formato
.keyen formato PEM.
El formato PEM (las siglas significan (Privacy Enhanced Mail), es el formato más común para certificados y claves públicas. Es un formato ASCII, donde se usa una cabecera de texto plano (de tipo -----BEGIN CERTIFICATE-----) junto con una secuencia BASE64.
Es posible que el certificado te lo den en formato PKCS#12 (los ficheros de extensión .pfx o p12) que es un contenedor que contiene ambas cosas a la vez. Puedes usar los siguientes comandos (Linux, MacOS o WSL2) para pasar de un PKCS #12 a un par de ficheros PEM (para el certificado y la clave privada):
# Extraer la clave encriptada del pfx openssl pkcs12 -in certfile.pfx -nocerts -out keyfile-encrypted.key # Desencriptar la clave privada openssl rsa -in keyfile-encrypted.key -out keyfile.key # Extraer el certificado del pfx openssl pkcs12 -in certfile.pfx -clcerts -nokeys -out certfile.crt
Esos comandos funcionan también si instalas OpenSSL para Windows
Si tienes otros formatos (por ejemplo, DER) deberás consultar la documentación. Son formatos estándar y seguro que encontrarás cómo realizar la transformación. De todos modos en ese artículo tienes un poco más de información.
Resumen del módulo
¡Uf! Este ha sido un módulo largo y quizás un pelín denso. Pero ahora ya sabes cómo exponer tus aplicaciones al exterior del clúster. Has aprendido la diferencia entre servicios ClusterIP, NodePort y LoadBalancer y cuándo usar cada uno de ellos.
Finalmente hemos visto los inconvenientes de usar NodePort y/o LoadBalancer para exponer nuestras aplicaciones al exterior y cómo ingress nos puede ayudar.
Recuerda: ingress es solo HTTP/HTTPS
Es importante que tengas presente que ingress sólo expone HTTP/HTTPS al exterior. Si debes exponer cualquier otro protocolo (por ejemplo, si quieres exponer un Redis o un PostgreSQL o cualquier servicio no HTTP/HTTPS) entonces deberás hacerlo usando un servicio LoadBalancer o NodePort.
Existe una API que está en desarrollo llamada Gateway API que va a expandir ingress para que soporte todo tipo de protocolos y escenarios nuevos que por ahora no son posibles de forma directa. Esta API está actualmente en beta y su uso abarca escenarios complejos que quedan fuera del alcance de este curso.